



Shyamgopal Karthik
@shyamgopal.bsky.social
PhD at Tübingen. Working on post-training diffusion and multimodal models. Previous research interns at Snapchat and Naver Labs.
https://sgk98.github.io/
https://sgk98.github.io/
Reposted by Shyamgopal Karthik

This has now been accepted at @iclr-conf.bsky.social !
Unfortunately, our submission to #NeurIPS didn’t go through with (5,4,4,3). But because I think it’s an excellent paper, I decided to share it anyway.
We show how to efficiently apply Bayesian learning in VLMs, improve calibration, and do active learning. Cool stuff!
📝 arxiv.org/abs/2412.06014
We show how to efficiently apply Bayesian learning in VLMs, improve calibration, and do active learning. Cool stuff!
📝 arxiv.org/abs/2412.06014

Post-hoc Probabilistic Vision-Language Models
Vision-language models (VLMs), such as CLIP and SigLIP, have found remarkable success in classification, retrieval, and generative tasks. For this, VLMs deterministically map images and text descripti...
arxiv.org
January 26, 2026 at 3:52 PM
This has now been accepted at @iclr-conf.bsky.social !
Was a very fun (and quick) investigation into biases of multimodal benchmarks, this time on tasks designed for "Spatial Supersensing" introduced by Cambrian-S with some great folks!

November 25, 2025 at 7:48 AM
Was a very fun (and quick) investigation into biases of multimodal benchmarks, this time on tasks designed for "Spatial Supersensing" introduced by Cambrian-S with some great folks!
Reposted by Shyamgopal Karthik

🚨 New Paper: "Solving Spatial Supersensing Without Spatial Supersensing"
Huge credit to the Cambrian-S team for tackling one of the hardest open problems in video understanding: spatial supersensing. In our paper, we take a closer look at their benchmarks & methods 👇
Huge credit to the Cambrian-S team for tackling one of the hardest open problems in video understanding: spatial supersensing. In our paper, we take a closer look at their benchmarks & methods 👇

November 24, 2025 at 5:19 PM
🚨 New Paper: "Solving Spatial Supersensing Without Spatial Supersensing"
Huge credit to the Cambrian-S team for tackling one of the hardest open problems in video understanding: spatial supersensing. In our paper, we take a closer look at their benchmarks & methods 👇
Huge credit to the Cambrian-S team for tackling one of the hardest open problems in video understanding: spatial supersensing. In our paper, we take a closer look at their benchmarks & methods 👇
Reposted by Shyamgopal Karthik
Unfortunately, our submission to #NeurIPS didn’t go through with (5,4,4,3). But because I think it’s an excellent paper, I decided to share it anyway.
We show how to efficiently apply Bayesian learning in VLMs, improve calibration, and do active learning. Cool stuff!
📝 arxiv.org/abs/2412.06014
We show how to efficiently apply Bayesian learning in VLMs, improve calibration, and do active learning. Cool stuff!
📝 arxiv.org/abs/2412.06014
Post-hoc Probabilistic Vision-Language Models
Vision-language models (VLMs), such as CLIP and SigLIP, have found remarkable success in classification, retrieval, and generative tasks. For this, VLMs deterministically map images and text descripti...
arxiv.org
September 18, 2025 at 8:34 PM
Unfortunately, our submission to #NeurIPS didn’t go through with (5,4,4,3). But because I think it’s an excellent paper, I decided to share it anyway.
We show how to efficiently apply Bayesian learning in VLMs, improve calibration, and do active learning. Cool stuff!
📝 arxiv.org/abs/2412.06014
We show how to efficiently apply Bayesian learning in VLMs, improve calibration, and do active learning. Cool stuff!
📝 arxiv.org/abs/2412.06014
Wonderful story behind some very nice SSL work!

