



New Blog📖✨:
nanoVLM: The simplest way to train your own Vision-Language Model in pure PyTorch explained step-by-step!
Easy to read, even easier to use. Train your first VLM today!
nanoVLM: The simplest way to train your own Vision-Language Model in pure PyTorch explained step-by-step!
Easy to read, even easier to use. Train your first VLM today!

May 21, 2025 at 1:10 PM
New Blog📖✨:
nanoVLM: The simplest way to train your own Vision-Language Model in pure PyTorch explained step-by-step!
Easy to read, even easier to use. Train your first VLM today!
nanoVLM: The simplest way to train your own Vision-Language Model in pure PyTorch explained step-by-step!
Easy to read, even easier to use. Train your first VLM today!
Real-time SmolVLM in a web browser with transformers.js.
All running locally with no installs. Just open the website.
All running locally with no installs. Just open the website.
May 14, 2025 at 3:39 PM
Real-time SmolVLM in a web browser with transformers.js.
All running locally with no installs. Just open the website.
All running locally with no installs. Just open the website.
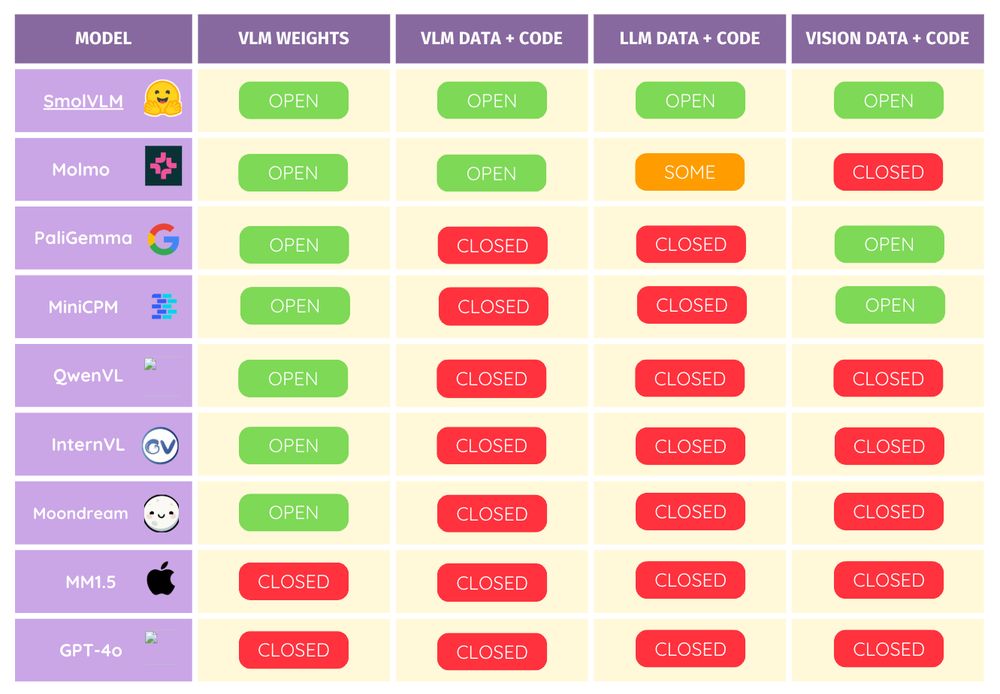
What makes it unique?
📌 Handles everything a document has: tables, charts, code, equations, lists, and more
📌 Works beyond scientific papers—supports business docs, patents, and forms
📌 It runs with less than 1GB of RAM, so running at large batch sizes is super cheap!
📌 Handles everything a document has: tables, charts, code, equations, lists, and more
📌 Works beyond scientific papers—supports business docs, patents, and forms
📌 It runs with less than 1GB of RAM, so running at large batch sizes is super cheap!

