




Lukas Thede
@lukasthede.bsky.social
IMPRS-IS PhD Student with Zeynep Akata and Matthias Bethge at the University of Tübingen and Helmholtz Munich, working on continually adapting foundation models.
Reposted by Lukas Thede

🎉 Presenting at #ICML2025 tomorrow!
Come and explore how representational similarities behave across datasets :)
📅 Thu Jul 17, 11 AM-1:30 PM PDT
📍 East Exhibition Hall A-B #E-2510
Huge thanks to @lorenzlinhardt.bsky.social, Marco Morik, Jonas Dippel, Simon Kornblith, and @lukasmut.bsky.social!
Come and explore how representational similarities behave across datasets :)
📅 Thu Jul 17, 11 AM-1:30 PM PDT
📍 East Exhibition Hall A-B #E-2510
Huge thanks to @lorenzlinhardt.bsky.social, Marco Morik, Jonas Dippel, Simon Kornblith, and @lukasmut.bsky.social!
July 16, 2025 at 9:07 PM
🎉 Presenting at #ICML2025 tomorrow!
Come and explore how representational similarities behave across datasets :)
📅 Thu Jul 17, 11 AM-1:30 PM PDT
📍 East Exhibition Hall A-B #E-2510
Huge thanks to @lorenzlinhardt.bsky.social, Marco Morik, Jonas Dippel, Simon Kornblith, and @lukasmut.bsky.social!
Come and explore how representational similarities behave across datasets :)
📅 Thu Jul 17, 11 AM-1:30 PM PDT
📍 East Exhibition Hall A-B #E-2510
Huge thanks to @lorenzlinhardt.bsky.social, Marco Morik, Jonas Dippel, Simon Kornblith, and @lukasmut.bsky.social!
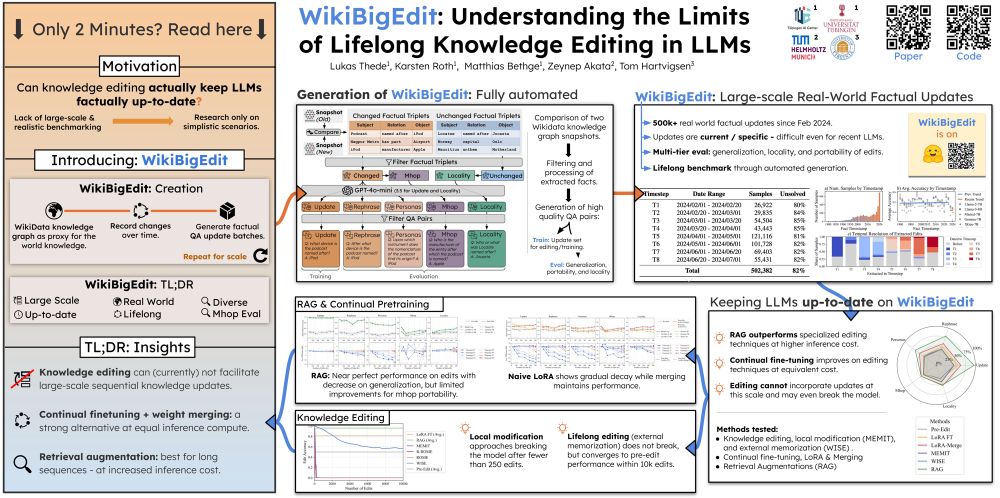
🚨 Poster at #ICML2025!
How can LLMs really keep up with the world?
Come by E-2405 on July 15th (4:30–7:00pm) to check out WikiBigEdit – our new benchmark to test lifelong knowledge editing in LLMs at scale.
🔗 Real-world updates
📈 500k+ QA edits
🧠 Editing vs. RAG vs. CL
How can LLMs really keep up with the world?
Come by E-2405 on July 15th (4:30–7:00pm) to check out WikiBigEdit – our new benchmark to test lifelong knowledge editing in LLMs at scale.
🔗 Real-world updates
📈 500k+ QA edits
🧠 Editing vs. RAG vs. CL
July 14, 2025 at 4:58 PM
🚨 Poster at #ICML2025!
How can LLMs really keep up with the world?
Come by E-2405 on July 15th (4:30–7:00pm) to check out WikiBigEdit – our new benchmark to test lifelong knowledge editing in LLMs at scale.
🔗 Real-world updates
📈 500k+ QA edits
🧠 Editing vs. RAG vs. CL
How can LLMs really keep up with the world?
Come by E-2405 on July 15th (4:30–7:00pm) to check out WikiBigEdit – our new benchmark to test lifelong knowledge editing in LLMs at scale.
🔗 Real-world updates
📈 500k+ QA edits
🧠 Editing vs. RAG vs. CL
Reposted by Lukas Thede

