



New Blog📖✨:
nanoVLM: The simplest way to train your own Vision-Language Model in pure PyTorch explained step-by-step!
Easy to read, even easier to use. Train your first VLM today!
nanoVLM: The simplest way to train your own Vision-Language Model in pure PyTorch explained step-by-step!
Easy to read, even easier to use. Train your first VLM today!

May 21, 2025 at 1:10 PM
New Blog📖✨:
nanoVLM: The simplest way to train your own Vision-Language Model in pure PyTorch explained step-by-step!
Easy to read, even easier to use. Train your first VLM today!
nanoVLM: The simplest way to train your own Vision-Language Model in pure PyTorch explained step-by-step!
Easy to read, even easier to use. Train your first VLM today!
Real-time SmolVLM in a web browser with transformers.js.
All running locally with no installs. Just open the website.
All running locally with no installs. Just open the website.
May 14, 2025 at 3:39 PM
Real-time SmolVLM in a web browser with transformers.js.
All running locally with no installs. Just open the website.
All running locally with no installs. Just open the website.
Today, we share the tech report for SmolVLM: Redefining small and efficient multimodal models.
🔥 Explaining how to create a tiny 256M VLM that uses less than 1GB of RAM and outperforms our 80B models from 18 months ago!
huggingface.co/papers/2504....
🔥 Explaining how to create a tiny 256M VLM that uses less than 1GB of RAM and outperforms our 80B models from 18 months ago!
huggingface.co/papers/2504....
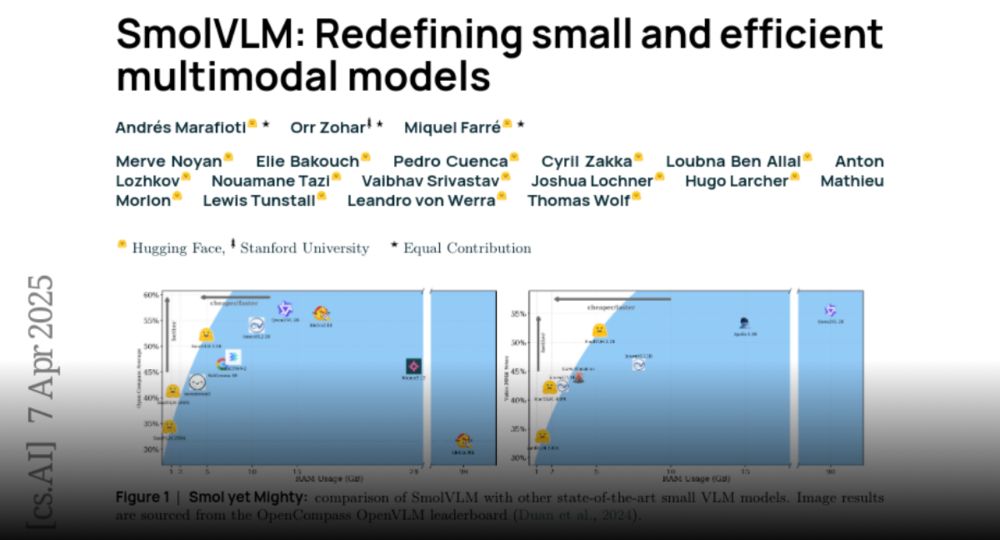
Paper page - SmolVLM: Redefining small and efficient multimodal models
Join the discussion on this paper page
huggingface.co
April 8, 2025 at 3:12 PM
Today, we share the tech report for SmolVLM: Redefining small and efficient multimodal models.
🔥 Explaining how to create a tiny 256M VLM that uses less than 1GB of RAM and outperforms our 80B models from 18 months ago!
huggingface.co/papers/2504....
🔥 Explaining how to create a tiny 256M VLM that uses less than 1GB of RAM and outperforms our 80B models from 18 months ago!
huggingface.co/papers/2504....
🚀 We just dropped SmolDocling: a 256M open-source vision LM for complete document OCR! 📄✨
Lightning fast, process a page in 0.35 sec on consumer GPU using < 500MB VRAM ⚡
SOTA in document conversion, beating every competing model we tested (including models 27x more params) 🤯
But how? 🧶⬇️
Lightning fast, process a page in 0.35 sec on consumer GPU using < 500MB VRAM ⚡
SOTA in document conversion, beating every competing model we tested (including models 27x more params) 🤯
But how? 🧶⬇️