1/ New & old work on self-supervised representation learning (SSL) with ViTs:
MOCA ☕ - Predicting Masked Online Codebook Assignments w/ @spyrosgidaris.bsky.social O. Simeoni, A. Vobecky, @matthieucord.bsky.social, N. Komodakis, @ptrkprz.bsky.social #TMLR #ICLR2025
Grab a ☕ & brace for a story & a🧵
MOCA ☕ - Predicting Masked Online Codebook Assignments w/ @spyrosgidaris.bsky.social O. Simeoni, A. Vobecky, @matthieucord.bsky.social, N. Komodakis, @ptrkprz.bsky.social #TMLR #ICLR2025
Grab a ☕ & brace for a story & a🧵

June 27, 2025 at 8:24 AM
Wonderful story behind some very nice SSL work!
Reposted by Shyamgopal Karthik

We're super happy: Our Cluster of Excellence will continue to receive funding from the German Research Foundation @dfg.de ! Here’s to 7 more years of exciting research at the intersection of #machinelearning and science! Find out more: uni-tuebingen.de/en/research/... #ExcellenceStrategy

May 22, 2025 at 4:24 PM
We're super happy: Our Cluster of Excellence will continue to receive funding from the German Research Foundation @dfg.de ! Here’s to 7 more years of exciting research at the intersection of #machinelearning and science! Find out more: uni-tuebingen.de/en/research/... #ExcellenceStrategy
Reposted by Shyamgopal Karthik

🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇

March 3, 2025 at 10:19 AM
🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
These are some ridiculously good results from training tiny T2I models purely on ImageNet! It's almost too good to be true. Do check it out!
Check out our latest work on Text-to-Image generation! We've successfully trained a T2I model using only ImageNet data by leveraging captioning and data augmentation.
🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
March 3, 2025 at 10:46 AM
These are some ridiculously good results from training tiny T2I models purely on ImageNet! It's almost too good to be true. Do check it out!
Reposted by Shyamgopal Karthik

I've been talking about writing this paper to anyone who would listen since 2020. I bombed a bunch of job talks trying to convince companies to work on this. It's so nice to finally just be able to say, yes, self-play RL in a diverse world gives you immense capabilities
arxiv.org/abs/2502.03349
arxiv.org/abs/2502.03349

Robust Autonomy Emerges from Self-Play
Self-play has powered breakthroughs in two-player and multi-player games. Here we show that self-play is a surprisingly effective strategy in another domain. We show that robust and naturalistic drivi...
arxiv.org
February 9, 2025 at 8:01 PM
I've been talking about writing this paper to anyone who would listen since 2020. I bombed a bunch of job talks trying to convince companies to work on this. It's so nice to finally just be able to say, yes, self-play RL in a diverse world gives you immense capabilities
arxiv.org/abs/2502.03349
arxiv.org/abs/2502.03349
Reposted by Shyamgopal Karthik

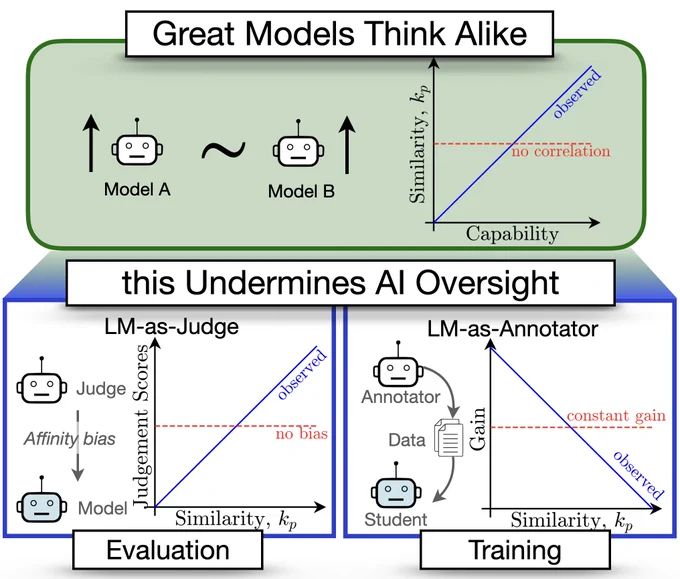
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
February 7, 2025 at 9:12 PM
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
Reposted by Shyamgopal Karthik