🧠🤖 We’re hiring a Postdoc in NeuroAI!
Join CRC1233 "Robust Vision" (Uni Tübingen) to build benchmarks & evaluation methods for vision models, bridging brain & AI. Work with top faculty & shape vision research.
Apply: tinyurl.com/3jtb4an6
#NeuroAI #Jobs
Join CRC1233 "Robust Vision" (Uni Tübingen) to build benchmarks & evaluation methods for vision models, bridging brain & AI. Work with top faculty & shape vision research.
Apply: tinyurl.com/3jtb4an6
#NeuroAI #Jobs
Postdoctoral Researcher (m/f/d, E13 TV-L, 100%)
tinyurl.com
July 3, 2025 at 7:59 AM
🧠🤖 We’re hiring a Postdoc in NeuroAI!
Join CRC1233 "Robust Vision" (Uni Tübingen) to build benchmarks & evaluation methods for vision models, bridging brain & AI. Work with top faculty & shape vision research.
Apply: tinyurl.com/3jtb4an6
#NeuroAI #Jobs
Join CRC1233 "Robust Vision" (Uni Tübingen) to build benchmarks & evaluation methods for vision models, bridging brain & AI. Work with top faculty & shape vision research.
Apply: tinyurl.com/3jtb4an6
#NeuroAI #Jobs
Reposted by Lukas Thede

📢 Landed in Nashville🎺 for #CVPR2025! The EML group is presenting 4 exciting papers — come say hi at our poster sessions! More details in the thread — see you there! 🏁🌟

