




Nicolas Dufour
@nicolasdufour.bsky.social
Postdoc at Kyutai
http://nicolas-dufour.github.io
http://nicolas-dufour.github.io
Pinned
Nicolas Dufour
@nicolasdufour.bsky.social
· Oct 31

We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
Reposted by Nicolas Dufour

It was a big pleasure to be in Nicolas's committee. Congratulations to Nicolas for the great work, and congratulations to the advisors too!
November 28, 2025 at 11:49 AM
It was a big pleasure to be in Nicolas's committee. Congratulations to Nicolas for the great work, and congratulations to the advisors too!
Reposted by Nicolas Dufour

Yesterday, @nicolasdufour.bsky.social defended is PhD. I really enjoyed the years of collaboration w/ @vickykalogeiton.bsky.social (& @loicland.bsky.social)
Video: youtube.com/live/DXQ7FZA...
Big thanks to the jury @dlarlus.bsky.social @ptrkprz.bsky.social @gtolias.bsky.social A. Efros & T. Karras
Video: youtube.com/live/DXQ7FZA...
Big thanks to the jury @dlarlus.bsky.social @ptrkprz.bsky.social @gtolias.bsky.social A. Efros & T. Karras
November 27, 2025 at 7:14 PM
Yesterday, @nicolasdufour.bsky.social defended is PhD. I really enjoyed the years of collaboration w/ @vickykalogeiton.bsky.social (& @loicland.bsky.social)
Video: youtube.com/live/DXQ7FZA...
Big thanks to the jury @dlarlus.bsky.social @ptrkprz.bsky.social @gtolias.bsky.social A. Efros & T. Karras
Video: youtube.com/live/DXQ7FZA...
Big thanks to the jury @dlarlus.bsky.social @ptrkprz.bsky.social @gtolias.bsky.social A. Efros & T. Karras
Reposted by Nicolas Dufour

Congrats Nicolas ! On the PhD and on those beautifully crafted slides 🤩
November 27, 2025 at 5:46 PM
Congrats Nicolas ! On the PhD and on those beautifully crafted slides 🤩
Reposted by Nicolas Dufour
Nicolas ( @nicolasdufour.bsky.social ) is defending his PhD right now.
I was so in awe of the presentation that I even forgot to take pictures 😅
I was so in awe of the presentation that I even forgot to take pictures 😅

November 26, 2025 at 6:00 PM
Nicolas ( @nicolasdufour.bsky.social ) is defending his PhD right now.
I was so in awe of the presentation that I even forgot to take pictures 😅
I was so in awe of the presentation that I even forgot to take pictures 😅
Reposted by Nicolas Dufour

Check out our new work: MIRO
No more post-training alignment!
We integrate human alignment right from the start, during pretraining!
Results:
✨ 19x faster convergence ⚡
✨ 370x less compute 💻
🔗 Explore the project: nicolas-dufour.github.io/miro/
No more post-training alignment!
We integrate human alignment right from the start, during pretraining!
Results:
✨ 19x faster convergence ⚡
✨ 370x less compute 💻
🔗 Explore the project: nicolas-dufour.github.io/miro/
October 31, 2025 at 9:11 PM
Check out our new work: MIRO
No more post-training alignment!
We integrate human alignment right from the start, during pretraining!
Results:
✨ 19x faster convergence ⚡
✨ 370x less compute 💻
🔗 Explore the project: nicolas-dufour.github.io/miro/
No more post-training alignment!
We integrate human alignment right from the start, during pretraining!
Results:
✨ 19x faster convergence ⚡
✨ 370x less compute 💻
🔗 Explore the project: nicolas-dufour.github.io/miro/
Reposted by Nicolas Dufour

Image generation becomes much more energy efficient. 👍
We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
October 31, 2025 at 8:28 PM
Image generation becomes much more energy efficient. 👍
Reposted by Nicolas Dufour
I'm super happy about Nicolas' latest work, probably the magnum opus of his PhD.
Read the thread for all the great details.
The main conclusion I draw from this work is that better pretraining, in particular by conditioning on better data, allows us to train SOTA models at a fraction of the cost.
Read the thread for all the great details.
The main conclusion I draw from this work is that better pretraining, in particular by conditioning on better data, allows us to train SOTA models at a fraction of the cost.
We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
October 31, 2025 at 11:39 AM
I'm super happy about Nicolas' latest work, probably the magnum opus of his PhD.
Read the thread for all the great details.
The main conclusion I draw from this work is that better pretraining, in particular by conditioning on better data, allows us to train SOTA models at a fraction of the cost.
Read the thread for all the great details.
The main conclusion I draw from this work is that better pretraining, in particular by conditioning on better data, allows us to train SOTA models at a fraction of the cost.
We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
October 31, 2025 at 11:24 AM
We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
Reposted by Nicolas Dufour

