



Adhiraj Ghosh
@adhirajghosh.bsky.social
ELLIS PhD, University of Tübingen | Data-centric Vision and Language @bethgelab.bsky.social
Website: adhirajghosh.github.io
Twitter: https://x.com/adhiraj_ghosh98
Website: adhirajghosh.github.io
Twitter: https://x.com/adhiraj_ghosh98
Pinned
Adhiraj Ghosh
@adhirajghosh.bsky.social
· Jul 27

Excited to be in Vienna for #ACL2025 🇦🇹!You'll find @dziadzio.bsky.social and I by our ONEBench poster, so do drop by!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!
Excited to be in Vienna for #ACL2025 🇦🇹!You'll find @dziadzio.bsky.social and I by our ONEBench poster, so do drop by!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!
July 27, 2025 at 10:26 PM
Excited to be in Vienna for #ACL2025 🇦🇹!You'll find @dziadzio.bsky.social and I by our ONEBench poster, so do drop by!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!
Stumbled upon this blogpost recently and found some very useful tips to improve the Bluesky experience. This seemed almost tailored to me - I don't live in the USA and the politics there don't affect me personally. Settings -> Moderation -> Muted Words & Tags cleaned up my feed - strongly recommend!

I wrote something up for AI people who want to get into bluesky and either couldn't assemble an exciting feed or gave up doomscrolling when their Following feed switched to talking politics 24/7.

The AI Researcher's Guide to a Non-Boring Bluesky Feed | Naomi Saphra
How to migrate to bsky without a boring feed.
nsaphra.net
June 25, 2025 at 4:14 PM
Stumbled upon this blogpost recently and found some very useful tips to improve the Bluesky experience. This seemed almost tailored to me - I don't live in the USA and the politics there don't affect me personally. Settings -> Moderation -> Muted Words & Tags cleaned up my feed - strongly recommend!
Reposted by Adhiraj Ghosh

Why More Researchers Should be Content Creators
Just trying something new! I recorded one of my recent talks, sharing what I learned from starting as a small content creator.
youtu.be/0W_7tJtGcMI
We all benefit when there are more content creators!
Just trying something new! I recorded one of my recent talks, sharing what I learned from starting as a small content creator.
youtu.be/0W_7tJtGcMI
We all benefit when there are more content creators!

June 24, 2025 at 9:58 PM
Why More Researchers Should be Content Creators
Just trying something new! I recorded one of my recent talks, sharing what I learned from starting as a small content creator.
youtu.be/0W_7tJtGcMI
We all benefit when there are more content creators!
Just trying something new! I recorded one of my recent talks, sharing what I learned from starting as a small content creator.
youtu.be/0W_7tJtGcMI
We all benefit when there are more content creators!

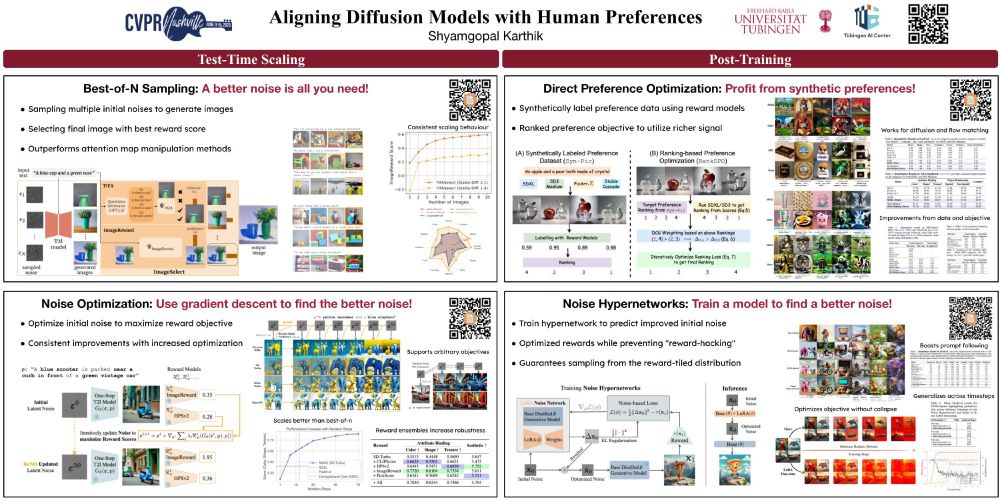


🏆ONEBench accepted to ACL main! ✨
Stay tuned for the official leaderboard and real-time personalised benchmarking release!
If you’re attending ACL or are generally interested in the future of foundation model benchmarking, happy to talk!
#ACL2025NLP #ACL2025
@aclmeeting.bsky.social
Stay tuned for the official leaderboard and real-time personalised benchmarking release!
If you’re attending ACL or are generally interested in the future of foundation model benchmarking, happy to talk!
#ACL2025NLP #ACL2025
@aclmeeting.bsky.social
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745