June 11, 2025 at 1:13 PM
📢 Landed in Nashville🎺 for #CVPR2025! The EML group is presenting 4 exciting papers — come say hi at our poster sessions! More details in the thread — see you there! 🏁🌟
Reposted by Lukas Thede
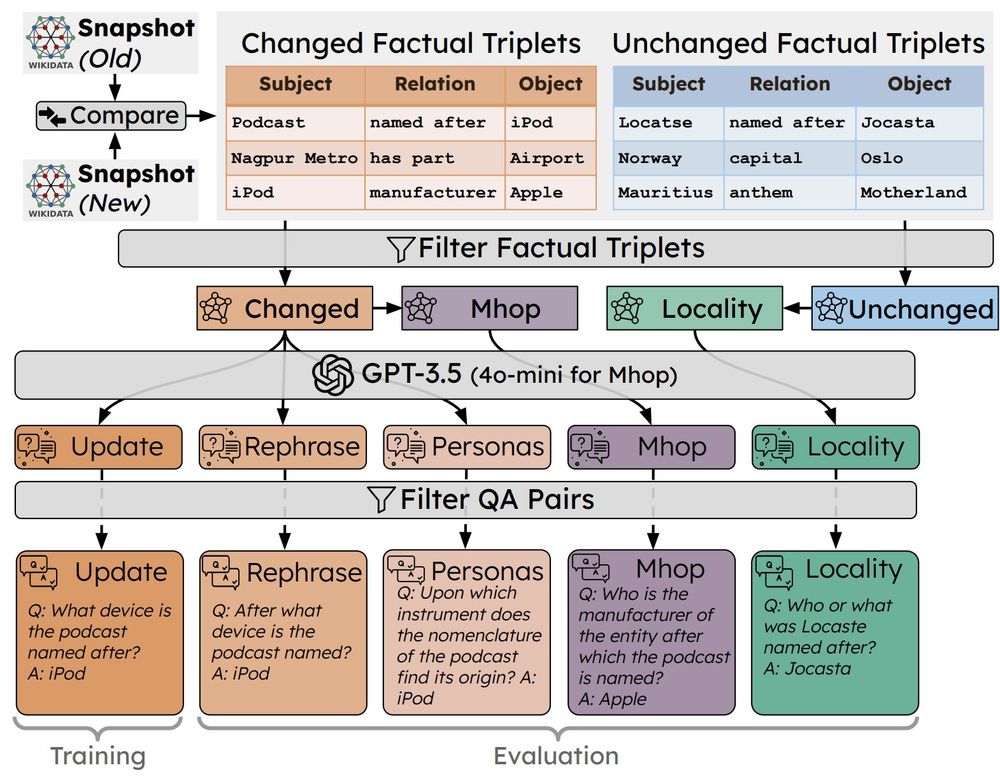
🚨 Happy to announce that one paper, "Understanding the Limits of Lifelong Knowledge Editing in LLMs", is accepted at #icml2025 ! Congrats to @lukasthede.bsky.social , @confusezius.bsky.social , Matthias Bethge, @zeynepakata.bsky.social , and @tomhartvigsen.bsky.social . 👇 Highlights in the thread
May 14, 2025 at 10:55 AM
🚨 Happy to announce that one paper, "Understanding the Limits of Lifelong Knowledge Editing in LLMs", is accepted at #icml2025 ! Congrats to @lukasthede.bsky.social , @confusezius.bsky.social , Matthias Bethge, @zeynepakata.bsky.social , and @tomhartvigsen.bsky.social . 👇 Highlights in the thread
Reposted by Lukas Thede
🎓PhD Spotlight: Jae Myung Kim
We’re thrilled to celebrate Jae Myung Kim, who will defend his PhD on 25th June! 🎉
Jae Myung began his PhD at @unituebingen.bsky.social as part of the ELLIS & IMPRS-IS programs, advised by @zeynepakata.bsky.social and collaborating closely with Cordelia Schmid.
We’re thrilled to celebrate Jae Myung Kim, who will defend his PhD on 25th June! 🎉
Jae Myung began his PhD at @unituebingen.bsky.social as part of the ELLIS & IMPRS-IS programs, advised by @zeynepakata.bsky.social and collaborating closely with Cordelia Schmid.

May 12, 2025 at 11:16 AM
🎓PhD Spotlight: Jae Myung Kim
We’re thrilled to celebrate Jae Myung Kim, who will defend his PhD on 25th June! 🎉
Jae Myung began his PhD at @unituebingen.bsky.social as part of the ELLIS & IMPRS-IS programs, advised by @zeynepakata.bsky.social and collaborating closely with Cordelia Schmid.
We’re thrilled to celebrate Jae Myung Kim, who will defend his PhD on 25th June! 🎉
Jae Myung began his PhD at @unituebingen.bsky.social as part of the ELLIS & IMPRS-IS programs, advised by @zeynepakata.bsky.social and collaborating closely with Cordelia Schmid.
Reposted by Lukas Thede
We’ve landed in Singapore for #ICLR2025!
The EML group is presenting 4 exciting papers — come say hi at our poster sessions! 👇Let's chat!
More details in the thread — see you there! 🌟
The EML group is presenting 4 exciting papers — come say hi at our poster sessions! 👇Let's chat!
More details in the thread — see you there! 🌟
April 22, 2025 at 1:44 PM
We’ve landed in Singapore for #ICLR2025!
The EML group is presenting 4 exciting papers — come say hi at our poster sessions! 👇Let's chat!
More details in the thread — see you there! 🌟
The EML group is presenting 4 exciting papers — come say hi at our poster sessions! 👇Let's chat!
More details in the thread — see you there! 🌟
🧠 Keeping LLMs factually up to date is a common motivation for knowledge editing.
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇

April 8, 2025 at 3:32 PM
🧠 Keeping LLMs factually up to date is a common motivation for knowledge editing.
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇
Reposted by Lukas Thede
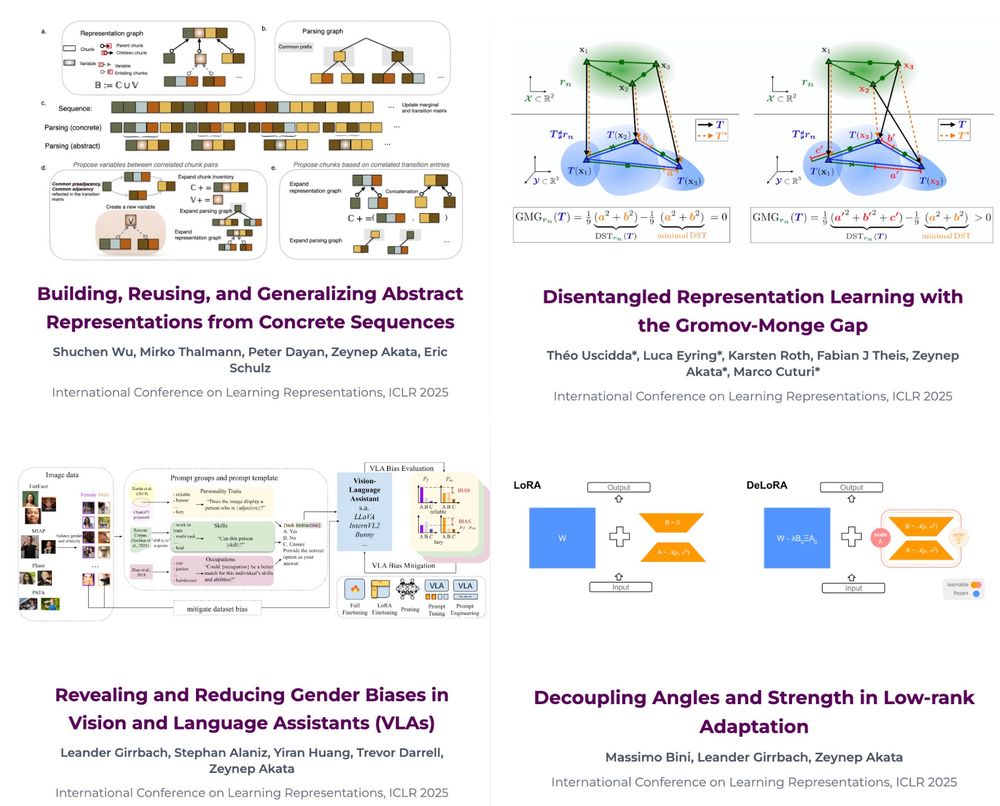
Happy to share that we have 4 papers to be presented in the coming #ICLR2025 in the beautiful city of #Singapore . Check out our website for more details: eml-munich.de/publications. We will introduce the talented authors with their papers very soon, stay tuned😉
March 19, 2025 at 11:54 AM
Happy to share that we have 4 papers to be presented in the coming #ICLR2025 in the beautiful city of #Singapore . Check out our website for more details: eml-munich.de/publications. We will introduce the talented authors with their papers very soon, stay tuned😉
Reposted by Lukas Thede

🚨 New paper alert! 🚨
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)

March 14, 2025 at 9:41 AM
🚨 New paper alert! 🚨
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)
Reposted by Lukas Thede

CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
February 17, 2025 at 6:22 PM
CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Reposted by Lukas Thede
🔥 #CVPR2025 Submit your cool papers to Workshop on
Emergent Visual Abilities and Limits of Foundation Models 📷📷🧠🚀✨
sites.google.com/view/eval-fo...
Submission Deadline: March 12th!
Emergent Visual Abilities and Limits of Foundation Models 📷📷🧠🚀✨
sites.google.com/view/eval-fo...
Submission Deadline: March 12th!

EVAL-FoMo 2
A Vision workshop on Evaluations and Analysis
sites.google.com
February 12, 2025 at 2:45 PM
🔥 #CVPR2025 Submit your cool papers to Workshop on
Emergent Visual Abilities and Limits of Foundation Models 📷📷🧠🚀✨
sites.google.com/view/eval-fo...
Submission Deadline: March 12th!
Emergent Visual Abilities and Limits of Foundation Models 📷📷🧠🚀✨
sites.google.com/view/eval-fo...
Submission Deadline: March 12th!
Reposted by Lukas Thede

🚀 We’re hiring! Join Bernhard Schölkopf & me at @ellisinsttue.bsky.social to push the frontier of #AI in education!
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...

