



Joschka Strüber @ICML2025 🇨🇦
@joschkastrueber.bsky.social
PhD student at the University of Tübingen, member of @bethgelab.bsky.social
Pinned
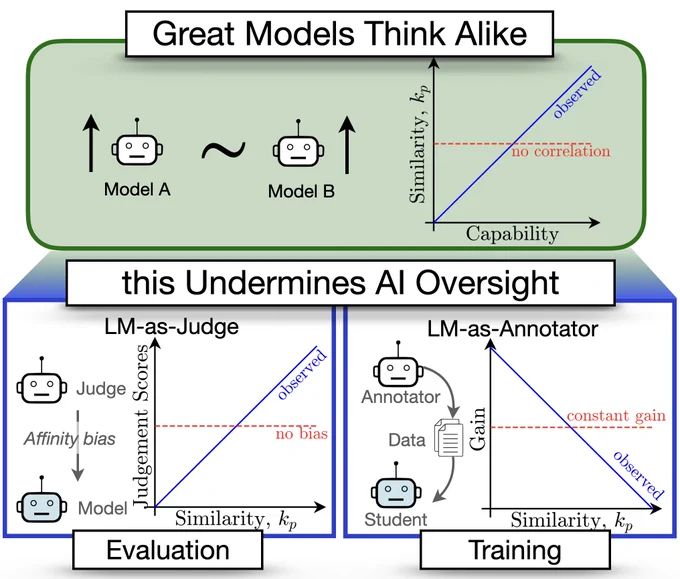
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
Reposted by Joschka Strüber @ICML2025 🇨🇦

🚨 New paper alert! 🚨
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)

March 14, 2025 at 9:41 AM
🚨 New paper alert! 🚨
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)
Reposted by Joschka Strüber @ICML2025 🇨🇦

AI can generate correct-seeming hypotheses (and papers!). Brandolini's law states BS is harder to refute than generate. Can LMs falsify incorrect solutions? o3-mini (high) scores just 9% on our new benchmark REFUTE. Verification is not necessarily easier than generation 🧵

February 28, 2025 at 6:13 PM
AI can generate correct-seeming hypotheses (and papers!). Brandolini's law states BS is harder to refute than generate. Can LMs falsify incorrect solutions? o3-mini (high) scores just 9% on our new benchmark REFUTE. Verification is not necessarily easier than generation 🧵
Reposted by Joschka Strüber @ICML2025 🇨🇦

New preprint out! 🎉
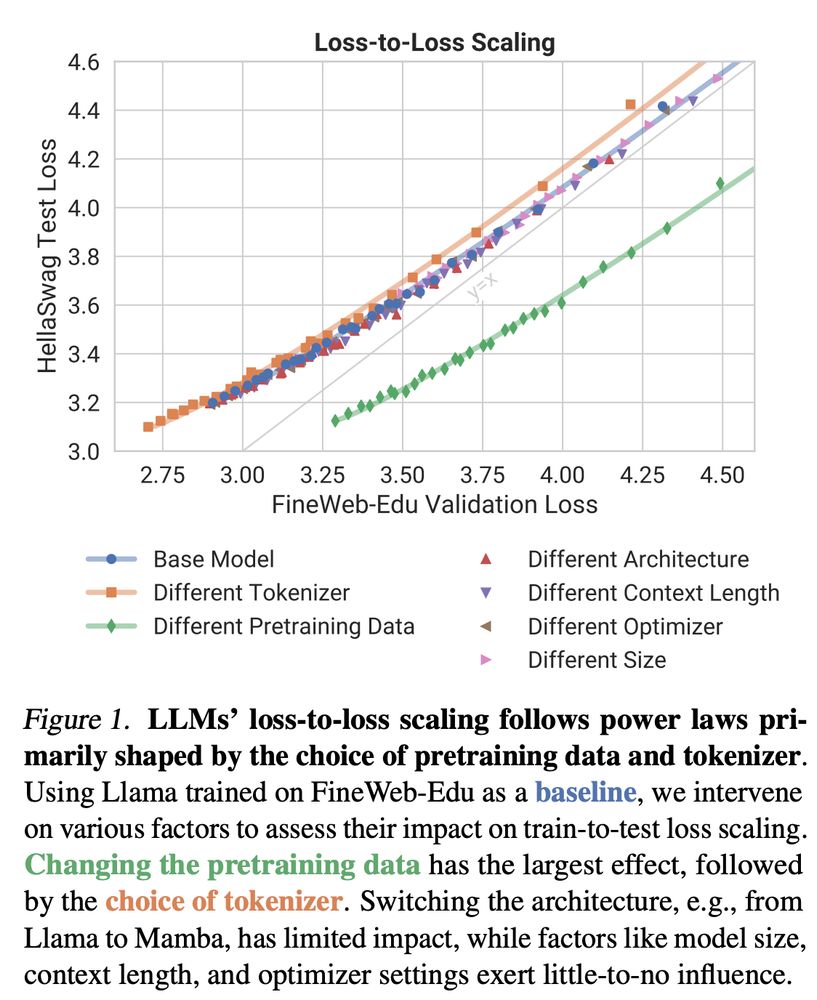
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
February 18, 2025 at 2:09 PM
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
Reposted by Joschka Strüber @ICML2025 🇨🇦

CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
February 17, 2025 at 6:22 PM
CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Reposted by Joschka Strüber @ICML2025 🇨🇦

🚀 We’re hiring! Join Bernhard Schölkopf & me at @ellisinsttue.bsky.social to push the frontier of #AI in education!
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...

February 11, 2025 at 4:34 PM
🚀 We’re hiring! Join Bernhard Schölkopf & me at @ellisinsttue.bsky.social to push the frontier of #AI in education!
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
February 7, 2025 at 9:12 PM
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