



Nicolas Dufour
@nicolasdufour.bsky.social
PhD student at IMAGINE (ENPC) and GeoVic (Ecole Polytechnique). Working on image generation.
http://nicolas-dufour.github.io
http://nicolas-dufour.github.io
The explicit reward conditioning allows for flexible trade-offs, like optimizing for GenEval by reducing the aesthetic weight in the prompt. We can also isolate the look of a specific reward or interpolate them via multi-reward classifier-free guidance


October 31, 2025 at 11:24 AM
The explicit reward conditioning allows for flexible trade-offs, like optimizing for GenEval by reducing the aesthetic weight in the prompt. We can also isolate the look of a specific reward or interpolate them via multi-reward classifier-free guidance
MIRO excels on challenging compositional tasks (Geneval here)
The multi-reward conditioning fosters better understanding of complex spatial relationships and object interactions.
The multi-reward conditioning fosters better understanding of complex spatial relationships and object interactions.

October 31, 2025 at 11:24 AM
MIRO excels on challenging compositional tasks (Geneval here)
The multi-reward conditioning fosters better understanding of complex spatial relationships and object interactions.
The multi-reward conditioning fosters better understanding of complex spatial relationships and object interactions.
Despite being a compact model (0.36B parameters), MIRO achieves state-of-the-art results:
GenEval score of 75, outperforming the 12B FLUX-dev (67) for 370x less inference cost.
Conditioning on rich reward signals is a highly effective way to achieve large model capabilities in a compact form!
GenEval score of 75, outperforming the 12B FLUX-dev (67) for 370x less inference cost.
Conditioning on rich reward signals is a highly effective way to achieve large model capabilities in a compact form!

October 31, 2025 at 11:24 AM
Despite being a compact model (0.36B parameters), MIRO achieves state-of-the-art results:
GenEval score of 75, outperforming the 12B FLUX-dev (67) for 370x less inference cost.
Conditioning on rich reward signals is a highly effective way to achieve large model capabilities in a compact form!
GenEval score of 75, outperforming the 12B FLUX-dev (67) for 370x less inference cost.
Conditioning on rich reward signals is a highly effective way to achieve large model capabilities in a compact form!
MIRO dramatically improves sample efficiency for test-time scaling.
On PickScore, MIRO needs just 4 samples to match the baseline's 128 samples (a 32x efficiency gain).
For ImageReward, it's a 16x efficiency gain
This demonstrates superior inference-time efficiency for high-quality generation.
On PickScore, MIRO needs just 4 samples to match the baseline's 128 samples (a 32x efficiency gain).
For ImageReward, it's a 16x efficiency gain
This demonstrates superior inference-time efficiency for high-quality generation.

October 31, 2025 at 11:24 AM
MIRO dramatically improves sample efficiency for test-time scaling.
On PickScore, MIRO needs just 4 samples to match the baseline's 128 samples (a 32x efficiency gain).
For ImageReward, it's a 16x efficiency gain
This demonstrates superior inference-time efficiency for high-quality generation.
On PickScore, MIRO needs just 4 samples to match the baseline's 128 samples (a 32x efficiency gain).
For ImageReward, it's a 16x efficiency gain
This demonstrates superior inference-time efficiency for high-quality generation.
Traditional single-objective optimization often leads to reward hacking. MIRO's multi-dimensional conditioning naturally prevents this by requiring the model to balance multiple objectives simultaneously. This produces balanced, robust performance across all metrics contrary to single rewards.

October 31, 2025 at 11:24 AM
Traditional single-objective optimization often leads to reward hacking. MIRO's multi-dimensional conditioning naturally prevents this by requiring the model to balance multiple objectives simultaneously. This produces balanced, robust performance across all metrics contrary to single rewards.
The multi-reward conditioning provides a dense supervisory signal, accelerating convergence dramatically. A snapshot of the speed-up:
AestheticScore: 19.1x faster to reach baseline quality.
HPSv2: 6.2x faster.
You can clearly see the improvements visually
AestheticScore: 19.1x faster to reach baseline quality.
HPSv2: 6.2x faster.
You can clearly see the improvements visually