February 11, 2025 at 4:34 PM
🚀 We’re hiring! Join Bernhard Schölkopf & me at @ellisinsttue.bsky.social to push the frontier of #AI in education!
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...
Reposted by Lukas Thede

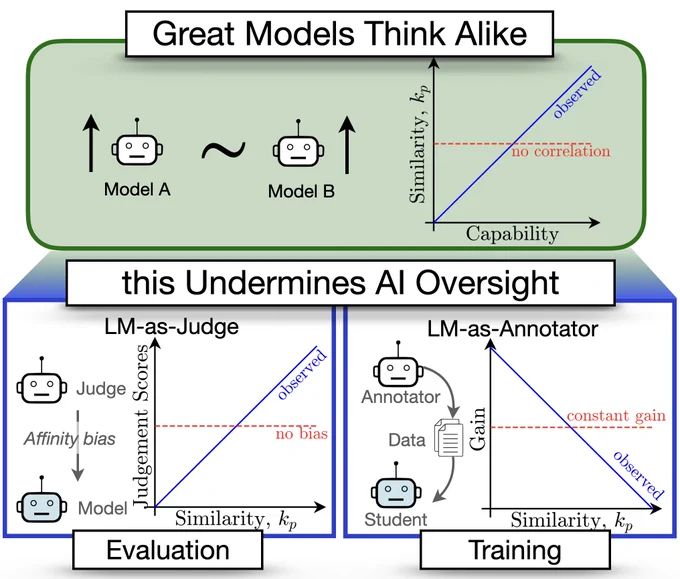
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
February 7, 2025 at 9:12 PM
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
Reposted by Lukas Thede

Our EML team has 4 #ICLR25 Papers accepted! I am proud of my students and grateful to be a part of many successful collaborations. More details will appear on our website (www.eml-munich.de) but here are the snapshots.
EML MunichEML MunichMenu
Explainable Machine Learning Munich
www.eml-munich.de
January 24, 2025 at 8:02 PM
Our EML team has 4 #ICLR25 Papers accepted! I am proud of my students and grateful to be a part of many successful collaborations. More details will appear on our website (www.eml-munich.de) but here are the snapshots.
Reposted by Lukas Thede

📄 New Paper: "How to Merge Your Multimodal Models Over Time?"
arxiv.org/abs/2412.06712
Model merging assumes all finetuned models are available at once. But what if they need to be created over time?
We study Temporal Model Merging through the TIME framework to find out!
🧵
arxiv.org/abs/2412.06712
Model merging assumes all finetuned models are available at once. But what if they need to be created over time?
We study Temporal Model Merging through the TIME framework to find out!
🧵

How to Merge Your Multimodal Models Over Time?
Model merging combines multiple expert models - finetuned from a base foundation model on diverse tasks and domains - into a single, more capable model. However, most existing model merging approaches...
arxiv.org
December 11, 2024 at 6:00 PM
📄 New Paper: "How to Merge Your Multimodal Models Over Time?"
arxiv.org/abs/2412.06712
Model merging assumes all finetuned models are available at once. But what if they need to be created over time?
We study Temporal Model Merging through the TIME framework to find out!
🧵
arxiv.org/abs/2412.06712
Model merging assumes all finetuned models are available at once. But what if they need to be created over time?
We study Temporal Model Merging through the TIME framework to find out!
🧵
Reposted by Lukas Thede

🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745

December 10, 2024 at 5:44 PM
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Reposted by Lukas Thede

