Adhiraj Ghosh@ACL2025
@adhirajghosh.bsky.social
1.5K followers
420 following
78 posts
ELLIS PhD, University of Tübingen | Data-centric Vision and Language @bethgelab.bsky.social
Website: adhirajghosh.github.io
Twitter: https://x.com/adhiraj_ghosh98
Posts
Media
Videos
Starter Packs
Pinned


I wrote something up for AI people who want to get into bluesky and either couldn't assemble an exciting feed or gave up doomscrolling when their Following feed switched to talking politics 24/7.

The AI Researcher's Guide to a Non-Boring Bluesky Feed | Naomi Saphra
How to migrate to bsky without a boring feed.
nsaphra.net
Reposted by Adhiraj Ghosh@ACL2025


Reposted by Adhiraj Ghosh@ACL2025

Reposted by Adhiraj Ghosh@ACL2025


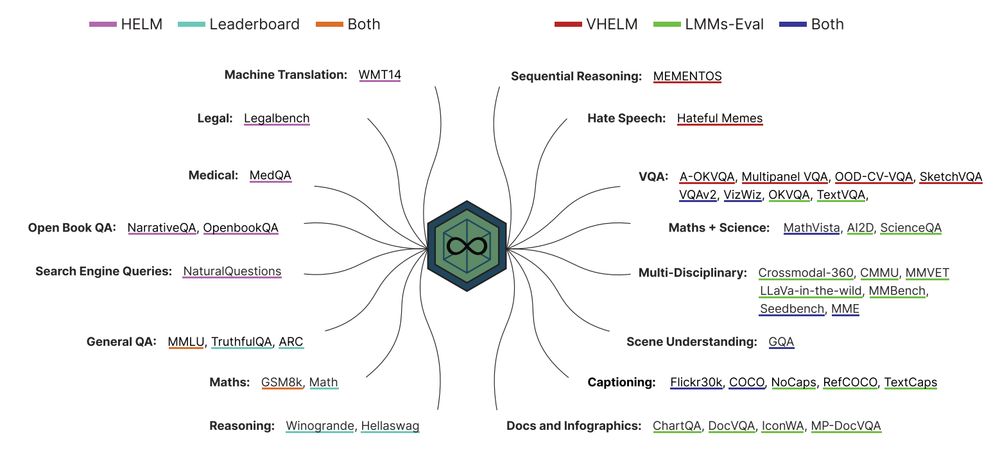
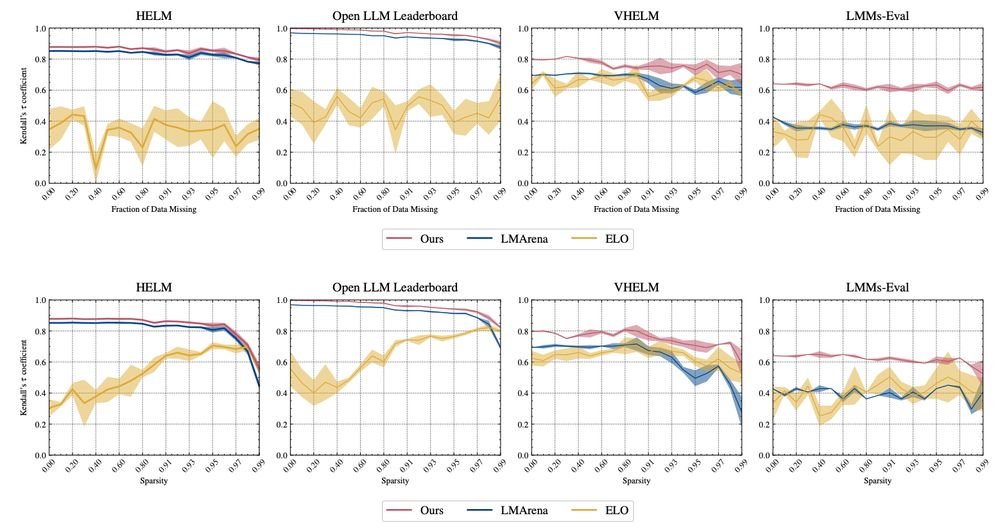
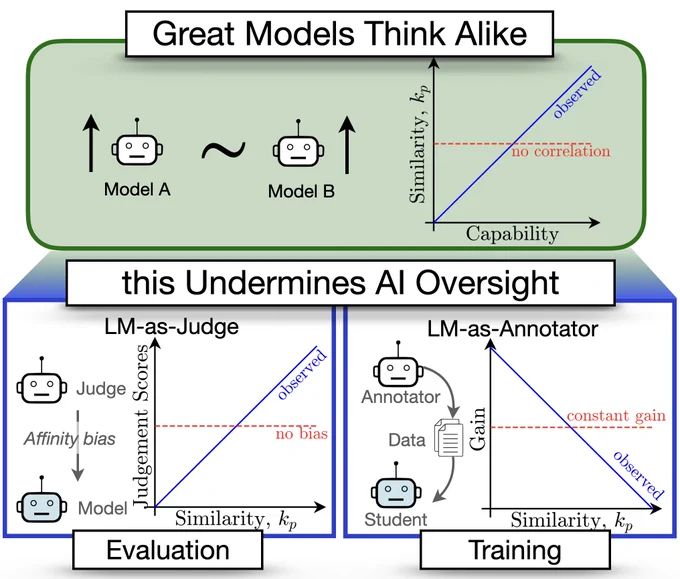
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745

Reposted by Adhiraj Ghosh@ACL2025


Reposted by Adhiraj Ghosh@ACL2025

Thaddäus Wiedemer
@thwiedemer.bsky.social
· Feb 18

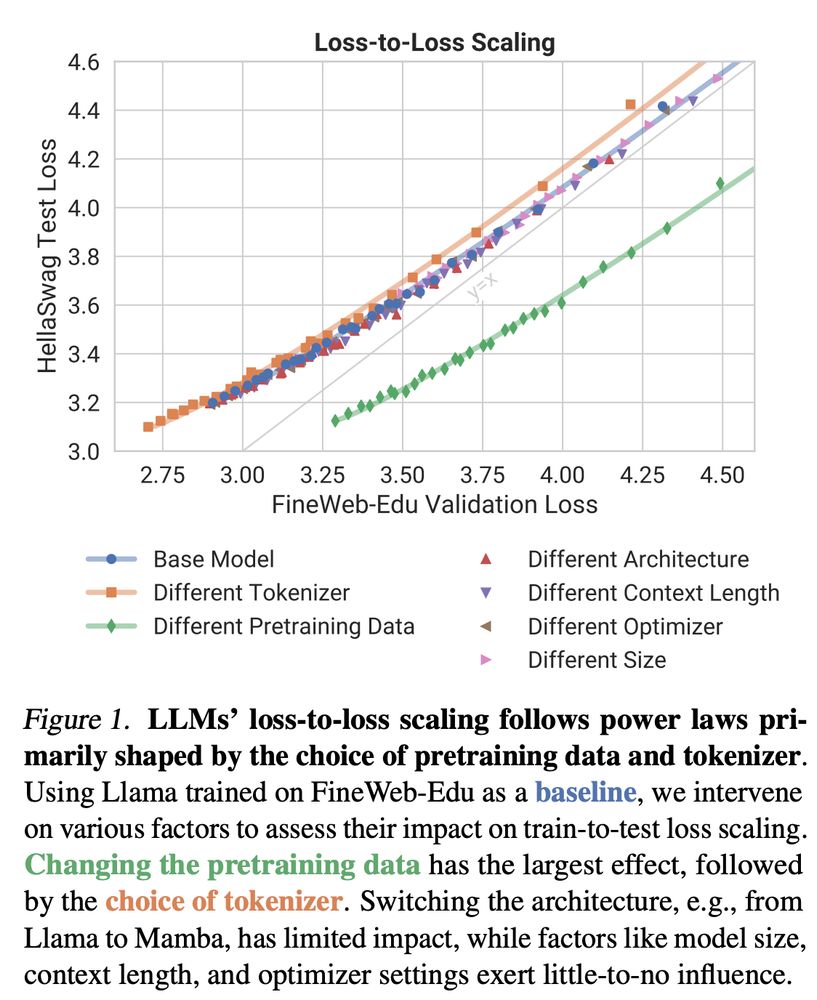
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
Reposted by Adhiraj Ghosh@ACL2025


I started a blog! First post is everything I know about setting up (fast, reproducible, error-proof) Python project environments using the latest tools. These methods have saved me a lot of grief. Also a short guide to CUDA in appendix :)
blog.apoorvkh.com/posts/projec...
blog.apoorvkh.com/posts/projec...
Managing Project Dependencies
blog.apoorvkh.com
Reposted by Adhiraj Ghosh@ACL2025

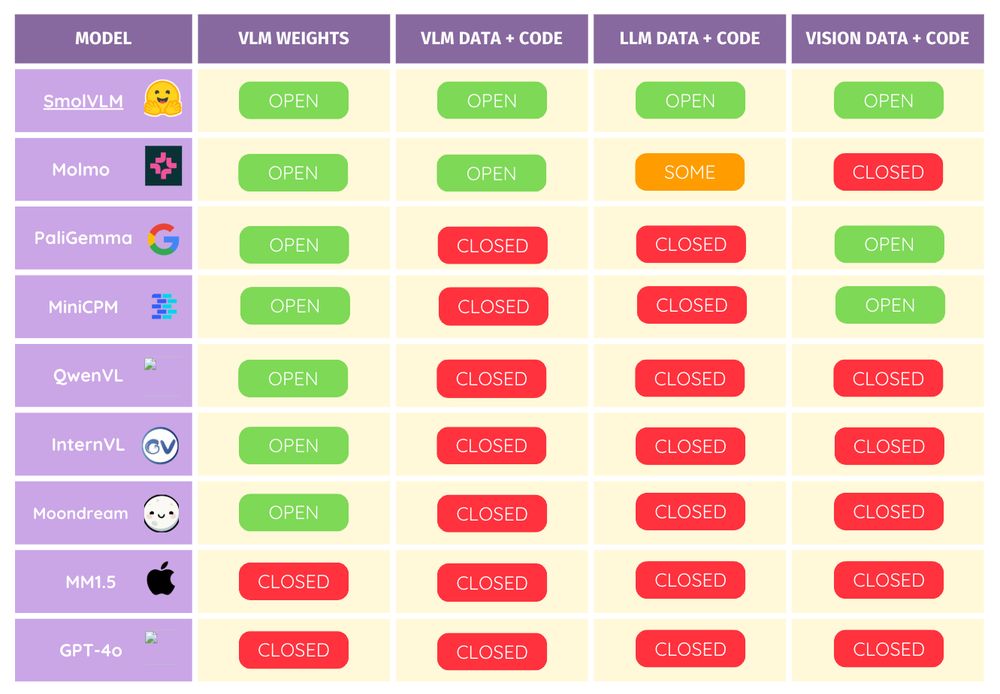
Reposted by Adhiraj Ghosh@ACL2025

Reposted by Adhiraj Ghosh@ACL2025

Sebastian Dziadzio
@dziadzio.bsky.social
· Dec 11

How to Merge Your Multimodal Models Over Time?
Model merging combines multiple expert models - finetuned from a base foundation model on diverse tasks and domains - into a single, more capable model. However, most existing model merging approaches...
arxiv.org
Reposted by Adhiraj Ghosh@ACL2025
Ameya P.
@bayesiankitten.bsky.social
· Dec 10
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745