March 17, 2025 at 3:53 PM
What makes it unique?
📌 Handles everything a document has: tables, charts, code, equations, lists, and more
📌 Works beyond scientific papers—supports business docs, patents, and forms
📌 It runs with less than 1GB of RAM, so running at large batch sizes is super cheap!
📌 Handles everything a document has: tables, charts, code, equations, lists, and more
📌 Works beyond scientific papers—supports business docs, patents, and forms
📌 It runs with less than 1GB of RAM, so running at large batch sizes is super cheap!
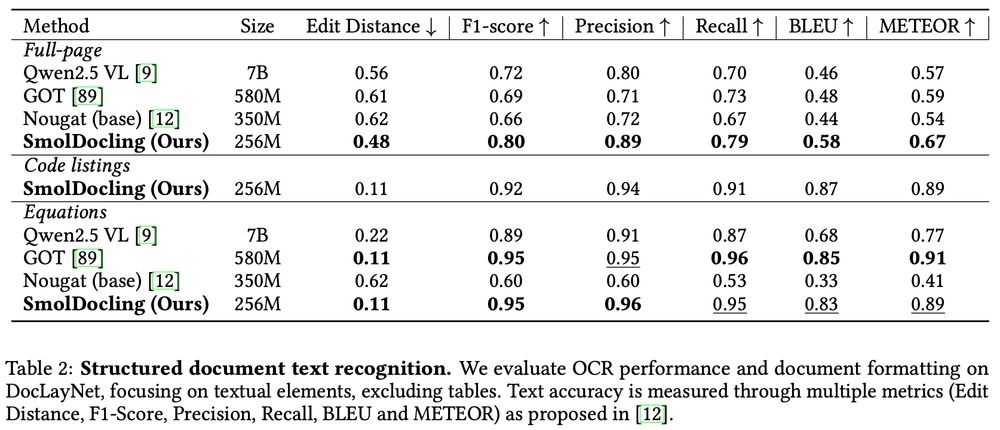
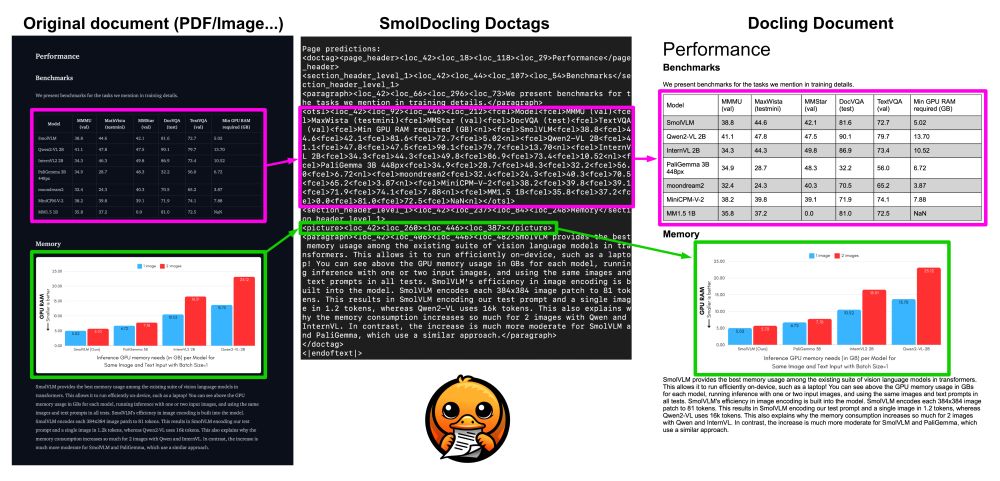
How does SmolDocling beat models 27× bigger? SmolDocling transforms any document into structured metadata with DocTags, being SOTA in:
✅ Full-page conversion
✅ Layout identification
✅ Equations, tables, charts, plots, code OCR
✅ Full-page conversion
✅ Layout identification
✅ Equations, tables, charts, plots, code OCR
March 17, 2025 at 3:53 PM
How does SmolDocling beat models 27× bigger? SmolDocling transforms any document into structured metadata with DocTags, being SOTA in:
✅ Full-page conversion
✅ Layout identification
✅ Equations, tables, charts, plots, code OCR
✅ Full-page conversion
✅ Layout identification
✅ Equations, tables, charts, plots, code OCR
🚀 We just dropped SmolDocling: a 256M open-source vision LM for complete document OCR! 📄✨
Lightning fast, process a page in 0.35 sec on consumer GPU using < 500MB VRAM ⚡
SOTA in document conversion, beating every competing model we tested (including models 27x more params) 🤯
But how? 🧶⬇️
Lightning fast, process a page in 0.35 sec on consumer GPU using < 500MB VRAM ⚡
SOTA in document conversion, beating every competing model we tested (including models 27x more params) 🤯
But how? 🧶⬇️

March 17, 2025 at 3:53 PM
🚀 We just dropped SmolDocling: a 256M open-source vision LM for complete document OCR! 📄✨
Lightning fast, process a page in 0.35 sec on consumer GPU using < 500MB VRAM ⚡
SOTA in document conversion, beating every competing model we tested (including models 27x more params) 🤯
But how? 🧶⬇️
Lightning fast, process a page in 0.35 sec on consumer GPU using < 500MB VRAM ⚡
SOTA in document conversion, beating every competing model we tested (including models 27x more params) 🤯
But how? 🧶⬇️
And it also has a bunch of bugs like this one in our modeling_vllama3.py file. We start from a pretrained LLM, but for some reason the weights of the head are not loaded from the model. I still don't know why :(

