




Lukas Thede
@lukasthede.bsky.social
IMPRS-IS PhD Student with Zeynep Akata and Matthias Bethge at the University of Tübingen and Helmholtz Munich, working on continually adapting foundation models.
🚨 Poster at #ICML2025!
How can LLMs really keep up with the world?
Come by E-2405 on July 15th (4:30–7:00pm) to check out WikiBigEdit – our new benchmark to test lifelong knowledge editing in LLMs at scale.
🔗 Real-world updates
📈 500k+ QA edits
🧠 Editing vs. RAG vs. CL
How can LLMs really keep up with the world?
Come by E-2405 on July 15th (4:30–7:00pm) to check out WikiBigEdit – our new benchmark to test lifelong knowledge editing in LLMs at scale.
🔗 Real-world updates
📈 500k+ QA edits
🧠 Editing vs. RAG vs. CL
July 14, 2025 at 4:58 PM
🚨 Poster at #ICML2025!
How can LLMs really keep up with the world?
Come by E-2405 on July 15th (4:30–7:00pm) to check out WikiBigEdit – our new benchmark to test lifelong knowledge editing in LLMs at scale.
🔗 Real-world updates
📈 500k+ QA edits
🧠 Editing vs. RAG vs. CL
How can LLMs really keep up with the world?
Come by E-2405 on July 15th (4:30–7:00pm) to check out WikiBigEdit – our new benchmark to test lifelong knowledge editing in LLMs at scale.
🔗 Real-world updates
📈 500k+ QA edits
🧠 Editing vs. RAG vs. CL
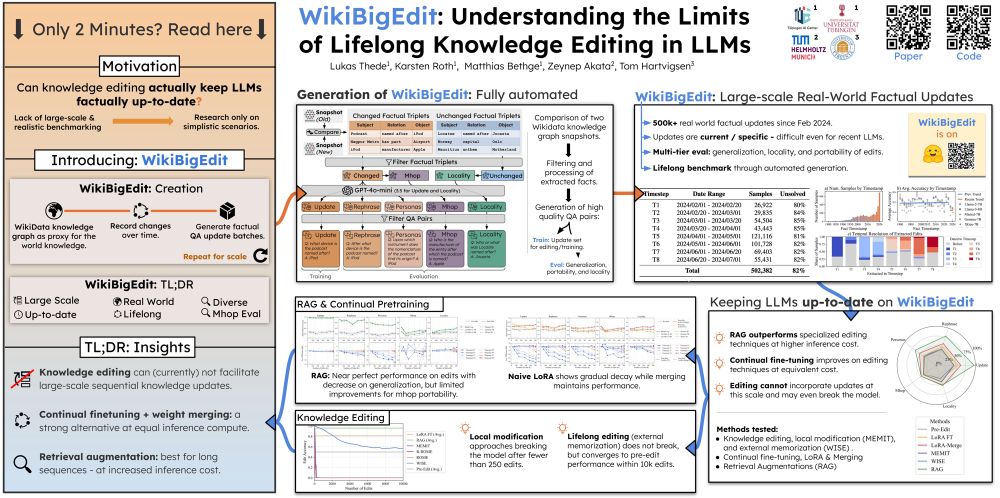
7/
Surprisingly, simple continual finetuning (LoRA) outperforms all editing baselines - at equal inference cost.
And when paired with model merging, performance improves even further over time.
💪 More scalable, more robust, and better retention across time steps.
Surprisingly, simple continual finetuning (LoRA) outperforms all editing baselines - at equal inference cost.
And when paired with model merging, performance improves even further over time.
💪 More scalable, more robust, and better retention across time steps.

April 8, 2025 at 3:32 PM
7/
Surprisingly, simple continual finetuning (LoRA) outperforms all editing baselines - at equal inference cost.
And when paired with model merging, performance improves even further over time.
💪 More scalable, more robust, and better retention across time steps.
Surprisingly, simple continual finetuning (LoRA) outperforms all editing baselines - at equal inference cost.
And when paired with model merging, performance improves even further over time.
💪 More scalable, more robust, and better retention across time steps.
6/
RAG performs best overall - nearly tripling accuracy on edit and generalization tasks.
But:
⏳ It comes with significantly higher inference cost
🔄 And still struggles with multi-hop reasoning over updated facts
RAG performs best overall - nearly tripling accuracy on edit and generalization tasks.
But:
⏳ It comes with significantly higher inference cost
🔄 And still struggles with multi-hop reasoning over updated facts