March 17, 2025 at 3:53 PM
🚀 We just dropped SmolDocling: a 256M open-source vision LM for complete document OCR! 📄✨
Lightning fast, process a page in 0.35 sec on consumer GPU using < 500MB VRAM ⚡
SOTA in document conversion, beating every competing model we tested (including models 27x more params) 🤯
But how? 🧶⬇️
Lightning fast, process a page in 0.35 sec on consumer GPU using < 500MB VRAM ⚡
SOTA in document conversion, beating every competing model we tested (including models 27x more params) 🤯
But how? 🧶⬇️
Extremely bullish on @CohereForAI's Aya Vision (8B & 32B) - new SOTA open-weight VLMs
- 8B wins up to 81% of the time in its class, better than Gemini Flash
- 32B beats Llama 3.2 90B!
- Integrated on @hf.co from Day 0!
Check out their blog! huggingface.co/blog/aya-vis...
- 8B wins up to 81% of the time in its class, better than Gemini Flash
- 32B beats Llama 3.2 90B!
- Integrated on @hf.co from Day 0!
Check out their blog! huggingface.co/blog/aya-vis...

A Deepdive into Aya Vision: Advancing the Frontier of Multilingual Multimodality
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
March 5, 2025 at 2:38 PM
Extremely bullish on @CohereForAI's Aya Vision (8B & 32B) - new SOTA open-weight VLMs
- 8B wins up to 81% of the time in its class, better than Gemini Flash
- 32B beats Llama 3.2 90B!
- Integrated on @hf.co from Day 0!
Check out their blog! huggingface.co/blog/aya-vis...
- 8B wins up to 81% of the time in its class, better than Gemini Flash
- 32B beats Llama 3.2 90B!
- Integrated on @hf.co from Day 0!
Check out their blog! huggingface.co/blog/aya-vis...
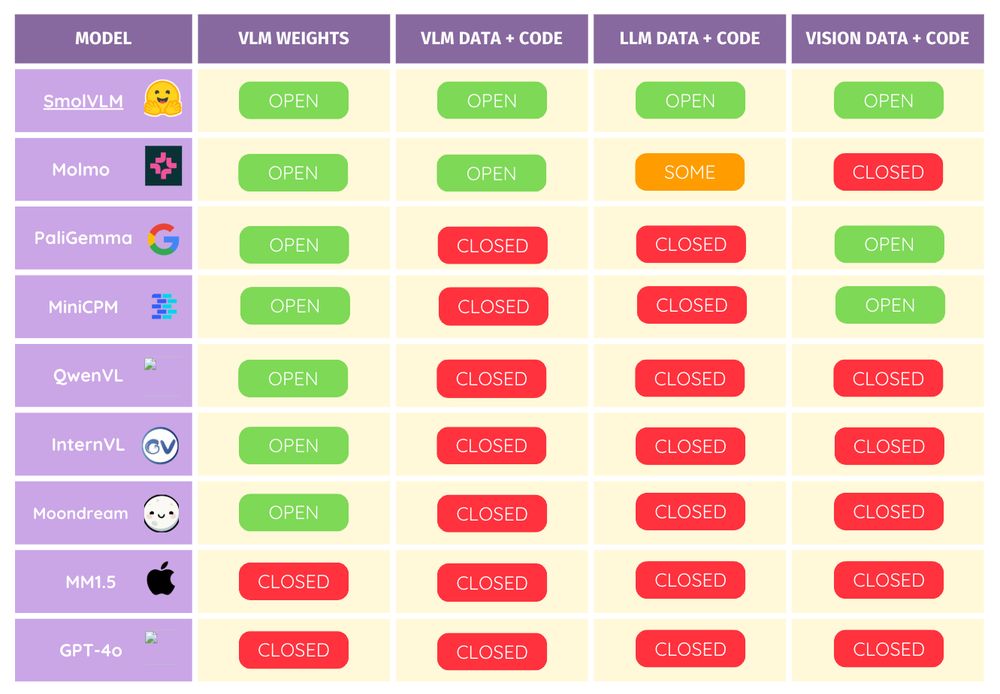
Fuck it, today we're open-sourcing the codebase used to train SmolVLM from scratch on 256 H100s 🔥
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
January 31, 2025 at 3:06 PM
Fuck it, today we're open-sourcing the codebase used to train SmolVLM from scratch on 256 H100s 🔥
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
Introducing the smollest VLMs yet! 🤏
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀

