



Loubna Ben Allal
@loubnabnl.hf.co
SmolLMs & Data @huggingface
Training SmolLMs and curating high quality web and synthetic datasets ✨
https://loubnabnl.github.io/
Training SmolLMs and curating high quality web and synthetic datasets ✨
https://loubnabnl.github.io/
We built code datasets, English datasets, and now it’s time for math! 🚀
Check out Anton’s thread to learn how we curated the best public math pre-training dataset.
Check out Anton’s thread to learn how we curated the best public math pre-training dataset.
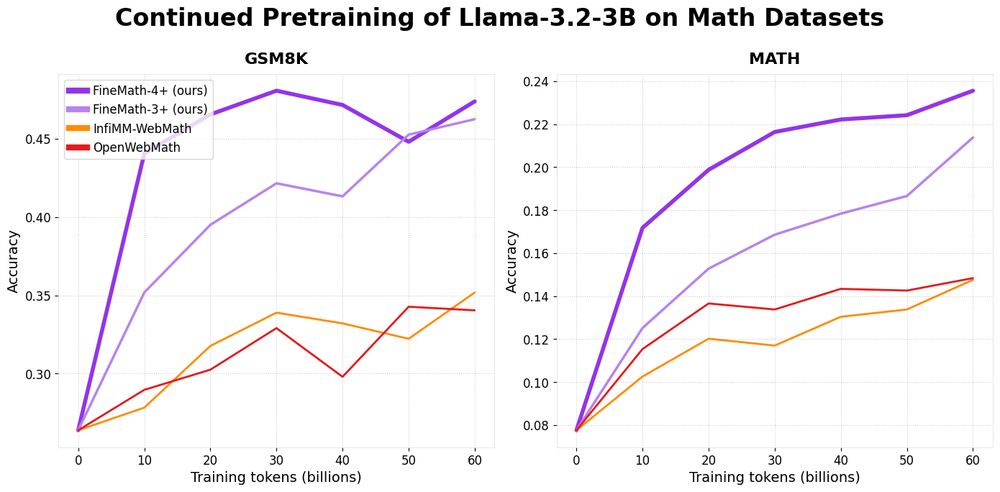
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
December 19, 2024 at 4:02 PM
We built code datasets, English datasets, and now it’s time for math! 🚀
Check out Anton’s thread to learn how we curated the best public math pre-training dataset.
Check out Anton’s thread to learn how we curated the best public math pre-training dataset.
Sharing my slides on "Synthetic data and smol models in 2024" from yesterday's Latent Space event at NeurIPS: docs.google.com/presentation...
- Synthetic data is everywhere
- Model collapse, is the web polluted?
- 3B+ models running on your iPhone
- When and why use smol models?
- Synthetic data is everywhere
- Model collapse, is the web polluted?
- 3B+ models running on your iPhone
- When and why use smol models?

Synthetic data & Smol models in 2024
Loubna Ben Allal Hugging Face Synthetic data and smol models in 2024 loubnabnl LoubnaBenAllal1
docs.google.com
December 12, 2024 at 2:54 PM
Sharing my slides on "Synthetic data and smol models in 2024" from yesterday's Latent Space event at NeurIPS: docs.google.com/presentation...
- Synthetic data is everywhere
- Model collapse, is the web polluted?
- 3B+ models running on your iPhone
- When and why use smol models?
- Synthetic data is everywhere
- Model collapse, is the web polluted?
- 3B+ models running on your iPhone
- When and why use smol models?
Reposted by Loubna Ben Allal