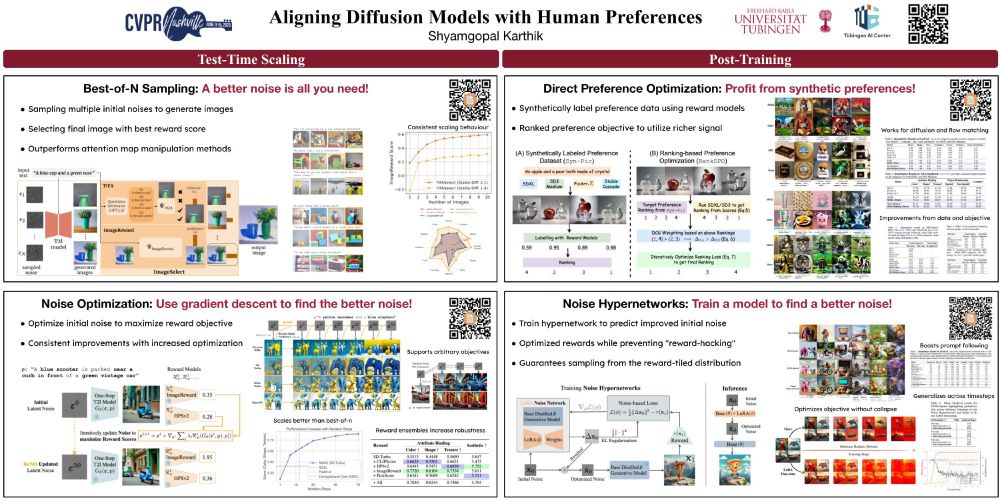
ReNO shows that some initial noise are better for some prompts! This is great to improve image generation, but i think it also shows a deeper property of diffusion models.
Can we enhance the performance of T2I models without any fine-tuning?
We show that with our ReNO, Reward-based Noise Optimization, one-step models consistently surpass the performance of all current open-source Text-to-Image models within the computational budget of 20-50 sec!
#NeurIPS2024
We show that with our ReNO, Reward-based Noise Optimization, one-step models consistently surpass the performance of all current open-source Text-to-Image models within the computational budget of 20-50 sec!
#NeurIPS2024

December 12, 2024 at 11:23 AM
ReNO shows that some initial noise are better for some prompts! This is great to improve image generation, but i think it also shows a deeper property of diffusion models.
Reposted by Shyamgopal Karthik

This is maybe my favorite thing I've seen out of #NeurIPS2024.
Head over to HuggingFace and play with this thing. It's quite extraordinary.
Head over to HuggingFace and play with this thing. It's quite extraordinary.
Thanks to @fffiloni.bsky.social and @natanielruiz.bsky.social, we have a running live Demo of ReNO, play around with it here:
🤗: huggingface.co/spaces/fffil...
We are excited to present ReNO at #NeurIPS2024 this week!
Join us tomorrow from 11am-2pm at East Exhibit Hall A-C #1504!
🤗: huggingface.co/spaces/fffil...
We are excited to present ReNO at #NeurIPS2024 this week!
Join us tomorrow from 11am-2pm at East Exhibit Hall A-C #1504!
December 14, 2024 at 7:32 PM
This is maybe my favorite thing I've seen out of #NeurIPS2024.
Head over to HuggingFace and play with this thing. It's quite extraordinary.
Head over to HuggingFace and play with this thing. It's quite extraordinary.
Reposted by Shyamgopal Karthik

