




Train your Vision-Language Model in just two commands:
> git clone github.com/huggingface/...
> python train.py
> git clone github.com/huggingface/...
> python train.py

GitHub - huggingface/nanoVLM: The simplest, fastest repository for training/finetuning small-sized VLMs.
The simplest, fastest repository for training/finetuning small-sized VLMs. - huggingface/nanoVLM
github.com
May 21, 2025 at 1:10 PM
Train your Vision-Language Model in just two commands:
> git clone github.com/huggingface/...
> python train.py
> git clone github.com/huggingface/...
> python train.py
If you’re into efficient multimodal models, you’ll love this one.
Check out the paper: huggingface.co/papers/2504....
Check out the paper: huggingface.co/papers/2504....
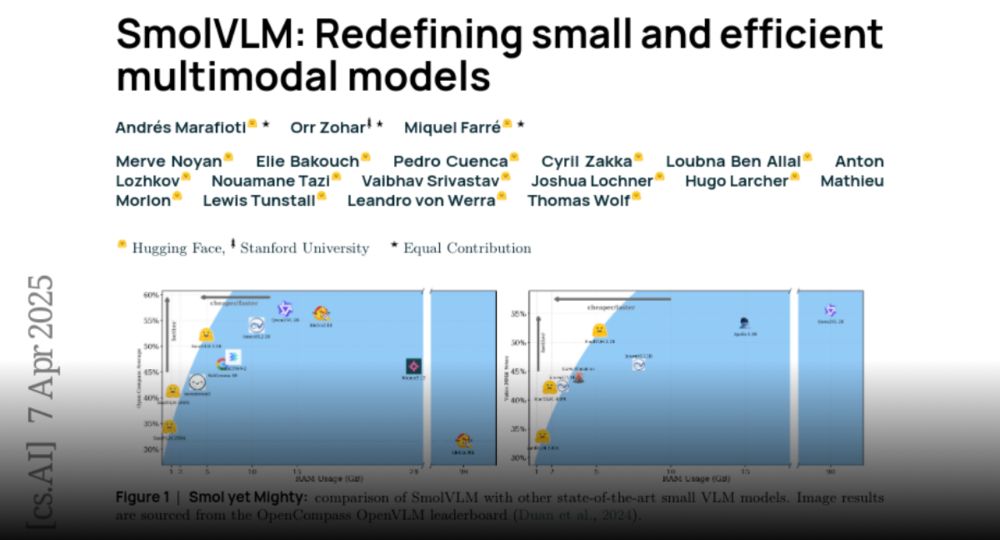
Paper page - SmolVLM: Redefining small and efficient multimodal models
Join the discussion on this paper page
huggingface.co
April 8, 2025 at 3:12 PM
If you’re into efficient multimodal models, you’ll love this one.
Check out the paper: huggingface.co/papers/2504....
Check out the paper: huggingface.co/papers/2504....
📱 Real-world Efficiency: We've created an app using SmolVLM on an iPhone 15 and got real-time inference directly from its camera!
🌐 Browser-based Inference? Yep! We get lightning-fast inference speeds of 40-80 tokens per second directly in a web browser. No tricks, just compact, efficient models!
🌐 Browser-based Inference? Yep! We get lightning-fast inference speeds of 40-80 tokens per second directly in a web browser. No tricks, just compact, efficient models!
April 8, 2025 at 3:12 PM
📱 Real-world Efficiency: We've created an app using SmolVLM on an iPhone 15 and got real-time inference directly from its camera!
🌐 Browser-based Inference? Yep! We get lightning-fast inference speeds of 40-80 tokens per second directly in a web browser. No tricks, just compact, efficient models!
🌐 Browser-based Inference? Yep! We get lightning-fast inference speeds of 40-80 tokens per second directly in a web browser. No tricks, just compact, efficient models!
🌟 State-of-the-Art Performance, SmolVLM comes in three powerful yet compact sizes—256M, 500M, and 2.2B parameters—each setting new SOTA benchmarks for their hardware constraints in image and video understanding.
April 8, 2025 at 3:12 PM
🌟 State-of-the-Art Performance, SmolVLM comes in three powerful yet compact sizes—256M, 500M, and 2.2B parameters—each setting new SOTA benchmarks for their hardware constraints in image and video understanding.
✨ Less CoT, more efficiency: Turns out, too much Chain-of-Thought (CoT) data actually hurts performance in small models. They dumb
✨ Longer videos, better results: Increasing video length during training enhanced performance on both video and image tasks.
✨ Longer videos, better results: Increasing video length during training enhanced performance on both video and image tasks.
April 8, 2025 at 3:12 PM
✨ Less CoT, more efficiency: Turns out, too much Chain-of-Thought (CoT) data actually hurts performance in small models. They dumb
✨ Longer videos, better results: Increasing video length during training enhanced performance on both video and image tasks.
✨ Longer videos, better results: Increasing video length during training enhanced performance on both video and image tasks.
✨ System prompts and special tokens are key: Introducing system prompts and dedicated media intro/outro tokens significantly boosted our compact VLM’s performance—especially for video tasks.
April 8, 2025 at 3:12 PM
✨ System prompts and special tokens are key: Introducing system prompts and dedicated media intro/outro tokens significantly boosted our compact VLM’s performance—especially for video tasks.
✨ Pixel shuffling magic: Aggressively pixel shuffling helped our compact VLMs "see" better, same performance with sequences 16x shorter!
✨ Learned positional tokens FTW: For compact models, learned positional tokens significantly outperform raw text tokens, enhancing efficiency and accuracy.
✨ Learned positional tokens FTW: For compact models, learned positional tokens significantly outperform raw text tokens, enhancing efficiency and accuracy.
April 8, 2025 at 3:12 PM
✨ Pixel shuffling magic: Aggressively pixel shuffling helped our compact VLMs "see" better, same performance with sequences 16x shorter!
✨ Learned positional tokens FTW: For compact models, learned positional tokens significantly outperform raw text tokens, enhancing efficiency and accuracy.
✨ Learned positional tokens FTW: For compact models, learned positional tokens significantly outperform raw text tokens, enhancing efficiency and accuracy.
✨ Smaller is smarter with SigLIP: Surprise! Smaller LLMs didn't benefit from the usual large SigLIP (400M). Instead, we use the 80M base SigLIP that performs equally well at just 20% of the original size!
April 8, 2025 at 3:12 PM
✨ Smaller is smarter with SigLIP: Surprise! Smaller LLMs didn't benefit from the usual large SigLIP (400M). Instead, we use the 80M base SigLIP that performs equally well at just 20% of the original size!
Here are the coolest insights from our experiments:
✨ Longer context = Big wins: Increasing the context length from 2K to 16K gave our tiny VLMs a 60% performance boost!
✨ Longer context = Big wins: Increasing the context length from 2K to 16K gave our tiny VLMs a 60% performance boost!
April 8, 2025 at 3:12 PM
Here are the coolest insights from our experiments:
✨ Longer context = Big wins: Increasing the context length from 2K to 16K gave our tiny VLMs a 60% performance boost!
✨ Longer context = Big wins: Increasing the context length from 2K to 16K gave our tiny VLMs a 60% performance boost!
SmolDocling is available today 🏗️
🔗 Model: huggingface.co/ds4sd/SmolDo...
📖 Paper: huggingface.co/papers/2503....
🤗 Space: huggingface.co/spaces/ds4sd...
Try it and let us know what you think! 💬
🔗 Model: huggingface.co/ds4sd/SmolDo...
📖 Paper: huggingface.co/papers/2503....
🤗 Space: huggingface.co/spaces/ds4sd...
Try it and let us know what you think! 💬

