



Joschka Strüber @ICML2025 🇨🇦
@joschkastrueber.bsky.social
PhD student at the University of Tübingen, member of @bethgelab.bsky.social
Hi Sebastian, can you please add me to the starter pack? Thank you and have a great weekend!
February 8, 2025 at 12:32 AM
Hi Sebastian, can you please add me to the starter pack? Thank you and have a great weekend!
Paper📜: arxiv.org/abs/2502.04313
Webpage🌐: model-similarity.github.io
Code🧑💻: github.com/model-simila...
Data📂: huggingface.co/datasets/bet...
Joint work with Shashwat Goel, Ilze Auzina, Karuna Chandra, @bayesiankitten.bsky.social @pkprofgiri.bsky.social, Douwe Kiela,
MatthiasBethge and Jonas Geiping
Webpage🌐: model-similarity.github.io
Code🧑💻: github.com/model-simila...
Data📂: huggingface.co/datasets/bet...
Joint work with Shashwat Goel, Ilze Auzina, Karuna Chandra, @bayesiankitten.bsky.social @pkprofgiri.bsky.social, Douwe Kiela,
MatthiasBethge and Jonas Geiping

February 7, 2025 at 9:12 PM
Paper📜: arxiv.org/abs/2502.04313
Webpage🌐: model-similarity.github.io
Code🧑💻: github.com/model-simila...
Data📂: huggingface.co/datasets/bet...
Joint work with Shashwat Goel, Ilze Auzina, Karuna Chandra, @bayesiankitten.bsky.social @pkprofgiri.bsky.social, Douwe Kiela,
MatthiasBethge and Jonas Geiping
Webpage🌐: model-similarity.github.io
Code🧑💻: github.com/model-simila...
Data📂: huggingface.co/datasets/bet...
Joint work with Shashwat Goel, Ilze Auzina, Karuna Chandra, @bayesiankitten.bsky.social @pkprofgiri.bsky.social, Douwe Kiela,
MatthiasBethge and Jonas Geiping
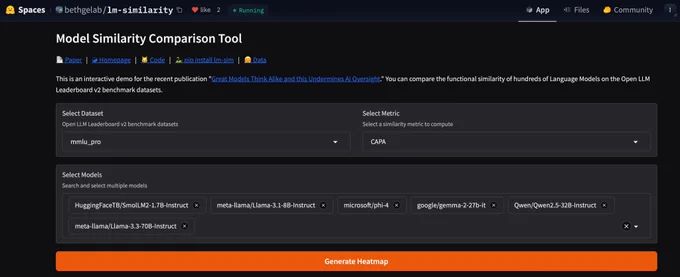
Sounds interesting? Play with model similarity metrics on our @huggingface
space huggingface.co/spaces/bethg..., thanks to sample-level predictions on OpenLLMLeaderboard. Or run pip install lm-sim, we welcome open-source contributions!
space huggingface.co/spaces/bethg..., thanks to sample-level predictions on OpenLLMLeaderboard. Or run pip install lm-sim, we welcome open-source contributions!
February 7, 2025 at 9:12 PM
Sounds interesting? Play with model similarity metrics on our @huggingface
space huggingface.co/spaces/bethg..., thanks to sample-level predictions on OpenLLMLeaderboard. Or run pip install lm-sim, we welcome open-source contributions!
space huggingface.co/spaces/bethg..., thanks to sample-level predictions on OpenLLMLeaderboard. Or run pip install lm-sim, we welcome open-source contributions!
Similarity offers a different (ha!) perspective to compare LMs, that we think should be more popular. Can we measure free-text reasoning similarity? How correlated are our research bets? Implications for multi-agent systems? These are just some questions we need more research on!
February 7, 2025 at 9:12 PM
Similarity offers a different (ha!) perspective to compare LMs, that we think should be more popular. Can we measure free-text reasoning similarity? How correlated are our research bets? Implications for multi-agent systems? These are just some questions we need more research on!
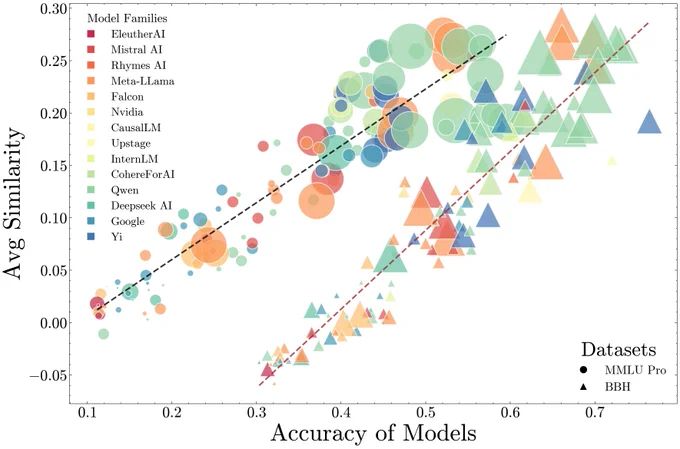
We will defer more to AI oversight for both evaluation and training as capabilities increase. Concerningly, more capable models are making more similar mistakes📈🙀
Appendix: Slightly steeper slope for instruct models, and switching architecture to Mamba doesnt reduce similarity!
Appendix: Slightly steeper slope for instruct models, and switching architecture to Mamba doesnt reduce similarity!
February 7, 2025 at 9:12 PM
We will defer more to AI oversight for both evaluation and training as capabilities increase. Concerningly, more capable models are making more similar mistakes📈🙀
Appendix: Slightly steeper slope for instruct models, and switching architecture to Mamba doesnt reduce similarity!