October 31, 2025 at 11:24 AM
The multi-reward conditioning provides a dense supervisory signal, accelerating convergence dramatically. A snapshot of the speed-up:
AestheticScore: 19.1x faster to reach baseline quality.
HPSv2: 6.2x faster.
You can clearly see the improvements visually
AestheticScore: 19.1x faster to reach baseline quality.
HPSv2: 6.2x faster.
You can clearly see the improvements visually
This reward vector s becomes an explicit, interpretable control input at inference time. We extend classifier-free guidance to the multi-reward setting, allowing users to steer generation toward jointly high-reward regions by defining positive (s^+) and negative (s^−) targets.
October 31, 2025 at 11:24 AM
This reward vector s becomes an explicit, interpretable control input at inference time. We extend classifier-free guidance to the multi-reward setting, allowing users to steer generation toward jointly high-reward regions by defining positive (s^+) and negative (s^−) targets.
MIRO trains p(x∣c,s) by conditioning the generative model on a vector s of reward scores for each image-text pair. Instead of correcting a pre-trained model, we teach it how to trade off multiple rewards from the start.
October 31, 2025 at 11:24 AM
MIRO trains p(x∣c,s) by conditioning the generative model on a vector s of reward scores for each image-text pair. Instead of correcting a pre-trained model, we teach it how to trade off multiple rewards from the start.
We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉

October 31, 2025 at 11:24 AM
We introduce MIRO: a new paradigm for T2I model alignment integrating reward conditioning into pretraining, eliminating the need for separate fine-tuning/RL stages. This single-stage approach offers unprecedented efficiency and control.
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
- 19x faster convergence ⚡
- 370x less FLOPS than FLUX-dev 📉
Makes me think of StyleGAN3 visualizations

August 18, 2025 at 10:44 PM
Makes me think of StyleGAN3 visualizations
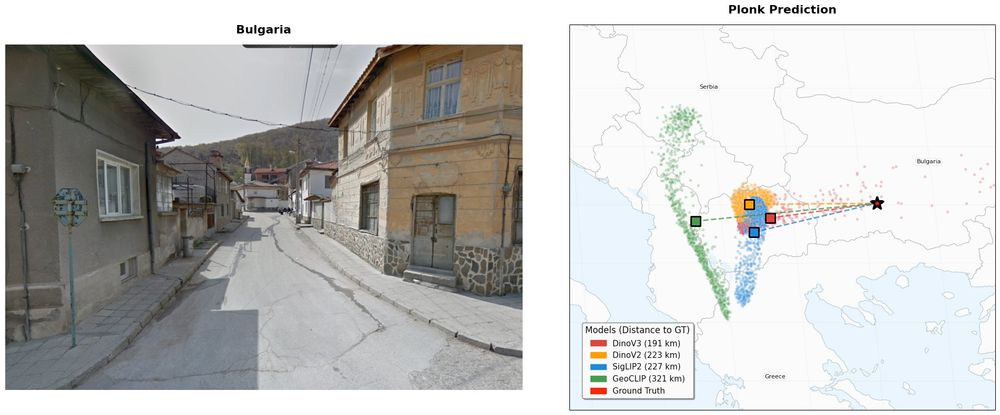
Even crazier 🤯 DinoV3 works in some out-of-distribution setups too — as long as there are geographical cues 🌄🗺️
(Remember: the network is trained only on road images!)
Where DinoV2 totally failed, DinoV3 is holding up 👊
(Remember: the network is trained only on road images!)
Where DinoV2 totally failed, DinoV3 is holding up 👊

August 18, 2025 at 3:14 PM
Even crazier 🤯 DinoV3 works in some out-of-distribution setups too — as long as there are geographical cues 🌄🗺️
(Remember: the network is trained only on road images!)
Where DinoV2 totally failed, DinoV3 is holding up 👊
(Remember: the network is trained only on road images!)
Where DinoV2 totally failed, DinoV3 is holding up 👊
The setup 👉 We use our riemannian flow matching model PLONK (CVPR25: Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation) 🌍
We simply swap StreetCLIP with DinoV3 as a drop-in backbone, and train on OpenStreetView-5M.
And boom 💥 — DinoV3 wins.
We simply swap StreetCLIP with DinoV3 as a drop-in backbone, and train on OpenStreetView-5M.
And boom 💥 — DinoV3 wins.