January 31, 2025 at 3:06 PM
And it also has a bunch of bugs like this one in our modeling_vllama3.py file. We start from a pretrained LLM, but for some reason the weights of the head are not loaded from the model. I still don't know why :(
The codebase is full of interesting insights like this one in our dataset.py file: How do you get reproducible randomness in different processes across different machines?
Start different random number generators based on a tuple (seed, rank)!
Start different random number generators based on a tuple (seed, rank)!
January 31, 2025 at 3:06 PM
The codebase is full of interesting insights like this one in our dataset.py file: How do you get reproducible randomness in different processes across different machines?
Start different random number generators based on a tuple (seed, rank)!
Start different random number generators based on a tuple (seed, rank)!
Post training, you can run the evaluation on all of these tasks by running:
sbatch vision/experiments/evaluation/vloom/async_evals_tr_346/run_evals_0_shots_val_2048 . slurm
sbatch vision/experiments/evaluation/vloom/async_evals_tr_346/run_evals_0_shots_val_2048 . slurm
January 31, 2025 at 3:06 PM
Post training, you can run the evaluation on all of these tasks by running:
sbatch vision/experiments/evaluation/vloom/async_evals_tr_346/run_evals_0_shots_val_2048 . slurm
sbatch vision/experiments/evaluation/vloom/async_evals_tr_346/run_evals_0_shots_val_2048 . slurm
Launching the training for SmolVLM 256M is as simple as:
./vision/experiments/pretraining/vloom/tr_341_smolvlm_025b_1st_stage/01_launch . sh
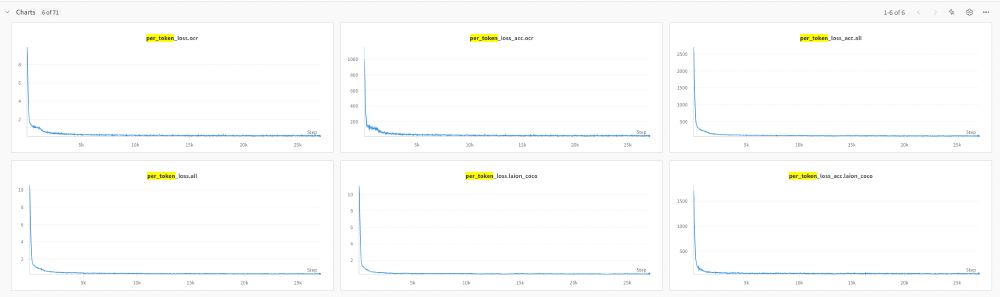
Then we use wandb to track the losses.
Check out the file to find out details!
./vision/experiments/pretraining/vloom/tr_341_smolvlm_025b_1st_stage/01_launch . sh
Then we use wandb to track the losses.
Check out the file to find out details!
January 31, 2025 at 3:06 PM
Launching the training for SmolVLM 256M is as simple as:
./vision/experiments/pretraining/vloom/tr_341_smolvlm_025b_1st_stage/01_launch . sh
Then we use wandb to track the losses.
Check out the file to find out details!
./vision/experiments/pretraining/vloom/tr_341_smolvlm_025b_1st_stage/01_launch . sh
Then we use wandb to track the losses.
Check out the file to find out details!
Fuck it, today we're open-sourcing the codebase used to train SmolVLM from scratch on 256 H100s 🔥
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
January 31, 2025 at 3:06 PM
Fuck it, today we're open-sourcing the codebase used to train SmolVLM from scratch on 256 H100s 🔥
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
Inspired by our team's effort to open-source DeepSeek's R1, we are releasing the training and evaluation code on top of the weights 🫡
Now you can train any SmolVLM—or create your own custom VLMs!
SmolVLM upgrades:
• New vision encoder: Smaller but higher res.
• Improved data mixtures: better OCR and doc understanding.
• Higher pixels/token: 4096 vs. 1820 = more efficient.
• Smart tokenization: Faster training and better performance. 🚀
Better, faster, smarter.
• New vision encoder: Smaller but higher res.
• Improved data mixtures: better OCR and doc understanding.
• Higher pixels/token: 4096 vs. 1820 = more efficient.
• Smart tokenization: Faster training and better performance. 🚀
Better, faster, smarter.
January 23, 2025 at 1:33 PM
SmolVLM upgrades:
• New vision encoder: Smaller but higher res.
• Improved data mixtures: better OCR and doc understanding.
• Higher pixels/token: 4096 vs. 1820 = more efficient.
• Smart tokenization: Faster training and better performance. 🚀
Better, faster, smarter.
• New vision encoder: Smaller but higher res.
• Improved data mixtures: better OCR and doc understanding.
• Higher pixels/token: 4096 vs. 1820 = more efficient.
• Smart tokenization: Faster training and better performance. 🚀
Better, faster, smarter.
We have partnered with IBM 's Docling to build amazing smol models for document understanding. Our early results are amazing. Stay tuned for future releases!
January 23, 2025 at 1:33 PM
We have partnered with IBM 's Docling to build amazing smol models for document understanding. Our early results are amazing. Stay tuned for future releases!
Our models are integrated into ColiPali, delivering SOTA retrieval speeds with performance rivaling models 10x their size. 🏃♂️💨
SmolVLM makes it faster and cheaper to build searchable databases.
Real-world impact, unlocked.
SmolVLM makes it faster and cheaper to build searchable databases.
Real-world impact, unlocked.