April 8, 2025 at 3:32 PM
6/
RAG performs best overall - nearly tripling accuracy on edit and generalization tasks.
But:
⏳ It comes with significantly higher inference cost
🔄 And still struggles with multi-hop reasoning over updated facts
RAG performs best overall - nearly tripling accuracy on edit and generalization tasks.
But:
⏳ It comes with significantly higher inference cost
🔄 And still struggles with multi-hop reasoning over updated facts
5/
The result? 📉
Most editing methods struggle at scale.
ROME and MEMIT collapse within a few hundred updates.
Even WISE, built for lifelong edits, degrades quickly - converging to pre-edit performance.
➡️ These techniques aren’t yet ready for real-world demands.
The result? 📉
Most editing methods struggle at scale.
ROME and MEMIT collapse within a few hundred updates.
Even WISE, built for lifelong edits, degrades quickly - converging to pre-edit performance.
➡️ These techniques aren’t yet ready for real-world demands.

April 8, 2025 at 3:32 PM
5/
The result? 📉
Most editing methods struggle at scale.
ROME and MEMIT collapse within a few hundred updates.
Even WISE, built for lifelong edits, degrades quickly - converging to pre-edit performance.
➡️ These techniques aren’t yet ready for real-world demands.
The result? 📉
Most editing methods struggle at scale.
ROME and MEMIT collapse within a few hundred updates.
Even WISE, built for lifelong edits, degrades quickly - converging to pre-edit performance.
➡️ These techniques aren’t yet ready for real-world demands.
4/
We put popular editing methods to the test:
🔧 ROME, MEMIT, WISE
🔁 LoRA finetuning & merging
🔍 Retrieval-augmented generation (RAG)
How do they stack up on update accuracy, reasoning, generalization, and locality?
We put popular editing methods to the test:
🔧 ROME, MEMIT, WISE
🔁 LoRA finetuning & merging
🔍 Retrieval-augmented generation (RAG)
How do they stack up on update accuracy, reasoning, generalization, and locality?

April 8, 2025 at 3:32 PM
4/
We put popular editing methods to the test:
🔧 ROME, MEMIT, WISE
🔁 LoRA finetuning & merging
🔍 Retrieval-augmented generation (RAG)
How do they stack up on update accuracy, reasoning, generalization, and locality?
We put popular editing methods to the test:
🔧 ROME, MEMIT, WISE
🔁 LoRA finetuning & merging
🔍 Retrieval-augmented generation (RAG)
How do they stack up on update accuracy, reasoning, generalization, and locality?
2/
📣 Introducing WikiBigEdit: a new benchmark for lifelong knowledge editing.
It includes:
📌 500K+ real-world QA pairs based on Wikidata
📆 8 time steps over 6 months (Feb–Jul 2024) and continuously updatable
🧪 Rich evaluations: reasoning, generalization, locality, …
📣 Introducing WikiBigEdit: a new benchmark for lifelong knowledge editing.
It includes:
📌 500K+ real-world QA pairs based on Wikidata
📆 8 time steps over 6 months (Feb–Jul 2024) and continuously updatable
🧪 Rich evaluations: reasoning, generalization, locality, …

April 8, 2025 at 3:32 PM
2/
📣 Introducing WikiBigEdit: a new benchmark for lifelong knowledge editing.
It includes:
📌 500K+ real-world QA pairs based on Wikidata
📆 8 time steps over 6 months (Feb–Jul 2024) and continuously updatable
🧪 Rich evaluations: reasoning, generalization, locality, …
📣 Introducing WikiBigEdit: a new benchmark for lifelong knowledge editing.
It includes:
📌 500K+ real-world QA pairs based on Wikidata
📆 8 time steps over 6 months (Feb–Jul 2024) and continuously updatable
🧪 Rich evaluations: reasoning, generalization, locality, …
🧠 Keeping LLMs factually up to date is a common motivation for knowledge editing.
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇

April 8, 2025 at 3:32 PM
🧠 Keeping LLMs factually up to date is a common motivation for knowledge editing.
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇
But what would it actually take to support this in practice at the scale and speed the real world demands?
We explore this question and really push the limits of lifelong knowledge editing in the wild.
👇