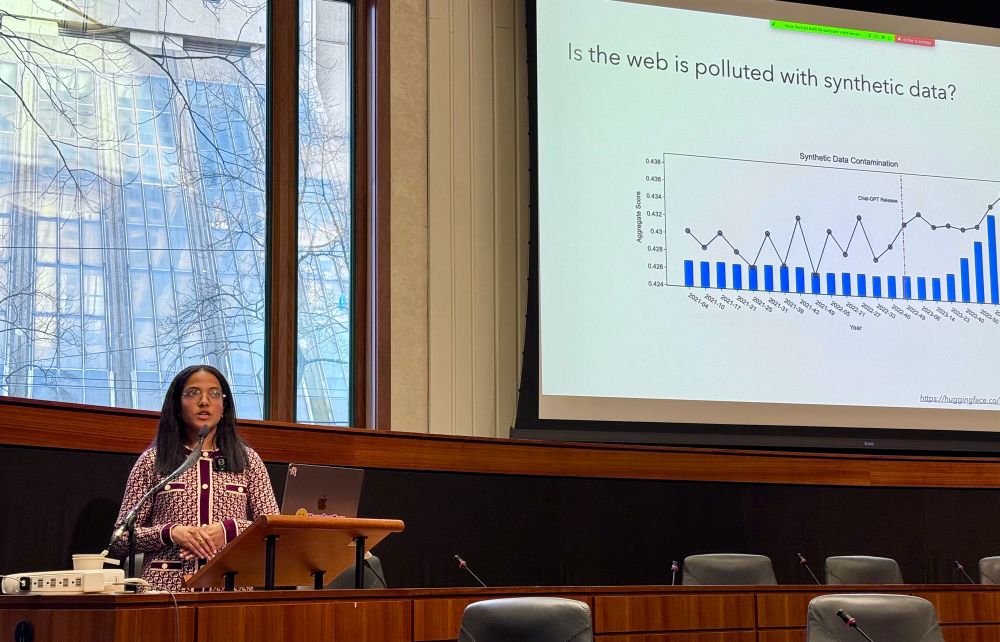
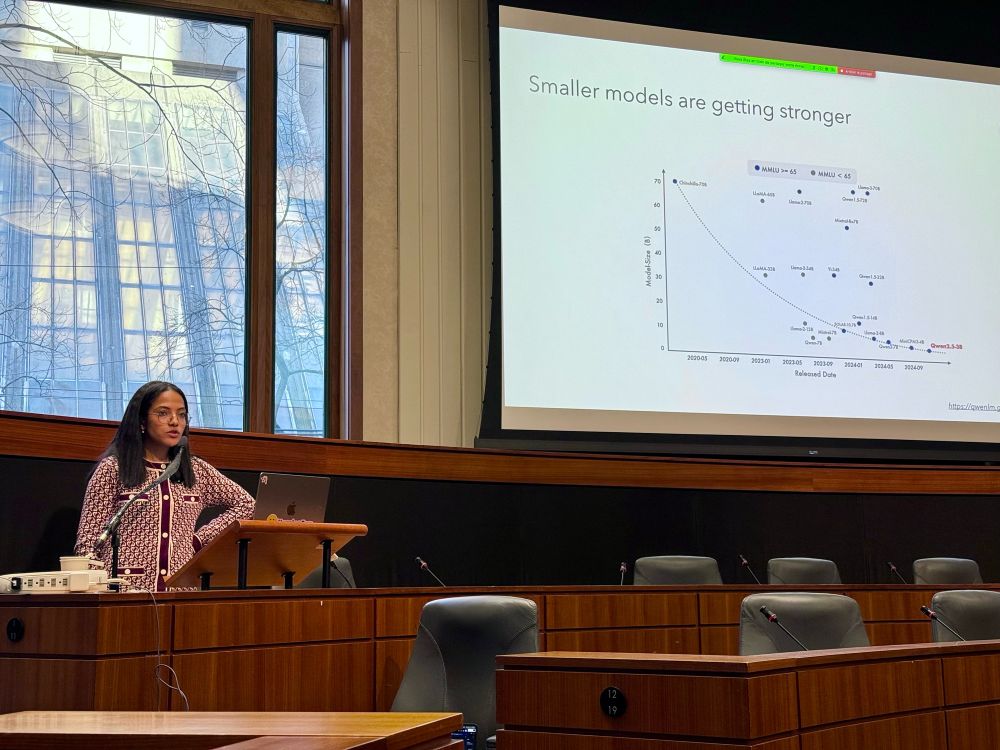
Another great talk at @latentspacepod.bsky.social NeurIPS: @loubnabnl.hf.co on Synthetic Data & Smol Models
December 11, 2024 at 10:45 PM
Another great talk at @latentspacepod.bsky.social NeurIPS: @loubnabnl.hf.co on Synthetic Data & Smol Models
Reposted by Loubna Ben Allal