May 17, 2025 at 7:53 PM
🏆ONEBench accepted to ACL main! ✨
Stay tuned for the official leaderboard and real-time personalised benchmarking release!
If you’re attending ACL or are generally interested in the future of foundation model benchmarking, happy to talk!
#ACL2025NLP #ACL2025
@aclmeeting.bsky.social
Stay tuned for the official leaderboard and real-time personalised benchmarking release!
If you’re attending ACL or are generally interested in the future of foundation model benchmarking, happy to talk!
#ACL2025NLP #ACL2025
@aclmeeting.bsky.social
Reposted by Adhiraj Ghosh

🧠 Keeping LLMs factually up to date is a common motivation for knowledge editing.
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇

April 8, 2025 at 3:32 PM
🧠 Keeping LLMs factually up to date is a common motivation for knowledge editing.
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇
Reposted by Adhiraj Ghosh

Check out our newest paper!
As always, it was super fun working on this with @prasannamayil.bsky.social
As always, it was super fun working on this with @prasannamayil.bsky.social

New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
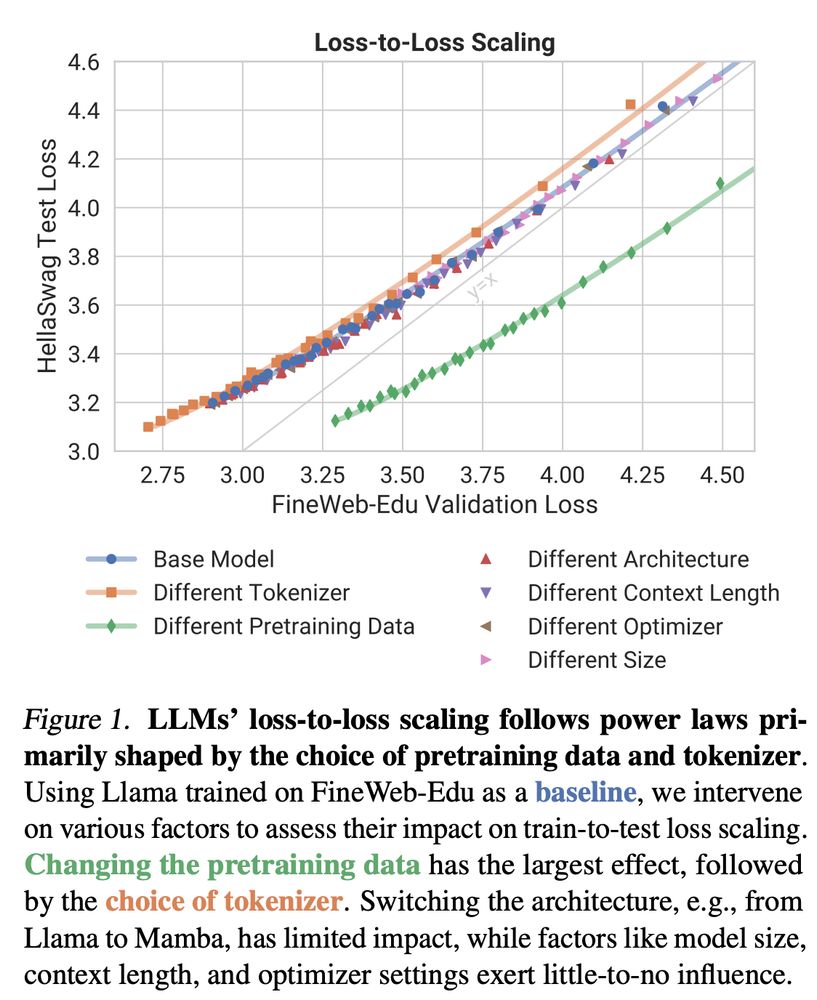
February 18, 2025 at 2:12 PM
Check out our newest paper!
As always, it was super fun working on this with @prasannamayil.bsky.social
As always, it was super fun working on this with @prasannamayil.bsky.social
Reposted by Adhiraj Ghosh

