



Lewis Tunstall
@lewtun.bsky.social
🤗 LLM whisperer @huggingface
📖 Co-author of "NLP with Transformers" book
💥 Ex-particle physicist
🤘 Occasional guitarist
🇦🇺 in 🇨🇭
📖 Co-author of "NLP with Transformers" book
💥 Ex-particle physicist
🤘 Occasional guitarist
🇦🇺 in 🇨🇭
Introducing OpenR1-Math-220k!
huggingface.co/datasets/ope...
The community has been busy distilling DeepSeek-R1 from inference providers, but we decided to have a go at doing it ourselves from scratch 💪
More details in 🧵
huggingface.co/datasets/ope...
The community has been busy distilling DeepSeek-R1 from inference providers, but we decided to have a go at doing it ourselves from scratch 💪
More details in 🧵

open-r1/OpenR1-Math-220k · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
February 10, 2025 at 6:09 PM
Introducing OpenR1-Math-220k!
huggingface.co/datasets/ope...
The community has been busy distilling DeepSeek-R1 from inference providers, but we decided to have a go at doing it ourselves from scratch 💪
More details in 🧵
huggingface.co/datasets/ope...
The community has been busy distilling DeepSeek-R1 from inference providers, but we decided to have a go at doing it ourselves from scratch 💪
More details in 🧵
We are reproducing the full DeepSeek R1 data and training pipeline so everybody can use their recipe. Instead of doing it in secret we can do it together in the open!
Follow along: github.com/huggingface/...
Follow along: github.com/huggingface/...

GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1
Fully open reproduction of DeepSeek-R1. Contribute to huggingface/open-r1 development by creating an account on GitHub.
github.com
January 25, 2025 at 1:29 PM
We are reproducing the full DeepSeek R1 data and training pipeline so everybody can use their recipe. Instead of doing it in secret we can do it together in the open!
Follow along: github.com/huggingface/...
Follow along: github.com/huggingface/...
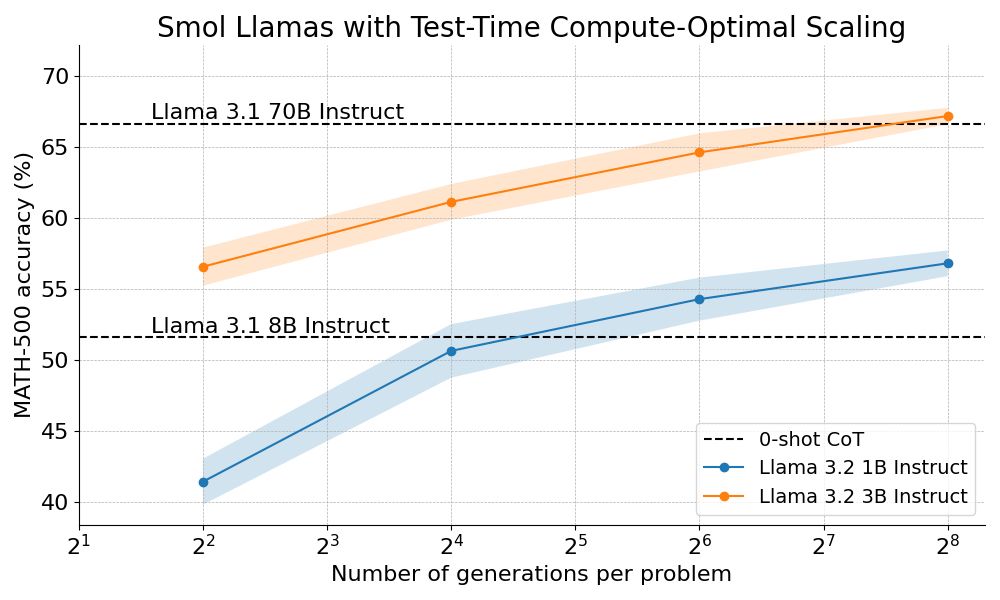
We outperform Llama 70B with Llama 3B on hard math by scaling test-time compute 🔥
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
December 16, 2024 at 5:08 PM
We outperform Llama 70B with Llama 3B on hard math by scaling test-time compute 🔥
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
How? By combining step-wise reward models with tree search algorithms :)
We're open sourcing the full recipe and sharing a detailed blog post 👇
Hey ML peeps, we found a nice extension to beam search at Hugging Face that is far more scalable and produces more diverse candidates
The basic idea is to split your N beams into N/M subtrees and then run greedy node selection in parallel
Does anyone know what this algorithm is called?

December 12, 2024 at 10:15 AM
Hey ML peeps, we found a nice extension to beam search at Hugging Face that is far more scalable and produces more diverse candidates
The basic idea is to split your N beams into N/M subtrees and then run greedy node selection in parallel
Does anyone know what this algorithm is called?