For anyone interested in fine-tuning or aligning LLMs, I’m running this free and open course called smol course. It’s not a big deal, it’s just smol.
🧵>>
🧵>>
December 3, 2024 at 9:21 AM
For anyone interested in fine-tuning or aligning LLMs, I’m running this free and open course called smol course. It’s not a big deal, it’s just smol.
🧵>>
🧵>>

We hit 1K ⭐ on our SmolLM repo—thank you! 🎉 New updates:
• SmolLM2 nanotron checkpoints (with optimizer states) for easier continual pre-training
• Local inference demos (MLC, Transformers.js, MLX, llama.cpp)
• SmolVLM: Vision-language model built on SmolLM2
github.com/huggingface/...
• SmolLM2 nanotron checkpoints (with optimizer states) for easier continual pre-training
• Local inference demos (MLC, Transformers.js, MLX, llama.cpp)
• SmolVLM: Vision-language model built on SmolLM2
github.com/huggingface/...

December 1, 2024 at 8:00 AM
We hit 1K ⭐ on our SmolLM repo—thank you! 🎉 New updates:
• SmolLM2 nanotron checkpoints (with optimizer states) for easier continual pre-training
• Local inference demos (MLC, Transformers.js, MLX, llama.cpp)
• SmolVLM: Vision-language model built on SmolLM2
github.com/huggingface/...
• SmolLM2 nanotron checkpoints (with optimizer states) for easier continual pre-training
• Local inference demos (MLC, Transformers.js, MLX, llama.cpp)
• SmolVLM: Vision-language model built on SmolLM2
github.com/huggingface/...
📬 Summarize and rewrite your text/emails faster, and offline!
Check @andimara.bsky.social's Smol Tools for summarization and rewriting. It uses SmolLM2 to summarize text and make it more friendly or professional, all running locally thanks to llama.cpp github.com/huggingface/...
Check @andimara.bsky.social's Smol Tools for summarization and rewriting. It uses SmolLM2 to summarize text and make it more friendly or professional, all running locally thanks to llama.cpp github.com/huggingface/...
smollm/smol_tools at main · huggingface/smollm
Everything about the SmolLM & SmolLM2 family of models - huggingface/smollm
github.com
November 30, 2024 at 3:59 PM
📬 Summarize and rewrite your text/emails faster, and offline!
Check @andimara.bsky.social's Smol Tools for summarization and rewriting. It uses SmolLM2 to summarize text and make it more friendly or professional, all running locally thanks to llama.cpp github.com/huggingface/...
Check @andimara.bsky.social's Smol Tools for summarization and rewriting. It uses SmolLM2 to summarize text and make it more friendly or professional, all running locally thanks to llama.cpp github.com/huggingface/...
Reposted by Loubna Ben Allal

WOW! 🤯 Language models are becoming smaller and more capable than ever! Here's SmolLM2 running 100% locally in-browser w/ WebGPU on a 6-year-old GPU. Just look at that speed! ⚡️😍
Powered by 🤗 Transformers.js and ONNX Runtime Web!
How many tokens/second do you get? Let me know! 👇
Powered by 🤗 Transformers.js and ONNX Runtime Web!
How many tokens/second do you get? Let me know! 👇
November 27, 2024 at 1:51 PM
WOW! 🤯 Language models are becoming smaller and more capable than ever! Here's SmolLM2 running 100% locally in-browser w/ WebGPU on a 6-year-old GPU. Just look at that speed! ⚡️😍
Powered by 🤗 Transformers.js and ONNX Runtime Web!
How many tokens/second do you get? Let me know! 👇
Powered by 🤗 Transformers.js and ONNX Runtime Web!
How many tokens/second do you get? Let me know! 👇
Reposted by Loubna Ben Allal

This demo of structured data extraction running on an LLM that executes entirely in the browser (Chrome only for the moment since it uses WebGPU) is amazing
My notes here: simonwillison.net/2024/Nov/29/...
My notes here: simonwillison.net/2024/Nov/29/...
November 29, 2024 at 9:10 PM
This demo of structured data extraction running on an LLM that executes entirely in the browser (Chrome only for the moment since it uses WebGPU) is amazing
My notes here: simonwillison.net/2024/Nov/29/...
My notes here: simonwillison.net/2024/Nov/29/...
Reposted by Loubna Ben Allal