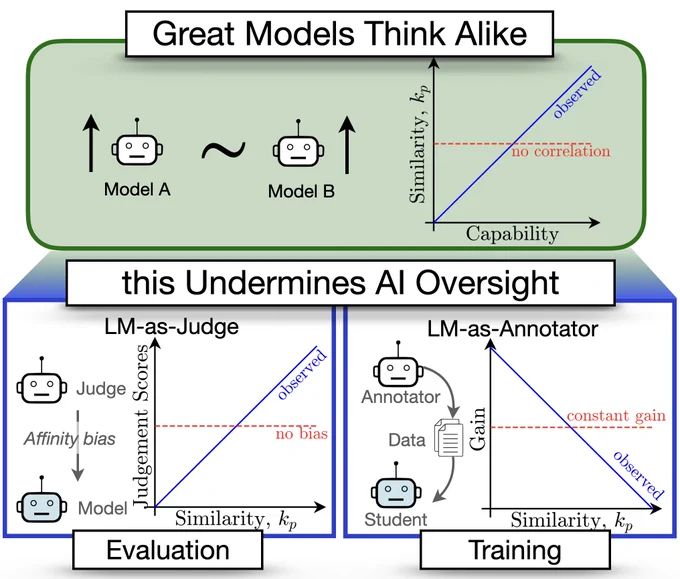
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
February 7, 2025 at 9:12 PM
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
Godsend

I started a blog! First post is everything I know about setting up (fast, reproducible, error-proof) Python project environments using the latest tools. These methods have saved me a lot of grief. Also a short guide to CUDA in appendix :)
blog.apoorvkh.com/posts/projec...
blog.apoorvkh.com/posts/projec...
Managing Project Dependencies
blog.apoorvkh.com
February 7, 2025 at 4:38 PM
Godsend
Reposted by Adhiraj Ghosh

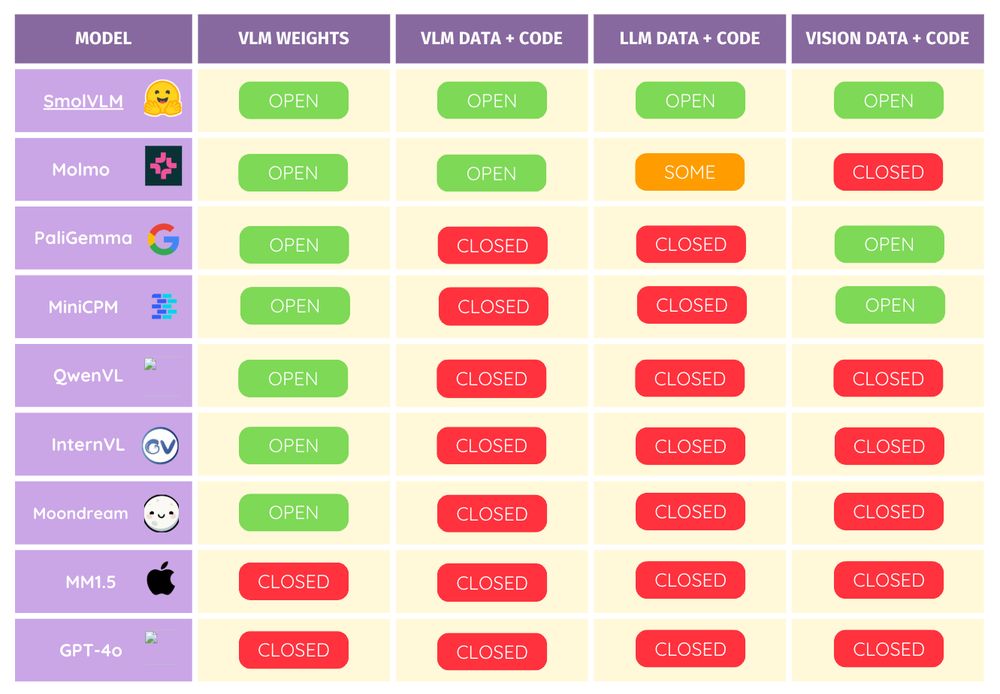
Fuck it, today we're open-sourcing the codebase used to train SmolVLM from scratch on 256 H100s 🔥
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
January 31, 2025 at 3:06 PM
Fuck it, today we're open-sourcing the codebase used to train SmolVLM from scratch on 256 H100s 🔥
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
Reposted by Adhiraj Ghosh