January 23, 2025 at 1:33 PM
Introducing the smollest VLMs yet! 🤏
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀
Reposted by Andi

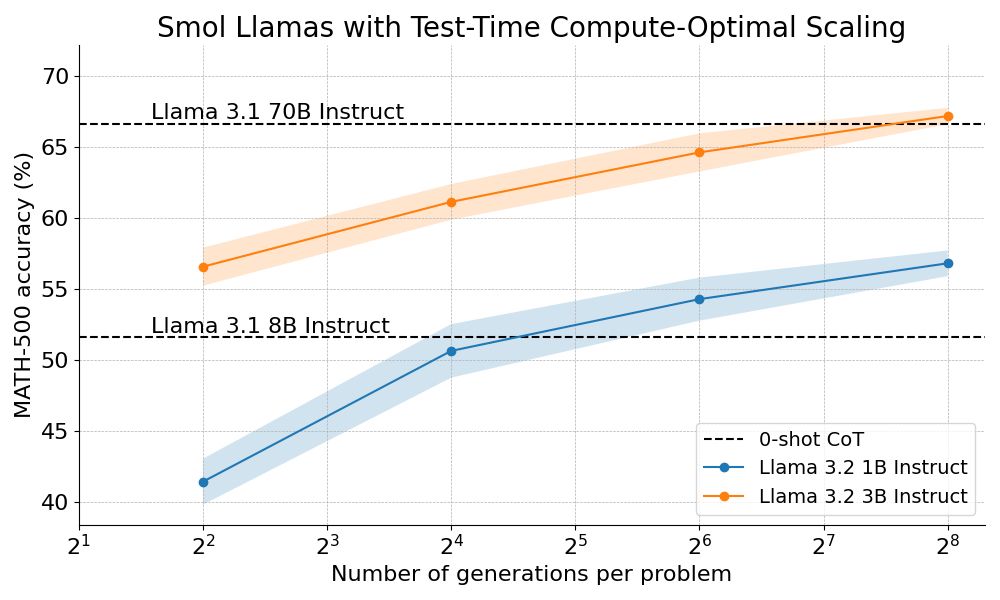
We outperform Llama 70B with Llama 3B on hard math by scaling test-time compute 🔥
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
December 16, 2024 at 5:08 PM
We outperform Llama 70B with Llama 3B on hard math by scaling test-time compute 🔥
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
Do you want to try Llama 3.3?
huggingface.co/chat/
huggingface.co/chat/

HuggingChat
Making the community's best AI chat models available to everyone.
huggingface.co
December 6, 2024 at 6:41 PM
Do you want to try Llama 3.3?
huggingface.co/chat/
huggingface.co/chat/
Reposted by Andi

Just been messing with SmolVLM - visual language model that is _Smol_.
2B params, does some amazing stuff, with little memory, quickly. I'll post a couple of examples below.
Super cool stuff from @merve.bsky.social & @andimara.bsky.social!
2B params, does some amazing stuff, with little memory, quickly. I'll post a couple of examples below.
Super cool stuff from @merve.bsky.social & @andimara.bsky.social!
December 3, 2024 at 10:52 AM
Just been messing with SmolVLM - visual language model that is _Smol_.
2B params, does some amazing stuff, with little memory, quickly. I'll post a couple of examples below.
Super cool stuff from @merve.bsky.social & @andimara.bsky.social!
2B params, does some amazing stuff, with little memory, quickly. I'll post a couple of examples below.
Super cool stuff from @merve.bsky.social & @andimara.bsky.social!
Reposted by Andi

📬 Summarize and rewrite your text/emails faster, and offline!
Check @andimara.bsky.social's Smol Tools for summarization and rewriting. It uses SmolLM2 to summarize text and make it more friendly or professional, all running locally thanks to llama.cpp github.com/huggingface/...
Check @andimara.bsky.social's Smol Tools for summarization and rewriting. It uses SmolLM2 to summarize text and make it more friendly or professional, all running locally thanks to llama.cpp github.com/huggingface/...
smollm/smol_tools at main · huggingface/smollm
Everything about the SmolLM & SmolLM2 family of models - huggingface/smollm
github.com
November 30, 2024 at 3:59 PM
📬 Summarize and rewrite your text/emails faster, and offline!
Check @andimara.bsky.social's Smol Tools for summarization and rewriting. It uses SmolLM2 to summarize text and make it more friendly or professional, all running locally thanks to llama.cpp github.com/huggingface/...
Check @andimara.bsky.social's Smol Tools for summarization and rewriting. It uses SmolLM2 to summarize text and make it more friendly or professional, all running locally thanks to llama.cpp github.com/huggingface/...
Reposted by Andi

it only takes a single CLI command to kick-off a Direct Preference Optimization fine-tuning run on SmolVLM huggingface.co/blog/smolvlm...
you're welcome
you're welcome

November 28, 2024 at 11:06 AM
it only takes a single CLI command to kick-off a Direct Preference Optimization fine-tuning run on SmolVLM huggingface.co/blog/smolvlm...
you're welcome
you're welcome
Do you want to help us build SmolVLM2? We are hiring interns! Remote roles from EMEA or US.
apply.workable.com/huggingface/...
apply.workable.com/huggingface/...
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 29, 2024 at 10:25 AM
Do you want to help us build SmolVLM2? We are hiring interns! Remote roles from EMEA or US.
apply.workable.com/huggingface/...
apply.workable.com/huggingface/...
Reposted by Andi
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
Reposted by Andi
The authors of ColPali trained a retrieval model based on SmolVLM 🤠 TLDR;
- ColSmolVLM performs better than ColPali and DSE-Qwen2 on all English tasks
- ColSmolVLM is more memory efficient than ColQwen2 💗
Find the model here huggingface.co/vidore/colsm...
- ColSmolVLM performs better than ColPali and DSE-Qwen2 on all English tasks
- ColSmolVLM is more memory efficient than ColQwen2 💗
Find the model here huggingface.co/vidore/colsm...

November 27, 2024 at 2:10 PM
The authors of ColPali trained a retrieval model based on SmolVLM 🤠 TLDR;
- ColSmolVLM performs better than ColPali and DSE-Qwen2 on all English tasks
- ColSmolVLM is more memory efficient than ColQwen2 💗
Find the model here huggingface.co/vidore/colsm...
- ColSmolVLM performs better than ColPali and DSE-Qwen2 on all English tasks
- ColSmolVLM is more memory efficient than ColQwen2 💗
Find the model here huggingface.co/vidore/colsm...
Reposted by Andi

🚀 Excited to share that our provocation paper "Evaluations Using Wikipedia without Data Contamination: From Trusting Articles to Trusting Edit Processes" has been accepted at the NeurIPS workshop Evaluating Evaluations! 🌐📚
#NeurIPS2024 #evaleval #AIEvaluation
#NeurIPS2024 #evaleval #AIEvaluation

November 28, 2024 at 9:41 AM
🚀 Excited to share that our provocation paper "Evaluations Using Wikipedia without Data Contamination: From Trusting Articles to Trusting Edit Processes" has been accepted at the NeurIPS workshop Evaluating Evaluations! 🌐📚
#NeurIPS2024 #evaleval #AIEvaluation
#NeurIPS2024 #evaleval #AIEvaluation
Reposted by Andi
It's pretty sad to see the negative sentiment towards Hugging Face on this platform due to a dataset put by one of the employees. I want to write a small piece. 🧵
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
November 27, 2024 at 3:23 PM
It's pretty sad to see the negative sentiment towards Hugging Face on this platform due to a dataset put by one of the employees. I want to write a small piece. 🧵
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
Reposted by Andi

Some people are pushing models to the top right of the plot following the scaling laws, others push them to the top left and make them faster and cheaper!
We need both!
We need both!
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
November 26, 2024 at 4:33 PM
Some people are pushing models to the top right of the plot following the scaling laws, others push them to the top left and make them faster and cheaper!
We need both!
We need both!
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
The best thing about working at @huggingface is how often I’m floored by the brilliance of my colleagues. Truly inspiring.
November 25, 2024 at 3:50 PM
The best thing about working at @huggingface is how often I’m floored by the brilliance of my colleagues. Truly inspiring.
Working hard on an awesome multimodal release. Coming soon :)
November 25, 2024 at 12:56 PM
Working hard on an awesome multimodal release. Coming soon :)