



Prasanna Mayilvahanan
@prasannamayil.bsky.social
PhD student in ML at MPI-IS. Prev Apple.
Interested in robustness at scale and reasoning.
Interested in robustness at scale and reasoning.
Reposted by Prasanna Mayilvahanan

CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
February 17, 2025 at 6:22 PM
CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
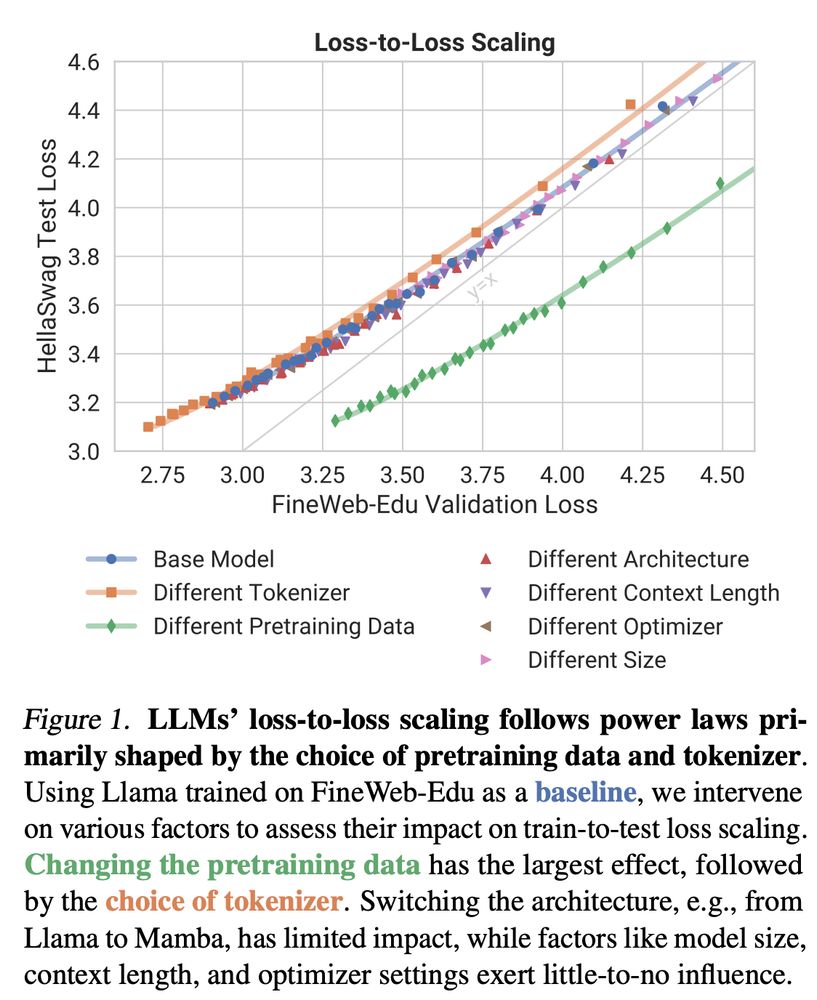
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
February 18, 2025 at 2:09 PM
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8