NLI Improves Compositionality in Vision-Language Models is accepted to #ICLR2025!
CECE enables interpretability and achieves significant improvements in hard compositional benchmarks without fine-tuning (e.g., Winoground, EqBen) and alignment (e.g., DrawBench, EditBench). + info: cece-vlm.github.io
CECE enables interpretability and achieves significant improvements in hard compositional benchmarks without fine-tuning (e.g., Winoground, EqBen) and alignment (e.g., DrawBench, EditBench). + info: cece-vlm.github.io
January 23, 2025 at 6:34 PM
NLI Improves Compositionality in Vision-Language Models is accepted to #ICLR2025!
CECE enables interpretability and achieves significant improvements in hard compositional benchmarks without fine-tuning (e.g., Winoground, EqBen) and alignment (e.g., DrawBench, EditBench). + info: cece-vlm.github.io
CECE enables interpretability and achieves significant improvements in hard compositional benchmarks without fine-tuning (e.g., Winoground, EqBen) and alignment (e.g., DrawBench, EditBench). + info: cece-vlm.github.io
Reposted by Adhiraj Ghosh

📄 New Paper: "How to Merge Your Multimodal Models Over Time?"
arxiv.org/abs/2412.06712
Model merging assumes all finetuned models are available at once. But what if they need to be created over time?
We study Temporal Model Merging through the TIME framework to find out!
🧵
arxiv.org/abs/2412.06712
Model merging assumes all finetuned models are available at once. But what if they need to be created over time?
We study Temporal Model Merging through the TIME framework to find out!
🧵

How to Merge Your Multimodal Models Over Time?
Model merging combines multiple expert models - finetuned from a base foundation model on diverse tasks and domains - into a single, more capable model. However, most existing model merging approaches...
arxiv.org
December 11, 2024 at 6:00 PM
📄 New Paper: "How to Merge Your Multimodal Models Over Time?"
arxiv.org/abs/2412.06712
Model merging assumes all finetuned models are available at once. But what if they need to be created over time?
We study Temporal Model Merging through the TIME framework to find out!
🧵
arxiv.org/abs/2412.06712
Model merging assumes all finetuned models are available at once. But what if they need to be created over time?
We study Temporal Model Merging through the TIME framework to find out!
🧵
Reposted by Adhiraj Ghosh
How do we benchmark the vast capabilities of foundation models? Introducing ONEBench – a unifying benchmark to test them all, led by
@adhirajghosh.bsky.social and
@dziadzio.bsky.social!⬇️
Sample-level benchmarks could be the new generation- reusable, recombinable & evaluate lots of capabilities!
@adhirajghosh.bsky.social and
@dziadzio.bsky.social!⬇️
Sample-level benchmarks could be the new generation- reusable, recombinable & evaluate lots of capabilities!
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
December 10, 2024 at 6:39 PM
How do we benchmark the vast capabilities of foundation models? Introducing ONEBench – a unifying benchmark to test them all, led by
@adhirajghosh.bsky.social and
@dziadzio.bsky.social!⬇️
Sample-level benchmarks could be the new generation- reusable, recombinable & evaluate lots of capabilities!
@adhirajghosh.bsky.social and
@dziadzio.bsky.social!⬇️
Sample-level benchmarks could be the new generation- reusable, recombinable & evaluate lots of capabilities!
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
December 10, 2024 at 5:44 PM
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Reposted by Adhiraj Ghosh

🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇

December 2, 2024 at 5:59 PM
🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
Excited to test it out, could be a blessing for large-scale projects!
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 26, 2024 at 4:59 PM
Excited to test it out, could be a blessing for large-scale projects!
I've found starter packs on NLP, vision, graphics, etc. But personally, I would love to know and hear from researchers working on vision-language. So, let me know if you'd like to join this starter pack, would be happy to add!
go.bsky.app/TENRRBb
go.bsky.app/TENRRBb
November 19, 2024 at 9:56 PM
I've found starter packs on NLP, vision, graphics, etc. But personally, I would love to know and hear from researchers working on vision-language. So, let me know if you'd like to join this starter pack, would be happy to add!
go.bsky.app/TENRRBb
go.bsky.app/TENRRBb