January 23, 2025 at 1:33 PM
Our models are integrated into ColiPali, delivering SOTA retrieval speeds with performance rivaling models 10x their size. 🏃♂️💨
SmolVLM makes it faster and cheaper to build searchable databases.
Real-world impact, unlocked.
SmolVLM makes it faster and cheaper to build searchable databases.
Real-world impact, unlocked.
Smol but mighty:
• 256M delivers 80% of the performance of our 2.2B model.
• 500M hits 90%.
Both beat our SOTA 80B model from 17 months ago! 🎉
Efficiency 🤝 Performance
Explore the collection here: huggingface.co/collections/...
Blog: huggingface.co/blog/smolervlm
• 256M delivers 80% of the performance of our 2.2B model.
• 500M hits 90%.
Both beat our SOTA 80B model from 17 months ago! 🎉
Efficiency 🤝 Performance
Explore the collection here: huggingface.co/collections/...
Blog: huggingface.co/blog/smolervlm

January 23, 2025 at 1:33 PM
Smol but mighty:
• 256M delivers 80% of the performance of our 2.2B model.
• 500M hits 90%.
Both beat our SOTA 80B model from 17 months ago! 🎉
Efficiency 🤝 Performance
Explore the collection here: huggingface.co/collections/...
Blog: huggingface.co/blog/smolervlm
• 256M delivers 80% of the performance of our 2.2B model.
• 500M hits 90%.
Both beat our SOTA 80B model from 17 months ago! 🎉
Efficiency 🤝 Performance
Explore the collection here: huggingface.co/collections/...
Blog: huggingface.co/blog/smolervlm
Introducing the smollest VLMs yet! 🤏
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀

January 23, 2025 at 1:33 PM
Introducing the smollest VLMs yet! 🤏
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀
SmolVLM (256M & 500M) runs on <1GB GPU memory.
Fine-tune it on your laptop and run it on your toaster. 🚀
Even the 256M model outperforms our Idefics 80B (Aug '23).
How small can we go? 👀
Check out more!
Demo: huggingface.co/spaces/Huggi...
Blog:
Model: huggingface.co/HuggingFaceT...
Fine-tuning script: github.com/huggingface/...
Demo: huggingface.co/spaces/Huggi...
Blog:
Model: huggingface.co/HuggingFaceT...
Fine-tuning script: github.com/huggingface/...

November 26, 2024 at 3:57 PM
Check out more!
Demo: huggingface.co/spaces/Huggi...
Blog:
Model: huggingface.co/HuggingFaceT...
Fine-tuning script: github.com/huggingface/...
Demo: huggingface.co/spaces/Huggi...
Blog:
Model: huggingface.co/HuggingFaceT...
Fine-tuning script: github.com/huggingface/...
When comparing the performance with other small VLMs, SmolVLM is only behind Qwen2-VL.
These two models have the same number of parameters, but Qwen2-VL expensive image encoding makes it unsuited for on-device applications!
These two models have the same number of parameters, but Qwen2-VL expensive image encoding makes it unsuited for on-device applications!

November 26, 2024 at 3:57 PM
When comparing the performance with other small VLMs, SmolVLM is only behind Qwen2-VL.
These two models have the same number of parameters, but Qwen2-VL expensive image encoding makes it unsuited for on-device applications!
These two models have the same number of parameters, but Qwen2-VL expensive image encoding makes it unsuited for on-device applications!
SmolVLM tiny memory footprint compared to similarly sized models enables it to be run on-device!
Qwen2-VL crashes my MacBook pro M3, but we get 17 tokens per second with SmolVLM and MLX!
Qwen2-VL crashes my MacBook pro M3, but we get 17 tokens per second with SmolVLM and MLX!

November 26, 2024 at 3:57 PM
SmolVLM tiny memory footprint compared to similarly sized models enables it to be run on-device!
Qwen2-VL crashes my MacBook pro M3, but we get 17 tokens per second with SmolVLM and MLX!
Qwen2-VL crashes my MacBook pro M3, but we get 17 tokens per second with SmolVLM and MLX!
Compared to Qwen2-VL 2B, SmolVLM generates tokens 7.5 to 16 times faster! This is due to SmolVLM striking a great balance between performance and inference speed.

November 26, 2024 at 3:57 PM
Compared to Qwen2-VL 2B, SmolVLM generates tokens 7.5 to 16 times faster! This is due to SmolVLM striking a great balance between performance and inference speed.
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!