Kickstarting our workshop on Flow matching and Diffusion with a talk by Eric Vanden Eijnden on how to optimize learning and sampling in Stochastic Interpolants!
Broadcast available at gdr-iasis.cnrs.fr/reunions/mod...
Broadcast available at gdr-iasis.cnrs.fr/reunions/mod...


October 24, 2025 at 8:30 AM
Kickstarting our workshop on Flow matching and Diffusion with a talk by Eric Vanden Eijnden on how to optimize learning and sampling in Stochastic Interpolants!
Broadcast available at gdr-iasis.cnrs.fr/reunions/mod...
Broadcast available at gdr-iasis.cnrs.fr/reunions/mod...
Reposted by Nicolas Dufour
Final note: I'm (we're) tempted to organize a challenge on that topic as a workshop at a CV conf. ImageNet is the only source of images allowed and then you compete to get the bold numbers.
Do you think there would be people in for that? Do you think it would make for a nice competition?
Do you think there would be people in for that? Do you think it would make for a nice competition?
October 8, 2025 at 8:43 PM
Final note: I'm (we're) tempted to organize a challenge on that topic as a workshop at a CV conf. ImageNet is the only source of images allowed and then you compete to get the bold numbers.
Do you think there would be people in for that? Do you think it would make for a nice competition?
Do you think there would be people in for that? Do you think it would make for a nice competition?
Reposted by Nicolas Dufour

Very proud of our recent work, kudos to the team! Read @davidpicard.bsky.social’s excellent post for more details or the paper arxiv.org/pdf/2502.21318
October 8, 2025 at 9:19 PM
Very proud of our recent work, kudos to the team! Read @davidpicard.bsky.social’s excellent post for more details or the paper arxiv.org/pdf/2502.21318
Reposted by Nicolas Dufour
Today is Antoine Guedon's PhD! Already pretty cool visuals right at the start.




September 25, 2025 at 3:17 PM
Today is Antoine Guedon's PhD! Already pretty cool visuals right at the start.
Reposted by Nicolas Dufour
Annnnnd it's a reject!
Scale is a religion and if you go against it, you're a heretic and you should burn, "despite [the reviewers] final ratings".
But scale is still not necessary!
Side note: First time swinging reviews up (from 2,2,4,4 to 2,4,4,5) does not get the paper accepted. Strange days.
Scale is a religion and if you go against it, you're a heretic and you should burn, "despite [the reviewers] final ratings".
But scale is still not necessary!
Side note: First time swinging reviews up (from 2,2,4,4 to 2,4,4,5) does not get the paper accepted. Strange days.
Dear bsky friends, I have a question: Do you really think that the visual quality of these images is so bad that the research that produced them is deeply flawed?
And if I told you that the model was mostly trained on ImageNet with a bit of artistic fine-tuning at 1024 resolution, still really bad?
And if I told you that the model was mostly trained on ImageNet with a bit of artistic fine-tuning at 1024 resolution, still really bad?
September 18, 2025 at 5:04 PM
Annnnnd it's a reject!
Scale is a religion and if you go against it, you're a heretic and you should burn, "despite [the reviewers] final ratings".
But scale is still not necessary!
Side note: First time swinging reviews up (from 2,2,4,4 to 2,4,4,5) does not get the paper accepted. Strange days.
Scale is a religion and if you go against it, you're a heretic and you should burn, "despite [the reviewers] final ratings".
But scale is still not necessary!
Side note: First time swinging reviews up (from 2,2,4,4 to 2,4,4,5) does not get the paper accepted. Strange days.
Reposted by Nicolas Dufour

Does a smaller latent space lead to worse generation in latent diffusion models? Not necessarily! We show that LDMs are extremely robust to a wide range of compression rates (10-1000x) in the context of physics emulation.
We got lost in latent space. Join us 👇
We got lost in latent space. Join us 👇