ds4sd/SmolDocling-256M-preview · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
March 17, 2025 at 3:53 PM
SmolDocling is available today 🏗️
🔗 Model: huggingface.co/ds4sd/SmolDo...
📖 Paper: huggingface.co/papers/2503....
🤗 Space: huggingface.co/spaces/ds4sd...
Try it and let us know what you think! 💬
🔗 Model: huggingface.co/ds4sd/SmolDo...
📖 Paper: huggingface.co/papers/2503....
🤗 Space: huggingface.co/spaces/ds4sd...
Try it and let us know what you think! 💬
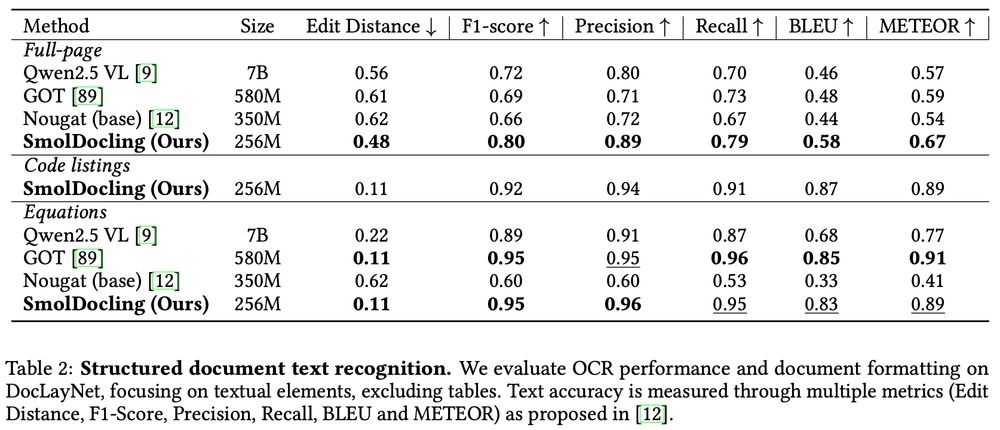
At only 256M parameters, SmolDocling outperforms much larger models on key document conversion tasks:
🖋️ Full-page transcription: Beats models 27× bigger!
📑 Equations: Matches or beats leading models like GOT
💻 Code recognition: We introduce the first benchmark for code OCR
🖋️ Full-page transcription: Beats models 27× bigger!
📑 Equations: Matches or beats leading models like GOT
💻 Code recognition: We introduce the first benchmark for code OCR
March 17, 2025 at 3:53 PM
At only 256M parameters, SmolDocling outperforms much larger models on key document conversion tasks:
🖋️ Full-page transcription: Beats models 27× bigger!
📑 Equations: Matches or beats leading models like GOT
💻 Code recognition: We introduce the first benchmark for code OCR
🖋️ Full-page transcription: Beats models 27× bigger!
📑 Equations: Matches or beats leading models like GOT
💻 Code recognition: We introduce the first benchmark for code OCR
What makes it unique?
📌 Handles everything a document has: tables, charts, code, equations, lists, and more
📌 Works beyond scientific papers—supports business docs, patents, and forms
📌 It runs with less than 1GB of RAM, so running at large batch sizes is super cheap!
📌 Handles everything a document has: tables, charts, code, equations, lists, and more
📌 Works beyond scientific papers—supports business docs, patents, and forms
📌 It runs with less than 1GB of RAM, so running at large batch sizes is super cheap!

