




Andreas Hochlehnert
@ahochlehnert.bsky.social
PhD student in ML at Tübingen AI Center & International Max-Planck Research School for Intelligent Systems
Pinned
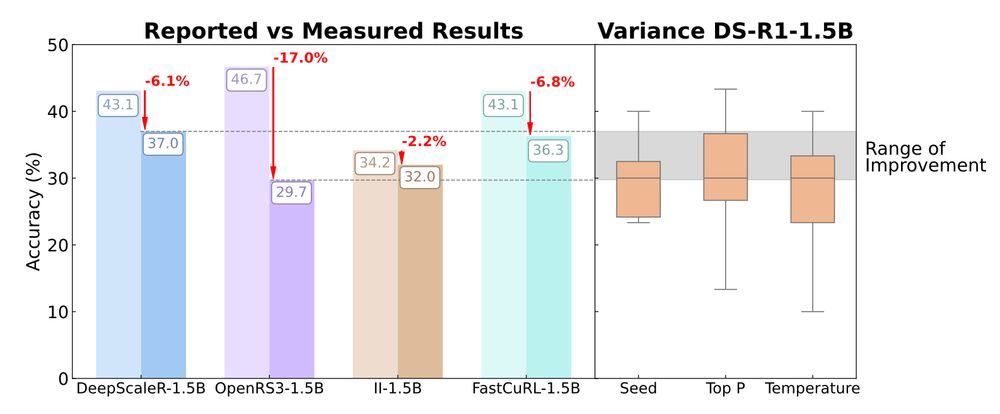
🧵1/ 🚨 New paper: A Sober Look at Progress in Language Model Reasoning
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
Presenting A Sober Look at Progress in LM Reasoning at @colmweb.org today 🇨🇦 #COLM2025
📅 Today
🕔 11:00 AM – 1:00 PM
📍 Room 710 - Poster #31
We find that many “reasoning” gains fall within variance and show how to make evaluation reproducible again.
📘 bethgelab.github.io/sober-reasoning
📅 Today
🕔 11:00 AM – 1:00 PM
📍 Room 710 - Poster #31
We find that many “reasoning” gains fall within variance and show how to make evaluation reproducible again.
📘 bethgelab.github.io/sober-reasoning
October 8, 2025 at 12:37 PM
Presenting A Sober Look at Progress in LM Reasoning at @colmweb.org today 🇨🇦 #COLM2025
📅 Today
🕔 11:00 AM – 1:00 PM
📍 Room 710 - Poster #31
We find that many “reasoning” gains fall within variance and show how to make evaluation reproducible again.
📘 bethgelab.github.io/sober-reasoning
📅 Today
🕔 11:00 AM – 1:00 PM
📍 Room 710 - Poster #31
We find that many “reasoning” gains fall within variance and show how to make evaluation reproducible again.
📘 bethgelab.github.io/sober-reasoning
Reposted by Andreas Hochlehnert

Excited about this new work from @haoyuhe.bsky.social. TLDR: Diffusion language models treat learning and inference differently which lowers performance. RL can be used to overcome this issue for certain problems.

🚀 Introducing our new paper, MDPO: Overcoming the Training-Inference Divide of Masked Diffusion Language Models.
📄 Paper: www.scholar-inbox.com/papers/He202...
arxiv.org/pdf/2508.13148
💻 Code: github.com/autonomousvi...
🌐 Project Page: cli212.github.io/MDPO/
📄 Paper: www.scholar-inbox.com/papers/He202...
arxiv.org/pdf/2508.13148
💻 Code: github.com/autonomousvi...
🌐 Project Page: cli212.github.io/MDPO/
August 20, 2025 at 8:25 PM
Excited about this new work from @haoyuhe.bsky.social. TLDR: Diffusion language models treat learning and inference differently which lowers performance. RL can be used to overcome this issue for certain problems.
🧵1/ 🚨 New paper: A Sober Look at Progress in Language Model Reasoning
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
April 10, 2025 at 3:36 PM
🧵1/ 🚨 New paper: A Sober Look at Progress in Language Model Reasoning
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
Reposted by Andreas Hochlehnert