Fuck it! Structured Generation w/ SmolLM2 running in browser & WebGPU 🔥
Powered by MLC Web-LLM & XGrammar ⚡
Define a JSON schema, Input free text, get structured data right in your browser - profit!!
Powered by MLC Web-LLM & XGrammar ⚡
Define a JSON schema, Input free text, get structured data right in your browser - profit!!
November 28, 2024 at 10:24 PM
Fuck it! Structured Generation w/ SmolLM2 running in browser & WebGPU 🔥
Powered by MLC Web-LLM & XGrammar ⚡
Define a JSON schema, Input free text, get structured data right in your browser - profit!!
Powered by MLC Web-LLM & XGrammar ⚡
Define a JSON schema, Input free text, get structured data right in your browser - profit!!
Reposted by Loubna Ben Allal

We’re looking for an intern to join our SmolLM team! If you’re excited about training LLMs and building high-quality datasets, we’d love to hear from you. 🤗
US: apply.workable.com/huggingface/...
EMEA: apply.workable.com/huggingface/...
US: apply.workable.com/huggingface/...
EMEA: apply.workable.com/huggingface/...

ML Research Engineer Internship, SmolLMs pretraining and datasets - EMEA Remote - Hugging Face
Here at Hugging Face, we’re on a journey to advance good Machine Learning and make it more accessible. Along the way, we contribute to the development of technology for the better.We have built the fa...
apply.workable.com
November 27, 2024 at 10:20 AM
We’re looking for an intern to join our SmolLM team! If you’re excited about training LLMs and building high-quality datasets, we’d love to hear from you. 🤗
US: apply.workable.com/huggingface/...
EMEA: apply.workable.com/huggingface/...
US: apply.workable.com/huggingface/...
EMEA: apply.workable.com/huggingface/...
Reposted by Loubna Ben Allal

Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
Reposted by Loubna Ben Allal

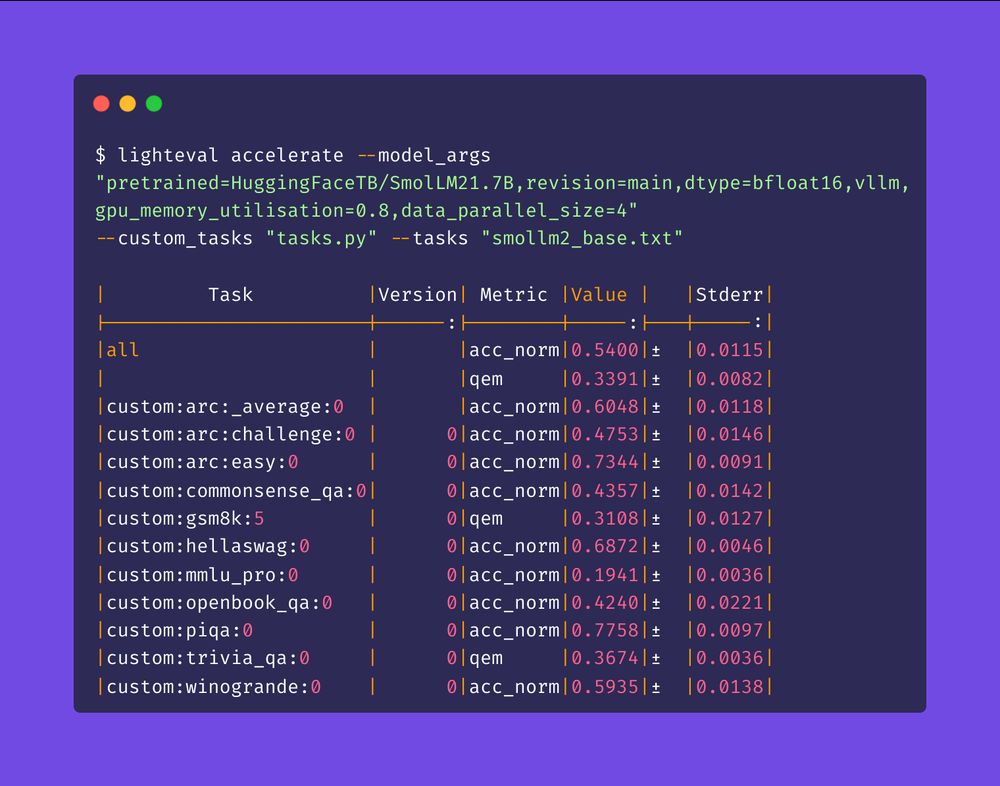
Check out how easy it is to do LLM evals with LightEval!
* any dataset on the 🤗 Hub can become an eval task in a few lines of code: customize the prompt, metrics, parsing, few-shots, everything!
* model- and data-parallel inference
* auto batching with the new vLLM backend
* any dataset on the 🤗 Hub can become an eval task in a few lines of code: customize the prompt, metrics, parsing, few-shots, everything!
* model- and data-parallel inference
* auto batching with the new vLLM backend
November 25, 2024 at 5:24 PM
Check out how easy it is to do LLM evals with LightEval!
* any dataset on the 🤗 Hub can become an eval task in a few lines of code: customize the prompt, metrics, parsing, few-shots, everything!
* model- and data-parallel inference
* auto batching with the new vLLM backend
* any dataset on the 🤗 Hub can become an eval task in a few lines of code: customize the prompt, metrics, parsing, few-shots, everything!
* model- and data-parallel inference
* auto batching with the new vLLM backend
Reposted by Loubna Ben Allal