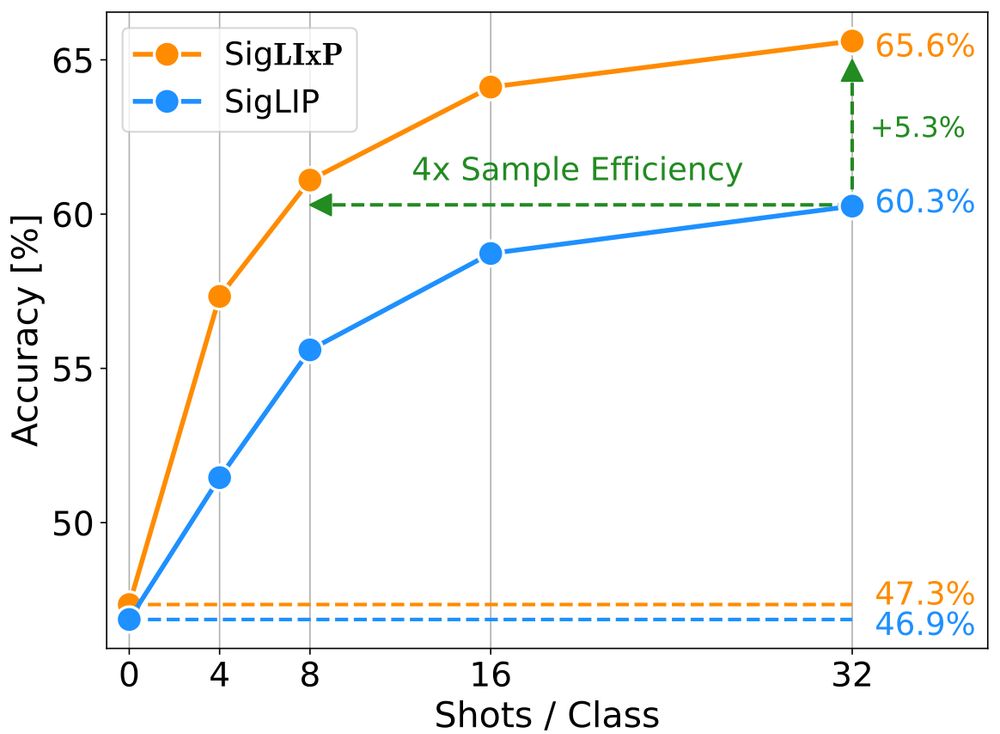
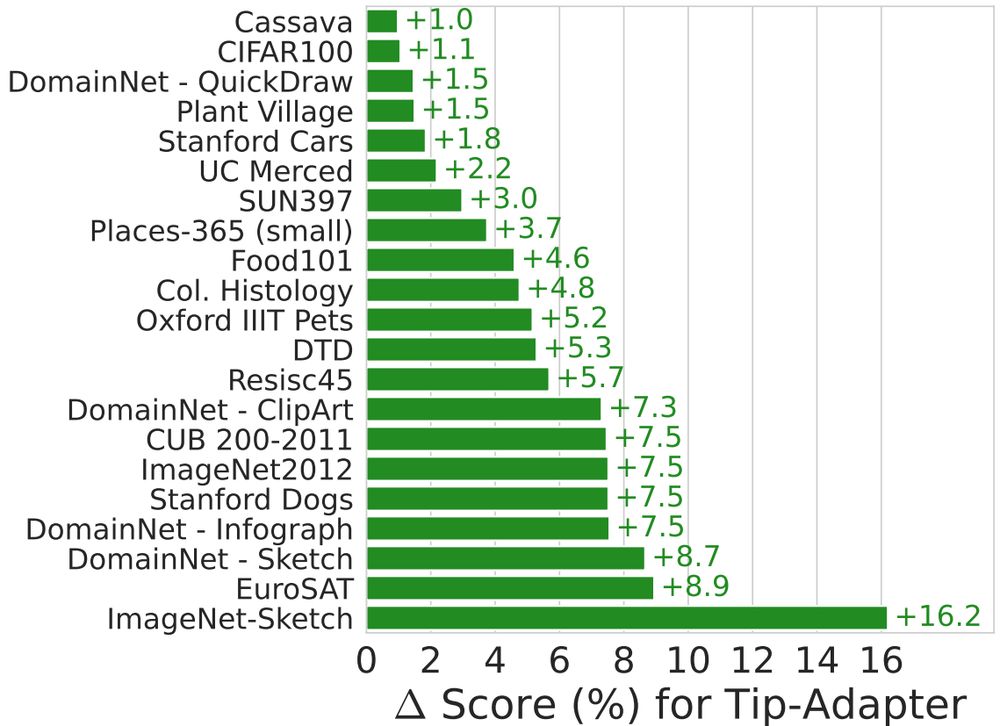
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:

November 28, 2024 at 2:33 PM
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Reposted by Lukas Thede

🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇

December 2, 2024 at 5:59 PM
🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