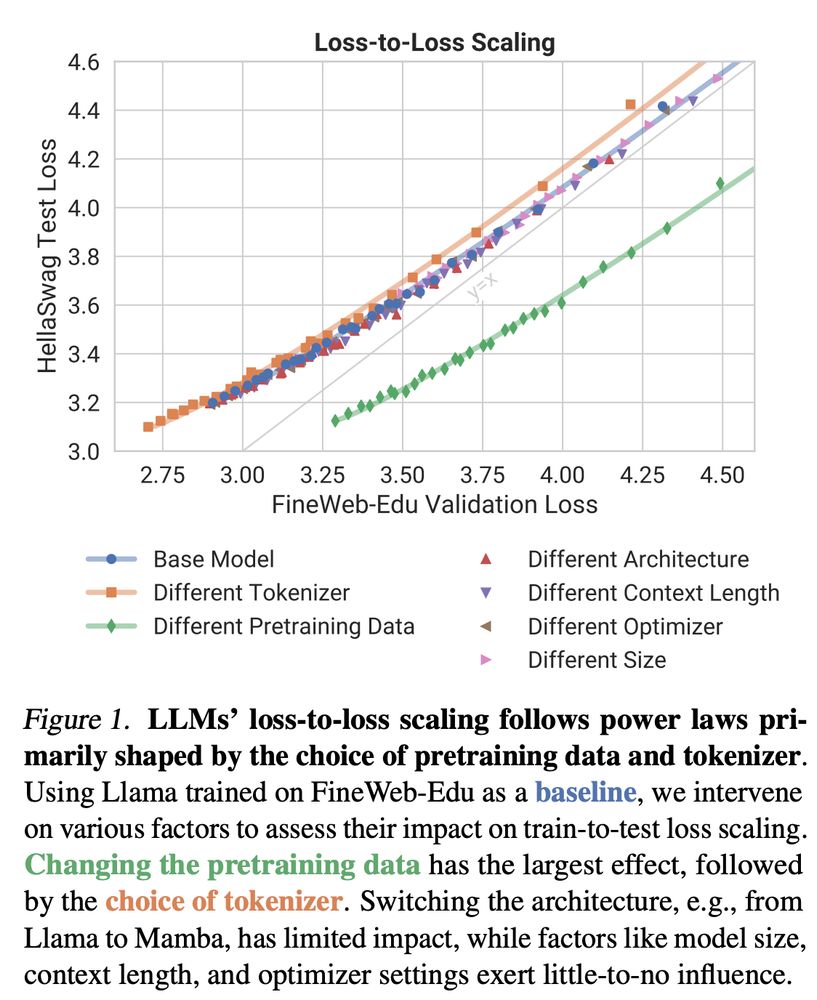
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
February 18, 2025 at 2:09 PM
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
February 17, 2025 at 6:22 PM
CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Reposted by Andreas Hochlehnert

SWE-bench Multimodal evaluation code is out now!
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/

January 17, 2025 at 9:06 AM
SWE-bench Multimodal evaluation code is out now!
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
www.swebench.com/sb-cli/
We are presenting CiteMe today at the 11AM poster session (East Exhibit Hall A-C, #3309)
CiteMe is a challenging benchmark for LM-based agents to find paper citations, moving beyond simple multiple-choice Q&A to real-world use cases.
Come by and say hi :)
citeme.ai
CiteMe is a challenging benchmark for LM-based agents to find paper citations, moving beyond simple multiple-choice Q&A to real-world use cases.
Come by and say hi :)
citeme.ai
CiteME
CiteME is a benchmark designed to test the abilities of language models in finding papers that are cited in scientific texts.
citeme.ai
December 13, 2024 at 4:18 PM
We are presenting CiteMe today at the 11AM poster session (East Exhibit Hall A-C, #3309)
CiteMe is a challenging benchmark for LM-based agents to find paper citations, moving beyond simple multiple-choice Q&A to real-world use cases.
Come by and say hi :)
citeme.ai
CiteMe is a challenging benchmark for LM-based agents to find paper citations, moving beyond simple multiple-choice Q&A to real-world use cases.
Come by and say hi :)
citeme.ai
Reposted by Andreas Hochlehnert

Here's a fledgling starter pack for the AI community in Tübingen. Let me know if you'd like to be added!
go.bsky.app/NFbVzrA
go.bsky.app/NFbVzrA

Tübingen AI
Join the conversation
go.bsky.app
November 19, 2024 at 1:14 PM
Here's a fledgling starter pack for the AI community in Tübingen. Let me know if you'd like to be added!
go.bsky.app/NFbVzrA
go.bsky.app/NFbVzrA