March 17, 2025 at 3:53 PM
What makes it unique?
📌 Handles everything a document has: tables, charts, code, equations, lists, and more
📌 Works beyond scientific papers—supports business docs, patents, and forms
📌 It runs with less than 1GB of RAM, so running at large batch sizes is super cheap!
📌 Handles everything a document has: tables, charts, code, equations, lists, and more
📌 Works beyond scientific papers—supports business docs, patents, and forms
📌 It runs with less than 1GB of RAM, so running at large batch sizes is super cheap!
How does SmolDocling beat models 27× bigger? SmolDocling transforms any document into structured metadata with DocTags, being SOTA in:
✅ Full-page conversion
✅ Layout identification
✅ Equations, tables, charts, plots, code OCR
✅ Full-page conversion
✅ Layout identification
✅ Equations, tables, charts, plots, code OCR
March 17, 2025 at 3:53 PM
How does SmolDocling beat models 27× bigger? SmolDocling transforms any document into structured metadata with DocTags, being SOTA in:
✅ Full-page conversion
✅ Layout identification
✅ Equations, tables, charts, plots, code OCR
✅ Full-page conversion
✅ Layout identification
✅ Equations, tables, charts, plots, code OCR
Me too! Highlight of my career so far :)
January 31, 2025 at 3:21 PM
Me too! Highlight of my career so far :)
And that was why we didn't release this before. It's live research code. Most gets rewritten fairly often, and some parts have been the same for years.
It works, it manages to produce SOTA results at 256M and 80B sizes, but it's not production code.
Go check it out:
github.com/huggingface/...
It works, it manages to produce SOTA results at 256M and 80B sizes, but it's not production code.
Go check it out:
github.com/huggingface/...
smollm/vision at main · huggingface/smollm
Everything about the SmolLM2 and SmolVLM family of models - huggingface/smollm
github.com
January 31, 2025 at 3:06 PM
And that was why we didn't release this before. It's live research code. Most gets rewritten fairly often, and some parts have been the same for years.
It works, it manages to produce SOTA results at 256M and 80B sizes, but it's not production code.
Go check it out:
github.com/huggingface/...
It works, it manages to produce SOTA results at 256M and 80B sizes, but it's not production code.
Go check it out:
github.com/huggingface/...
And it also has a bunch of bugs like this one in our modeling_vllama3.py file. We start from a pretrained LLM, but for some reason the weights of the head are not loaded from the model. I still don't know why :(

January 31, 2025 at 3:06 PM
And it also has a bunch of bugs like this one in our modeling_vllama3.py file. We start from a pretrained LLM, but for some reason the weights of the head are not loaded from the model. I still don't know why :(
The codebase is full of interesting insights like this one in our dataset.py file: How do you get reproducible randomness in different processes across different machines?
Start different random number generators based on a tuple (seed, rank)!
Start different random number generators based on a tuple (seed, rank)!
January 31, 2025 at 3:06 PM
The codebase is full of interesting insights like this one in our dataset.py file: How do you get reproducible randomness in different processes across different machines?
Start different random number generators based on a tuple (seed, rank)!
Start different random number generators based on a tuple (seed, rank)!
Post training, you can run the evaluation on all of these tasks by running:
sbatch vision/experiments/evaluation/vloom/async_evals_tr_346/run_evals_0_shots_val_2048 . slurm
sbatch vision/experiments/evaluation/vloom/async_evals_tr_346/run_evals_0_shots_val_2048 . slurm
January 31, 2025 at 3:06 PM
Post training, you can run the evaluation on all of these tasks by running:
sbatch vision/experiments/evaluation/vloom/async_evals_tr_346/run_evals_0_shots_val_2048 . slurm
sbatch vision/experiments/evaluation/vloom/async_evals_tr_346/run_evals_0_shots_val_2048 . slurm