Can we enhance the performance of T2I models without any fine-tuning?
We show that with our ReNO, Reward-based Noise Optimization, one-step models consistently surpass the performance of all current open-source Text-to-Image models within the computational budget of 20-50 sec!
#NeurIPS2024
We show that with our ReNO, Reward-based Noise Optimization, one-step models consistently surpass the performance of all current open-source Text-to-Image models within the computational budget of 20-50 sec!
#NeurIPS2024
December 11, 2024 at 11:05 PM
Can we enhance the performance of T2I models without any fine-tuning?
We show that with our ReNO, Reward-based Noise Optimization, one-step models consistently surpass the performance of all current open-source Text-to-Image models within the computational budget of 20-50 sec!
#NeurIPS2024
We show that with our ReNO, Reward-based Noise Optimization, one-step models consistently surpass the performance of all current open-source Text-to-Image models within the computational budget of 20-50 sec!
#NeurIPS2024
Reposted by Shyamgopal Karthik
I will present ✌️ BDU workshop papers @ NeurIPS: one by Rui Li (looking for internships) and one by Anton Baumann.
🔗 to extended versions:
1. 🙋 "How can we make predictions in BDL efficiently?" 👉 arxiv.org/abs/2411.18425
2. 🙋 "How can we do prob. active learning in VLMs" 👉 arxiv.org/abs/2412.06014
🔗 to extended versions:
1. 🙋 "How can we make predictions in BDL efficiently?" 👉 arxiv.org/abs/2411.18425
2. 🙋 "How can we do prob. active learning in VLMs" 👉 arxiv.org/abs/2412.06014
December 10, 2024 at 3:18 PM
I will present ✌️ BDU workshop papers @ NeurIPS: one by Rui Li (looking for internships) and one by Anton Baumann.
🔗 to extended versions:
1. 🙋 "How can we make predictions in BDL efficiently?" 👉 arxiv.org/abs/2411.18425
2. 🙋 "How can we do prob. active learning in VLMs" 👉 arxiv.org/abs/2412.06014
🔗 to extended versions:
1. 🙋 "How can we make predictions in BDL efficiently?" 👉 arxiv.org/abs/2411.18425
2. 🙋 "How can we do prob. active learning in VLMs" 👉 arxiv.org/abs/2412.06014
After a break of over 2 years, I'm attending a conference again! Excited to attend NeurIPS, even more so to be presenting ReNO, getting inference-time scaling and preference optimization to work for text-to-image generation.
Do reach out if you'd like to chat!
Do reach out if you'd like to chat!

December 9, 2024 at 9:27 PM
After a break of over 2 years, I'm attending a conference again! Excited to attend NeurIPS, even more so to be presenting ReNO, getting inference-time scaling and preference optimization to work for text-to-image generation.
Do reach out if you'd like to chat!
Do reach out if you'd like to chat!
Reposted by Shyamgopal Karthik

🚨New Paper Alert🚨
🚀 Introducing FlowChef, "Steering Rectified Flow Models in the Vector Field for Controlled Image Generation"! 🌌✨
- Perform image editing, solve inverse problems, and more.
- Achieved inversion-free, gradient-free, & training-free inference time steering! 🤯
👇👇
🚀 Introducing FlowChef, "Steering Rectified Flow Models in the Vector Field for Controlled Image Generation"! 🌌✨
- Perform image editing, solve inverse problems, and more.
- Achieved inversion-free, gradient-free, & training-free inference time steering! 🤯
👇👇

December 3, 2024 at 9:10 PM
🚨New Paper Alert🚨
🚀 Introducing FlowChef, "Steering Rectified Flow Models in the Vector Field for Controlled Image Generation"! 🌌✨
- Perform image editing, solve inverse problems, and more.
- Achieved inversion-free, gradient-free, & training-free inference time steering! 🤯
👇👇
🚀 Introducing FlowChef, "Steering Rectified Flow Models in the Vector Field for Controlled Image Generation"! 🌌✨
- Perform image editing, solve inverse problems, and more.
- Achieved inversion-free, gradient-free, & training-free inference time steering! 🤯
👇👇
Reposted by Shyamgopal Karthik

Some recent discussions made me write up a short read on how I think about doing computer vision research when there's clear potential for abuse.
Alternative title: why I decided to stop working on tracking.
Curious about other's thoughts on this.
lb.eyer.be/s/cv-ethics....
Alternative title: why I decided to stop working on tracking.
Curious about other's thoughts on this.
lb.eyer.be/s/cv-ethics....