August 18, 2025 at 3:14 PM
The setup 👉 We use our riemannian flow matching model PLONK (CVPR25: Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation) 🌍
We simply swap StreetCLIP with DinoV3 as a drop-in backbone, and train on OpenStreetView-5M.
And boom 💥 — DinoV3 wins.
We simply swap StreetCLIP with DinoV3 as a drop-in backbone, and train on OpenStreetView-5M.
And boom 💥 — DinoV3 wins.
🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.

August 18, 2025 at 3:14 PM
🚀 DinoV3 just became the new go-to backbone for geoloc!
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
It outperforms CLIP-like models (SigLip2, finetuned StreetCLIP)… and that’s shocking 🤯
Why? CLIP models have an innate advantage — they literally learn place names + images. DinoV3 doesn’t.
Come see us in poster 186 to see our poster Around the World in 80 timesteps: A generative Approach to Global Visual Geolocation!
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social

June 15, 2025 at 3:30 PM
Come see us in poster 186 to see our poster Around the World in 80 timesteps: A generative Approach to Global Visual Geolocation!
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social
Cc @loicland.bsky.social @davidpicard.bsky.social @vickykalogeiton.bsky.social
I will be at #CVPR2025 this week in Nashville.
I will be presenting our paper "Around the World in 80 Timesteps:
A Generative Approach to Global Visual Geolocation".
We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.
I will be presenting our paper "Around the World in 80 Timesteps:
A Generative Approach to Global Visual Geolocation".
We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.
June 11, 2025 at 12:52 AM
I will be at #CVPR2025 this week in Nashville.
I will be presenting our paper "Around the World in 80 Timesteps:
A Generative Approach to Global Visual Geolocation".
We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.
I will be presenting our paper "Around the World in 80 Timesteps:
A Generative Approach to Global Visual Geolocation".
We tackle geolocalization as a generative task allowing for SOTA performance and more interpretable predictions.
This is an idea I've had for a while, but wow, it's working way better than expected! 🚀
The model looks really promising, even though it's just 256px for now.
The model looks really promising, even though it's just 256px for now.

April 24, 2025 at 12:40 PM
This is an idea I've had for a while, but wow, it's working way better than expected! 🚀
The model looks really promising, even though it's just 256px for now.
The model looks really promising, even though it's just 256px for now.
Our paper got accepted at TMLR!
TLDR; You can improve your diffusion samples by increasing guidance during the sampling process. A simpler linear scheduler suffice and is more robust than more elaborated methods.
TLDR; You can improve your diffusion samples by increasing guidance during the sampling process. A simpler linear scheduler suffice and is more robust than more elaborated methods.

December 20, 2024 at 1:23 AM
Our paper got accepted at TMLR!
TLDR; You can improve your diffusion samples by increasing guidance during the sampling process. A simpler linear scheduler suffice and is more robust than more elaborated methods.
TLDR; You can improve your diffusion samples by increasing guidance during the sampling process. A simpler linear scheduler suffice and is more robust than more elaborated methods.
To make our models easy to use, we packaged them into an easy to use library.
Also all our training code is available here: github.com/nicolas-dufo...
The demo can be run from there if you want to run it on GPU for superfast inference.
Also all our training code is available here: github.com/nicolas-dufo...
The demo can be run from there if you want to run it on GPU for superfast inference.