Appendix: Slightly steeper slope for instruct models, and switching architecture to Mamba doesnt reduce similarity!
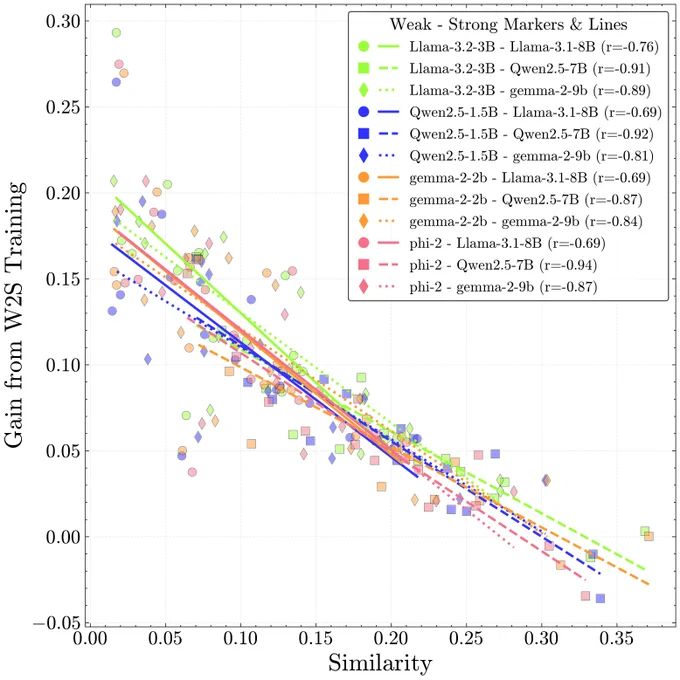
For Training on AI Annotations: We find complementary knowledge (lower similarity) predicts weak-to-strong generalization, i.e. gains from training on a smaller expert model's annotations. The performance ceiling is beyond what was previously understood from elicitation.☯️
February 7, 2025 at 9:12 PM
For Training on AI Annotations: We find complementary knowledge (lower similarity) predicts weak-to-strong generalization, i.e. gains from training on a smaller expert model's annotations. The performance ceiling is beyond what was previously understood from elicitation.☯️
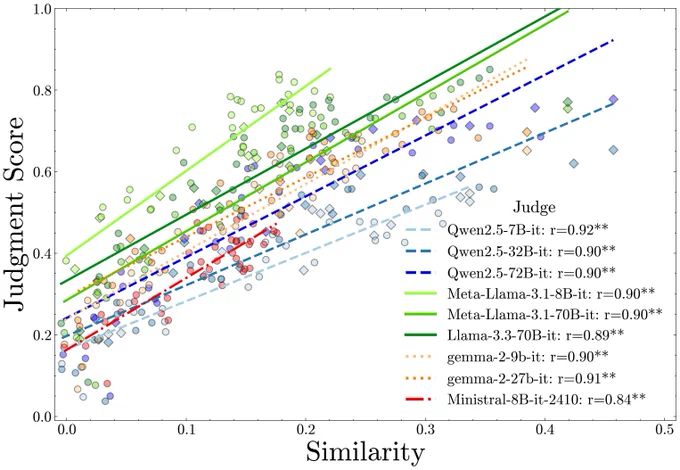
For AI Evaluators: We find LM judges favor more similar models, generalizing recent self-preference results. We used partial correlation and multiple regression tests to control for capability. Bias is worse for smaller judges, but effects persist in the largest/best ones too!🤥
February 7, 2025 at 9:12 PM
For AI Evaluators: We find LM judges favor more similar models, generalizing recent self-preference results. We used partial correlation and multiple regression tests to control for capability. Bias is worse for smaller judges, but effects persist in the largest/best ones too!🤥
First, how to measure model similarity?
💡Similar models make similar mistakes.
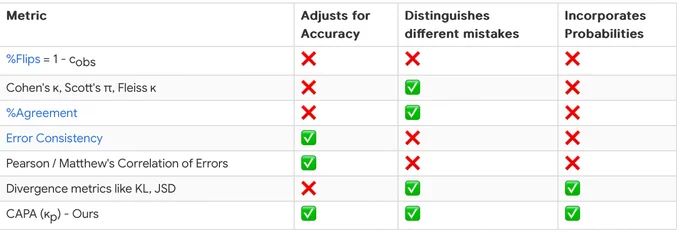
❗Two 90% accuracy models have lesser scope to disagree than two 50% models. We adjust for chance agreement due to accuracy.
Taking this into account, we propose a new metric, Chance Adjusted Probabilistic Agreement (CAPA)
💡Similar models make similar mistakes.
❗Two 90% accuracy models have lesser scope to disagree than two 50% models. We adjust for chance agreement due to accuracy.
Taking this into account, we propose a new metric, Chance Adjusted Probabilistic Agreement (CAPA)
February 7, 2025 at 9:12 PM
First, how to measure model similarity?
💡Similar models make similar mistakes.
❗Two 90% accuracy models have lesser scope to disagree than two 50% models. We adjust for chance agreement due to accuracy.
Taking this into account, we propose a new metric, Chance Adjusted Probabilistic Agreement (CAPA)
💡Similar models make similar mistakes.
❗Two 90% accuracy models have lesser scope to disagree than two 50% models. We adjust for chance agreement due to accuracy.
Taking this into account, we propose a new metric, Chance Adjusted Probabilistic Agreement (CAPA)