November 29, 2024 at 2:51 PM
Some recent discussions made me write up a short read on how I think about doing computer vision research when there's clear potential for abuse.
Alternative title: why I decided to stop working on tracking.
Curious about other's thoughts on this.
lb.eyer.be/s/cv-ethics....
Alternative title: why I decided to stop working on tracking.
Curious about other's thoughts on this.
lb.eyer.be/s/cv-ethics....
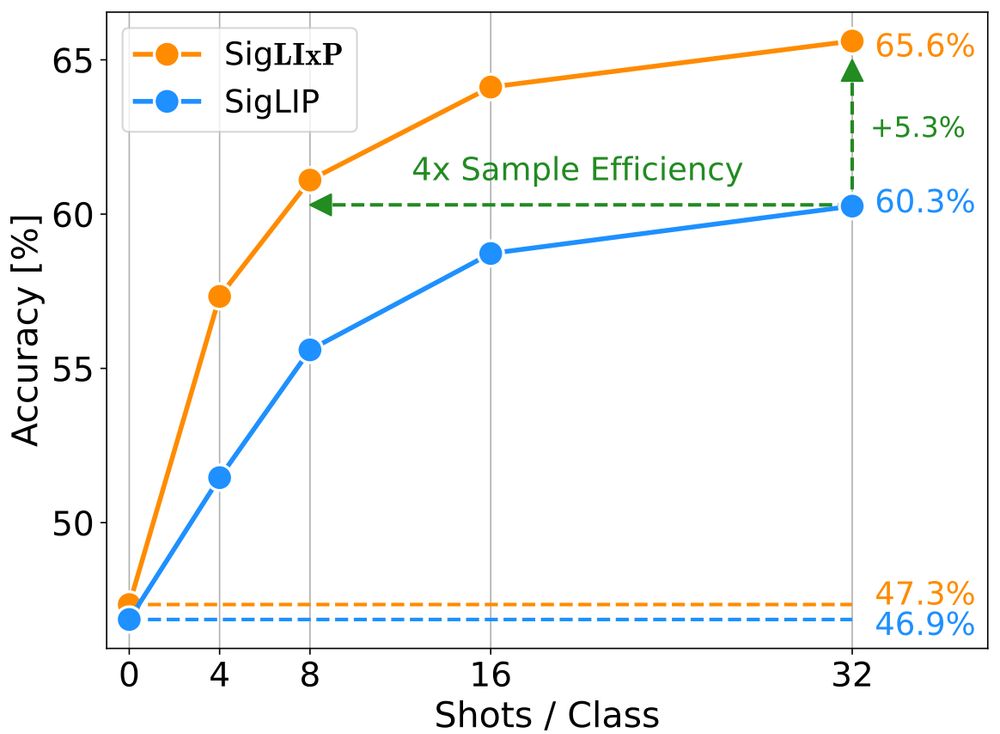
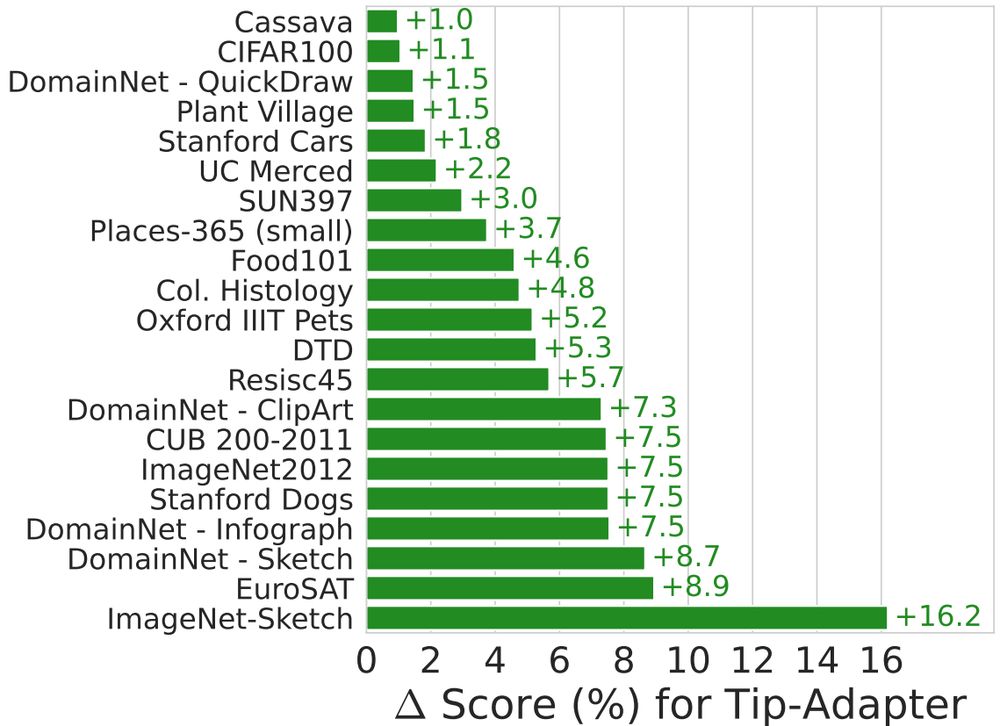
Check out this nice work by @confusezius.bsky.social on designing VLMs for few-shot adaptation!

🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:

November 28, 2024 at 5:07 PM
Check out this nice work by @confusezius.bsky.social on designing VLMs for few-shot adaptation!
Reposted by Shyamgopal Karthik
A real-time (or very fast) open-source txt2video model dropped: LTXV.
HF: huggingface.co/Lightricks/L...
Gradio: huggingface.co/spaces/Light...
Github: github.com/Lightricks/L...
Look at that prompt example though. Need to be a proper writer to get that quality.
HF: huggingface.co/Lightricks/L...
Gradio: huggingface.co/spaces/Light...
Github: github.com/Lightricks/L...
Look at that prompt example though. Need to be a proper writer to get that quality.


November 23, 2024 at 8:03 PM
A real-time (or very fast) open-source txt2video model dropped: LTXV.
HF: huggingface.co/Lightricks/L...
Gradio: huggingface.co/spaces/Light...
Github: github.com/Lightricks/L...
Look at that prompt example though. Need to be a proper writer to get that quality.
HF: huggingface.co/Lightricks/L...
Gradio: huggingface.co/spaces/Light...
Github: github.com/Lightricks/L...
Look at that prompt example though. Need to be a proper writer to get that quality.
Reposted by Shyamgopal Karthik

Learning from one continuous video stream
- use a video stream to learn a predictive model
- everything is in pixel space
- update the model less frequently and don’t use momentum optimizer
- pre training with iid improves performance
- continual learning for robots
arxiv.org/html/2312.00...
- use a video stream to learn a predictive model
- everything is in pixel space
- update the model less frequently and don’t use momentum optimizer
- pre training with iid improves performance
- continual learning for robots
arxiv.org/html/2312.00...
Learning from One Continuous Video Stream
arxiv.org
November 24, 2024 at 11:37 AM
Learning from one continuous video stream
- use a video stream to learn a predictive model
- everything is in pixel space
- update the model less frequently and don’t use momentum optimizer
- pre training with iid improves performance
- continual learning for robots
arxiv.org/html/2312.00...
- use a video stream to learn a predictive model
- everything is in pixel space
- update the model less frequently and don’t use momentum optimizer
- pre training with iid improves performance
- continual learning for robots
arxiv.org/html/2312.00...
Reposted by Shyamgopal Karthik

Here's a fledgling starter pack for the AI community in Tübingen. Let me know if you'd like to be added!
go.bsky.app/NFbVzrA
go.bsky.app/NFbVzrA

Tübingen AI
Join the conversation
go.bsky.app
November 19, 2024 at 1:14 PM
Here's a fledgling starter pack for the AI community in Tübingen. Let me know if you'd like to be added!
go.bsky.app/NFbVzrA
go.bsky.app/NFbVzrA