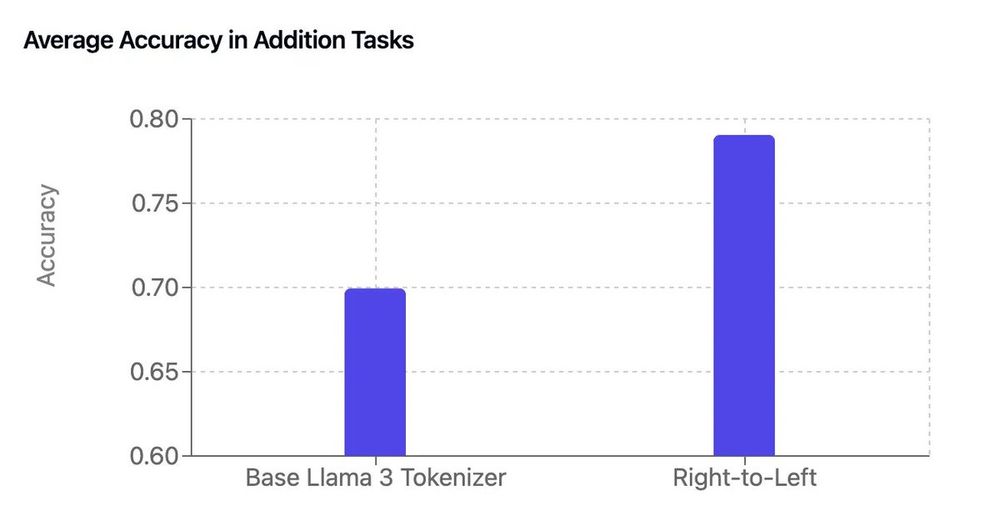
It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
November 24, 2024 at 11:05 AM
It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
Making SmolLM2 more reproducible: open-sourcing our training & evaluation toolkit 🛠️ github.com/huggingface/...
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
GitHub - huggingface/smollm: Everything about the SmolLM & SmolLM2 family of models
Everything about the SmolLM & SmolLM2 family of models - GitHub - huggingface/smollm: Everything about the SmolLM & SmolLM2 family of models
github.com
November 24, 2024 at 7:16 AM
Making SmolLM2 more reproducible: open-sourcing our training & evaluation toolkit 🛠️ github.com/huggingface/...
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Pre-training & evaluation code, synthetic data generation pipelines, post-training scripts, on-device tools & demos
Apache 2.0. V2 data mix coming soon!
Which tools should we add next?
Reposted by Loubna Ben Allal

Excited to announce the SFT dataset used for @huggingface.bsky.social SmolLM2!
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...

HuggingFaceTB/smoltalk · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 21, 2024 at 3:22 PM
Excited to announce the SFT dataset used for @huggingface.bsky.social SmolLM2!
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
The dataset for SmolLM2 was created by combining multiple existing datasets and generating new synthetic datasets, including MagPie Ultra v1.0, using distilabel.
Check out the dataset:
huggingface.co/datasets/Hug...
Reposted by Loubna Ben Allal

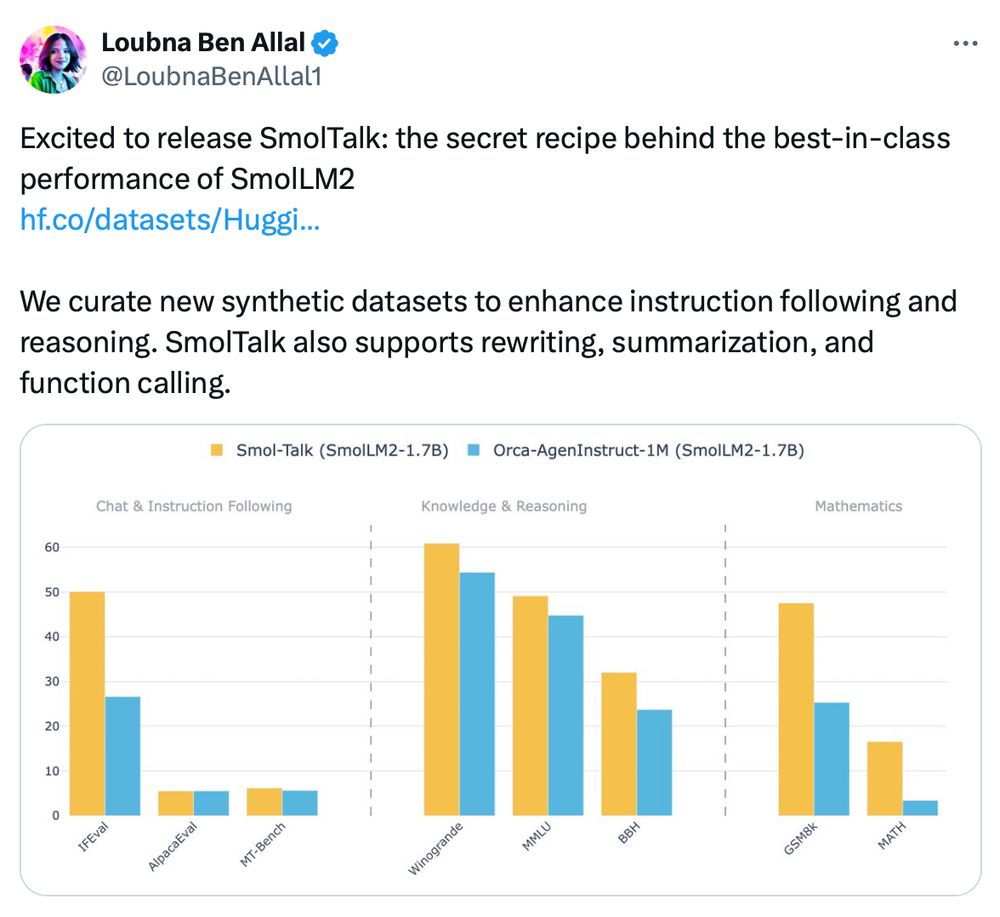
What's the secret sauce of SmolLM2 to beat LLM titans like Llama3.2 and Qwen2.5?
Unsurprisingly: data, data, data!
The SmolTalk is open and available here: huggingface.co/datasets/Hug...
Unsurprisingly: data, data, data!
The SmolTalk is open and available here: huggingface.co/datasets/Hug...
November 21, 2024 at 2:17 PM
What's the secret sauce of SmolLM2 to beat LLM titans like Llama3.2 and Qwen2.5?
Unsurprisingly: data, data, data!
The SmolTalk is open and available here: huggingface.co/datasets/Hug...
Unsurprisingly: data, data, data!
The SmolTalk is open and available here: huggingface.co/datasets/Hug...