September 3, 2025 at 1:40 PM
Does a smaller latent space lead to worse generation in latent diffusion models? Not necessarily! We show that LDMs are extremely robust to a wide range of compression rates (10-1000x) in the context of physics emulation.
We got lost in latent space. Join us 👇
We got lost in latent space. Join us 👇
Reposted by Nicolas Dufour
Next week, I'll be in Strasbourg for the GRETSI (@gretsi-info.bsky.social) to present a small discovery on transformers generalization we made with Simon and Jérémie while working on generative recommender systems. I love these "phase transition" plots.
📜: arxiv.org/abs/2508.03934
Short summary 👇
📜: arxiv.org/abs/2508.03934
Short summary 👇

August 23, 2025 at 10:12 AM
Next week, I'll be in Strasbourg for the GRETSI (@gretsi-info.bsky.social) to present a small discovery on transformers generalization we made with Simon and Jérémie while working on generative recommender systems. I love these "phase transition" plots.
📜: arxiv.org/abs/2508.03934
Short summary 👇
📜: arxiv.org/abs/2508.03934
Short summary 👇
🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.

August 18, 2025 at 3:14 PM
🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
Reposted by Nicolas Dufour
Dear bsky friends, I have a question: Do you really think that the visual quality of these images is so bad that the research that produced them is deeply flawed?
And if I told you that the model was mostly trained on ImageNet with a bit of artistic fine-tuning at 1024 resolution, still really bad?
And if I told you that the model was mostly trained on ImageNet with a bit of artistic fine-tuning at 1024 resolution, still really bad?




August 7, 2025 at 6:43 AM
Dear bsky friends, I have a question: Do you really think that the visual quality of these images is so bad that the research that produced them is deeply flawed?
And if I told you that the model was mostly trained on ImageNet with a bit of artistic fine-tuning at 1024 resolution, still really bad?
And if I told you that the model was mostly trained on ImageNet with a bit of artistic fine-tuning at 1024 resolution, still really bad?
I had the privilege to be invited to speak about our work "Around the World in 80 Timesteps" at the French Podcast Underscore! If you speak french, i highly recommend it they did a great job with the montage!
If you want to learn more nicolas-dufour.github.io/plonk
www.youtube.com/watch?v=s5oH...
If you want to learn more nicolas-dufour.github.io/plonk
www.youtube.com/watch?v=s5oH...

Il a conçu la première IA d’OSINT (terrifiant… et génial)
YouTube video by Underscore_
www.youtube.com
July 31, 2025 at 4:43 PM
I had the privilege to be invited to speak about our work "Around the World in 80 Timesteps" at the French Podcast Underscore! If you speak french, i highly recommend it they did a great job with the montage!
If you want to learn more nicolas-dufour.github.io/plonk
www.youtube.com/watch?v=s5oH...
If you want to learn more nicolas-dufour.github.io/plonk
www.youtube.com/watch?v=s5oH...
Reposted by Nicolas Dufour

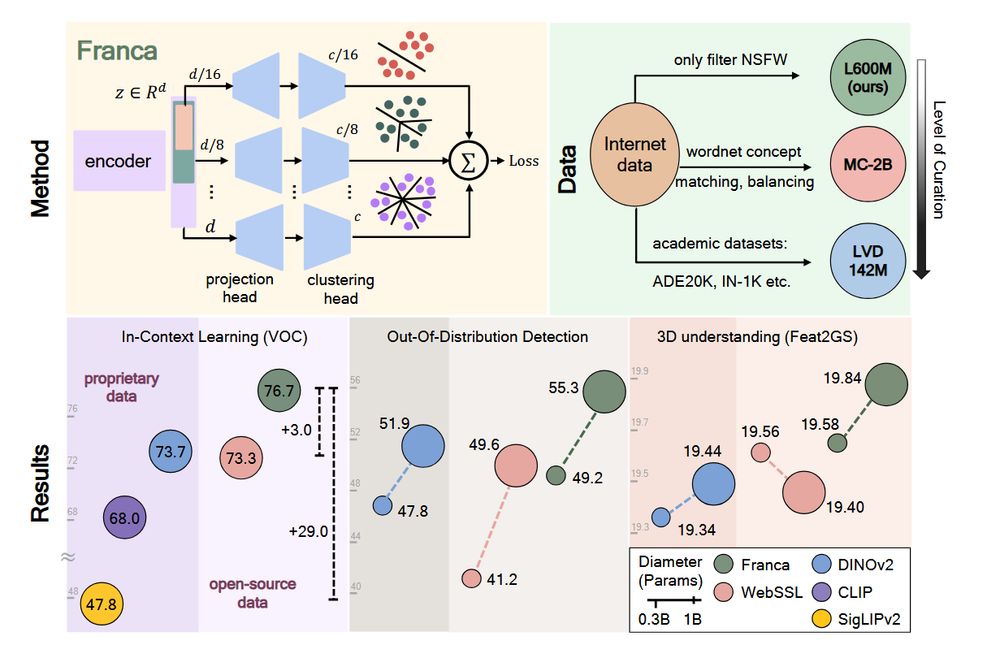
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
July 21, 2025 at 2:47 PM
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
Reposted by Nicolas Dufour

✨Thrilled to see EurIPS launch — the first officially endorsed European NeurIPS presentation venue!
👀 But NeurIPS now requires at least one author to attend in San Diego or Mexico (and not just virtually as before). This is detrimental to many. Why not allow presenting at EurIPS or online?
1/4
👀 But NeurIPS now requires at least one author to attend in San Diego or Mexico (and not just virtually as before). This is detrimental to many. Why not allow presenting at EurIPS or online?
1/4

EurIPS is coming! 📣 Mark your calendar for Dec. 2-7, 2025 in Copenhagen 📅
EurIPS is a community-organized conference where you can present accepted NeurIPS 2025 papers, endorsed by @neuripsconf.bsky.social and @nordicair.bsky.social and is co-developed by @ellis.eu
eurips.cc
EurIPS is a community-organized conference where you can present accepted NeurIPS 2025 papers, endorsed by @neuripsconf.bsky.social and @nordicair.bsky.social and is co-developed by @ellis.eu
eurips.cc

July 17, 2025 at 8:49 AM
✨Thrilled to see EurIPS launch — the first officially endorsed European NeurIPS presentation venue!
👀 But NeurIPS now requires at least one author to attend in San Diego or Mexico (and not just virtually as before). This is detrimental to many. Why not allow presenting at EurIPS or online?
1/4
👀 But NeurIPS now requires at least one author to attend in San Diego or Mexico (and not just virtually as before). This is detrimental to many. Why not allow presenting at EurIPS or online?
1/4




Reposted by Nicolas Dufour
Come on! Who else has a hot air ballon on their poster?
(fun fact: there is no hot air ballon emoji, but @loicland.bsky.social made a tikz macro for it! 😅)
(fun fact: there is no hot air ballon emoji, but @loicland.bsky.social made a tikz macro for it! 😅)
Come see us in poster 186 to see our poster Around the World in 80 timesteps: A generative Approach to Global Visual Geolocation!
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social

June 15, 2025 at 3:57 PM
Come on! Who else has a hot air ballon on their poster?
(fun fact: there is no hot air ballon emoji, but @loicland.bsky.social made a tikz macro for it! 😅)
(fun fact: there is no hot air ballon emoji, but @loicland.bsky.social made a tikz macro for it! 😅)
Come see us in poster 186 to see our poster Around the World in 80 timesteps: A generative Approach to Global Visual Geolocation!
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social
June 15, 2025 at 3:30 PM
Come see us in poster 186 to see our poster Around the World in 80 timesteps: A generative Approach to Global Visual Geolocation!
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social
Reposted by Nicolas Dufour

A bit disappointed by the PAMI TC meeting, mostly repetitions of what’s been said at the opening, the "open discussion" slide was really just there to *exist* but no discussion/vote took place, no topic was debated. What space is left to reflect on our community and what we stand for as scientists?
June 14, 2025 at 11:25 PM
A bit disappointed by the PAMI TC meeting, mostly repetitions of what’s been said at the opening, the "open discussion" slide was really just there to *exist* but no discussion/vote took place, no topic was debated. What space is left to reflect on our community and what we stand for as scientists?
Reposted by Nicolas Dufour

I am heartbroken that I am not at the conference, but seeing what the government is doing to its people and the world, I simply couldn't go there.
June 14, 2025 at 9:51 AM
I am heartbroken that I am not at the conference, but seeing what the government is doing to its people and the world, I simply couldn't go there.