December 12, 2024 at 3:21 PM
To make our models easy to use, we packaged them into an easy to use library.
Also all our training code is available here: github.com/nicolas-dufo...
The demo can be run from there if you want to run it on GPU for superfast inference.
Also all our training code is available here: github.com/nicolas-dufo...
The demo can be run from there if you want to run it on GPU for superfast inference.
🌎 Why does geolocation matter?
From OSINT for journalists 🕵️ to tracking wildlife 🐘, geolocation solves critical challenges.
Models released:
🚗 OSV-5M: Pinpoint street-view images
🦋 iNat21: Track biodiversity
📸 YFCC-100M: Organize millions of diverse user-uploaded images
From OSINT for journalists 🕵️ to tracking wildlife 🐘, geolocation solves critical challenges.
Models released:
🚗 OSV-5M: Pinpoint street-view images
🦋 iNat21: Track biodiversity
📸 YFCC-100M: Organize millions of diverse user-uploaded images
December 10, 2024 at 3:56 PM
🌎 Why does geolocation matter?
From OSINT for journalists 🕵️ to tracking wildlife 🐘, geolocation solves critical challenges.
Models released:
🚗 OSV-5M: Pinpoint street-view images
🦋 iNat21: Track biodiversity
📸 YFCC-100M: Organize millions of diverse user-uploaded images
From OSINT for journalists 🕵️ to tracking wildlife 🐘, geolocation solves critical challenges.
Models released:
🚗 OSV-5M: Pinpoint street-view images
🦋 iNat21: Track biodiversity
📸 YFCC-100M: Organize millions of diverse user-uploaded images
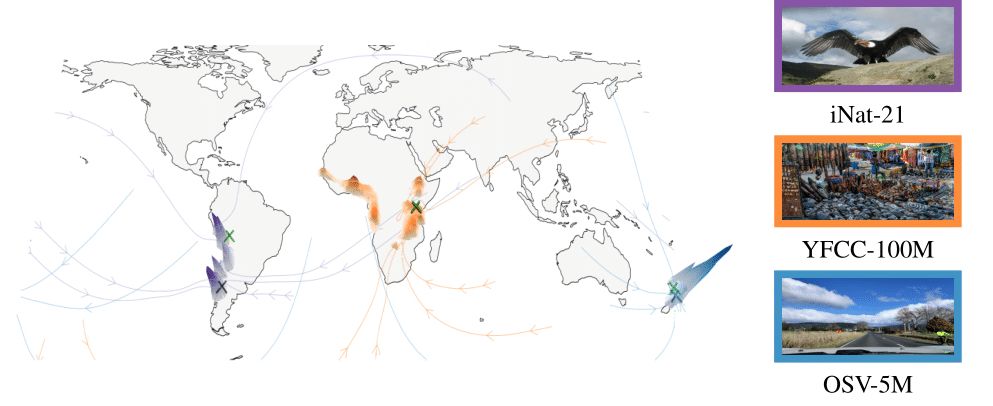
🧭 Our diffusion model learns to map an image's content to its location through multiple scales.
🌍 With Riemannian Flow Matching, we can denoise coordinates on the Earth's spherical geometry.
🔍 We reach SOTA geolocation results on OpenStreetView-5M, iNat-21, and YFCC100M.
🌍 With Riemannian Flow Matching, we can denoise coordinates on the Earth's spherical geometry.
🔍 We reach SOTA geolocation results on OpenStreetView-5M, iNat-21, and YFCC100M.

December 10, 2024 at 3:56 PM
🧭 Our diffusion model learns to map an image's content to its location through multiple scales.
🌍 With Riemannian Flow Matching, we can denoise coordinates on the Earth's spherical geometry.
🔍 We reach SOTA geolocation results on OpenStreetView-5M, iNat-21, and YFCC100M.
🌍 With Riemannian Flow Matching, we can denoise coordinates on the Earth's spherical geometry.
🔍 We reach SOTA geolocation results on OpenStreetView-5M, iNat-21, and YFCC100M.
Some images can be pinpointed exactly, while others are more ambiguous. Our model doesn't just pick a point, but provides a spatial probability distribution.
🌐 We can now quantify how "localizable" an image is, from a picture of the Eiffel Tower 🗼 to one of a random pigeon🐦!
🌐 We can now quantify how "localizable" an image is, from a picture of the Eiffel Tower 🗼 to one of a random pigeon🐦!


December 10, 2024 at 3:56 PM
Some images can be pinpointed exactly, while others are more ambiguous. Our model doesn't just pick a point, but provides a spatial probability distribution.
🌐 We can now quantify how "localizable" an image is, from a picture of the Eiffel Tower 🗼 to one of a random pigeon🐦!
🌐 We can now quantify how "localizable" an image is, from a picture of the Eiffel Tower 🗼 to one of a random pigeon🐦!
🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface!
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
December 10, 2024 at 3:56 PM
🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface!
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk