




Andrei Bursuc
@abursuc.bsky.social
Research Scientist at valeo.ai | Teaching at Polytechnique, ENS | Alumni at Mines Paris, Inria, ENS | AI for Autonomous Driving, Computer Vision, Machine Learning | Robotics amateur
⚲ Paris, France 🔗 abursuc.github.io
⚲ Paris, France 🔗 abursuc.github.io
Pinned
Andrei Bursuc
@abursuc.bsky.social
· Jul 21
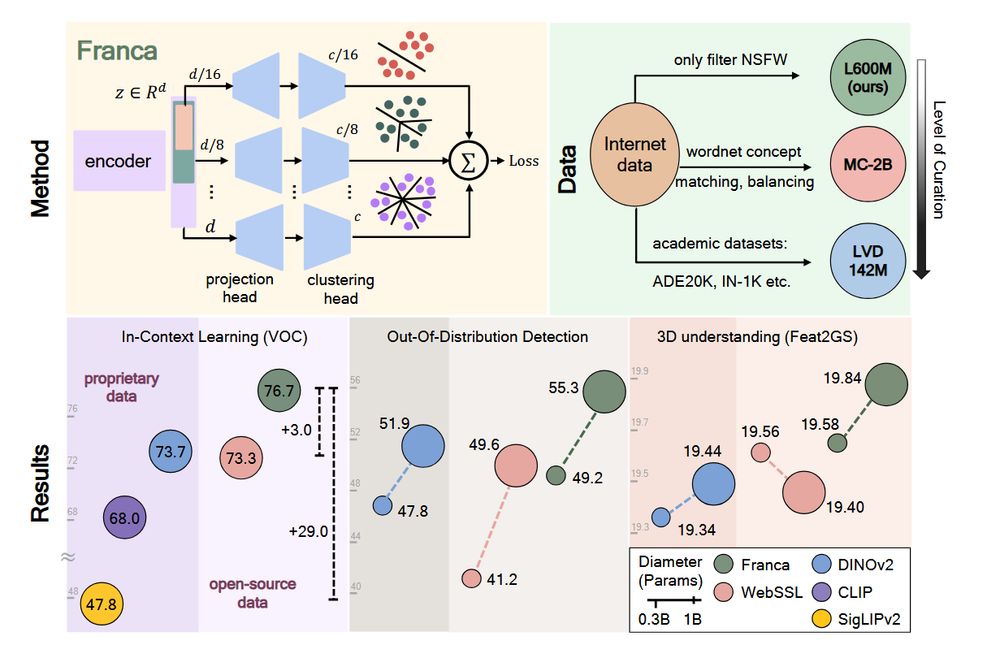
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
Reposted by Andrei Bursuc

Maybe the most important thing I’ve learned over the past few years is that the solution to what looks like a collective action problem is to just start solving it. People will show up.
January 18, 2026 at 3:58 AM
Maybe the most important thing I’ve learned over the past few years is that the solution to what looks like a collective action problem is to just start solving it. People will show up.
Reposted by Andrei Bursuc

Seems like a bunch of people are joining BlueSky recently after the whole X situation, so maybe it's worth highlighting this again. Also, if you feel like you should be on this list, send me a message!
I made a starter pack for Bayesian ML and stats (mostly to see how this starter pack business works).
Let me know whom I missed!
go.bsky.app/2Bqtn6T
Let me know whom I missed!
go.bsky.app/2Bqtn6T
January 13, 2026 at 9:00 AM
Seems like a bunch of people are joining BlueSky recently after the whole X situation, so maybe it's worth highlighting this again. Also, if you feel like you should be on this list, send me a message!

Reposted by Andrei Bursuc

1/🧵 Q: Can we have both a simple and SOTA architecture in autonomous driving?
R: Yes! 😍
Introducing Driving on Registers (DrivoR):
a pure Transformer backbone that achieves SOTA results in NAVSIM v1 / v2 and closed-loop HUGSIM evaluation.
Here is how 👇
R: Yes! 😍
Introducing Driving on Registers (DrivoR):
a pure Transformer backbone that achieves SOTA results in NAVSIM v1 / v2 and closed-loop HUGSIM evaluation.
Here is how 👇

January 9, 2026 at 4:55 PM
1/🧵 Q: Can we have both a simple and SOTA architecture in autonomous driving?
R: Yes! 😍
Introducing Driving on Registers (DrivoR):
a pure Transformer backbone that achieves SOTA results in NAVSIM v1 / v2 and closed-loop HUGSIM evaluation.
Here is how 👇
R: Yes! 😍
Introducing Driving on Registers (DrivoR):
a pure Transformer backbone that achieves SOTA results in NAVSIM v1 / v2 and closed-loop HUGSIM evaluation.
Here is how 👇
The unreasonable magic of simplicity!
Meet DrivoR (Driving on Registers): our latest end2end autonomous driving model.
We teared down complex dependencies & modules from current models to
obtain a pure Transformer-based SOTA driving agent (NAVSIM v1 & v2, HUGSIM).
Find out more 👇
Meet DrivoR (Driving on Registers): our latest end2end autonomous driving model.
We teared down complex dependencies & modules from current models to
obtain a pure Transformer-based SOTA driving agent (NAVSIM v1 & v2, HUGSIM).
Find out more 👇
1/🧵 Q: Can we have both a simple and SOTA architecture in autonomous driving?
R: Yes! 😍
Introducing Driving on Registers (DrivoR):
a pure Transformer backbone that achieves SOTA results in NAVSIM v1 / v2 and closed-loop HUGSIM evaluation.
Here is how 👇
R: Yes! 😍
Introducing Driving on Registers (DrivoR):
a pure Transformer backbone that achieves SOTA results in NAVSIM v1 / v2 and closed-loop HUGSIM evaluation.
Here is how 👇
January 9, 2026 at 5:02 PM
The unreasonable magic of simplicity!
Meet DrivoR (Driving on Registers): our latest end2end autonomous driving model.
We teared down complex dependencies & modules from current models to
obtain a pure Transformer-based SOTA driving agent (NAVSIM v1 & v2, HUGSIM).
Find out more 👇
Meet DrivoR (Driving on Registers): our latest end2end autonomous driving model.
We teared down complex dependencies & modules from current models to
obtain a pure Transformer-based SOTA driving agent (NAVSIM v1 & v2, HUGSIM).
Find out more 👇
Reposted by Andrei Bursuc

I have an opening for a two years post-doc position on instance-level (personalized) visual generation. Eligibility: (i) <=7 years from Ph.D. (ii) studies or 1 year outside of Czechia (ii) >=3 journal with IF or CORE A*/A conference papers. Deadline: 15 Feb.
Details: www.euraxess.cz/jobs/399390
Details: www.euraxess.cz/jobs/399390

Postdoctoral research position in Instance-level visual generation
Czech Technical University in Prague (CTU) offers a fellowship program, the CTU Global Postdoc Fellowship. This new and attractive two-year fellowship-program offers excellent researchers who have rec...
www.euraxess.cz
January 8, 2026 at 11:11 AM
I have an opening for a two years post-doc position on instance-level (personalized) visual generation. Eligibility: (i) <=7 years from Ph.D. (ii) studies or 1 year outside of Czechia (ii) >=3 journal with IF or CORE A*/A conference papers. Deadline: 15 Feb.
Details: www.euraxess.cz/jobs/399390
Details: www.euraxess.cz/jobs/399390
On some days when my digest arrives later in the day, it feels like the gods of scholar-inbox are punishing me for not checking my digest the prior day 🙃
January 7, 2026 at 9:00 AM
On some days when my digest arrives later in the day, it feels like the gods of scholar-inbox are punishing me for not checking my digest the prior day 🙃
Taking the kids to daycare by sleigh today




January 7, 2026 at 8:25 AM
Taking the kids to daycare by sleigh today
Reposted by Andrei Bursuc

What if you could train agents on a 𝗱𝗲𝗰𝗮𝗱𝗲 of driving experience in 𝘂𝗻𝗱𝗲𝗿 𝗮𝗻 𝗵𝗼𝘂𝗿, on a single GPU?
Excited to share 𝙋𝙪𝙛𝙛𝙚𝙧𝘿𝙧𝙞𝙫𝙚 2.0: A fast, friendly driving simulator with RL training via PufferLib at 𝟯𝟬𝟬𝗞 𝘀𝘁𝗲𝗽𝘀/𝘀𝗲𝗰 🐡 + 🚗
youtu.be/LfQ324R-cbE?...
Excited to share 𝙋𝙪𝙛𝙛𝙚𝙧𝘿𝙧𝙞𝙫𝙚 2.0: A fast, friendly driving simulator with RL training via PufferLib at 𝟯𝟬𝟬𝗞 𝘀𝘁𝗲𝗽𝘀/𝘀𝗲𝗰 🐡 + 🚗
youtu.be/LfQ324R-cbE?...

PufferDrive 2.0 release
YouTube video by Daphne Cornelisse
youtu.be
December 30, 2025 at 4:12 PM
What if you could train agents on a 𝗱𝗲𝗰𝗮𝗱𝗲 of driving experience in 𝘂𝗻𝗱𝗲𝗿 𝗮𝗻 𝗵𝗼𝘂𝗿, on a single GPU?
Excited to share 𝙋𝙪𝙛𝙛𝙚𝙧𝘿𝙧𝙞𝙫𝙚 2.0: A fast, friendly driving simulator with RL training via PufferLib at 𝟯𝟬𝟬𝗞 𝘀𝘁𝗲𝗽𝘀/𝘀𝗲𝗰 🐡 + 🚗
youtu.be/LfQ324R-cbE?...
Excited to share 𝙋𝙪𝙛𝙛𝙚𝙧𝘿𝙧𝙞𝙫𝙚 2.0: A fast, friendly driving simulator with RL training via PufferLib at 𝟯𝟬𝟬𝗞 𝘀𝘁𝗲𝗽𝘀/𝘀𝗲𝗰 🐡 + 🚗
youtu.be/LfQ324R-cbE?...
Reposted by Andrei Bursuc

Our new E2E driving method, TransFuser v6, is out on ArXiv.
It outperforms all other methods on CARLA by a wide margin, 95 DS on Bench2Drive!
We show that minimizing the asymmetry between data annotator and policy is key for strong IL results.
Code, models, and paper:
ln2697.github.io/lead/
It outperforms all other methods on CARLA by a wide margin, 95 DS on Bench2Drive!
We show that minimizing the asymmetry between data annotator and policy is key for strong IL results.
Code, models, and paper:
ln2697.github.io/lead/
December 27, 2025 at 1:42 AM
Our new E2E driving method, TransFuser v6, is out on ArXiv.
It outperforms all other methods on CARLA by a wide margin, 95 DS on Bench2Drive!
We show that minimizing the asymmetry between data annotator and policy is key for strong IL results.
Code, models, and paper:
ln2697.github.io/lead/
It outperforms all other methods on CARLA by a wide margin, 95 DS on Bench2Drive!
We show that minimizing the asymmetry between data annotator and policy is key for strong IL results.
Code, models, and paper:
ln2697.github.io/lead/
Reposted by Andrei Bursuc

1/n REGLUE Your Latents! 🚀
We introduce REGLUE: a unified framework that entangles VAE latents ➕ Global ➕ Local semantics for faster, higher-fidelity image generation.
Links (paper + code) at the end👇
We introduce REGLUE: a unified framework that entangles VAE latents ➕ Global ➕ Local semantics for faster, higher-fidelity image generation.
Links (paper + code) at the end👇

December 27, 2025 at 10:26 AM
1/n REGLUE Your Latents! 🚀
We introduce REGLUE: a unified framework that entangles VAE latents ➕ Global ➕ Local semantics for faster, higher-fidelity image generation.
Links (paper + code) at the end👇
We introduce REGLUE: a unified framework that entangles VAE latents ➕ Global ➕ Local semantics for faster, higher-fidelity image generation.
Links (paper + code) at the end👇







Reposted by Andrei Bursuc

Ok, I have a strong opinion on this, perhaps you can convince me otherwise: if you need an LLM to understand a paper for reviewing, perhaps you should not be a reviewer.
And your argument is saved time, then perhaps you planned to not read all the details. Then again, you should not be a reviewer.
And your argument is saved time, then perhaps you planned to not read all the details. Then again, you should not be a reviewer.
December 12, 2025 at 5:36 AM
Ok, I have a strong opinion on this, perhaps you can convince me otherwise: if you need an LLM to understand a paper for reviewing, perhaps you should not be a reviewer.
And your argument is saved time, then perhaps you planned to not read all the details. Then again, you should not be a reviewer.
And your argument is saved time, then perhaps you planned to not read all the details. Then again, you should not be a reviewer.
Full house for Gianni Franchi’s viva / HDR defense “Towards Trustworthy AI”.
Forza Gianni!
Forza Gianni!




December 11, 2025 at 3:14 PM
Full house for Gianni Franchi’s viva / HDR defense “Towards Trustworthy AI”.
Forza Gianni!
Forza Gianni!
Happy to announce that our paper "IPA: An Information-Reconstructive Input Projection Framework for Efficient Foundation Model Adaptation" got the best paper award at the #CCFM workshop at #NeurIPS2025
Many thanks to the reviewers and organizers.
Kudos to @yuanyinnn.bsky.social & team!
Many thanks to the reviewers and organizers.
Kudos to @yuanyinnn.bsky.social & team!

1/Serve your PEFT with a fresh IPA!🍺
Finetuning large models is cheaper thanks to LoRA, but is its random init optimal?🤔
Meet IPA: a feature-aware alternative to random projections
#NeurIPS2025 WS #CCFM Oral+Best Paper
Work w/
S. Venkataramanan @tuanhungvu.bsky.social @abursuc.bsky.social M. Cord
🧵
Finetuning large models is cheaper thanks to LoRA, but is its random init optimal?🤔
Meet IPA: a feature-aware alternative to random projections
#NeurIPS2025 WS #CCFM Oral+Best Paper
Work w/
S. Venkataramanan @tuanhungvu.bsky.social @abursuc.bsky.social M. Cord
🧵
December 10, 2025 at 4:06 PM
Happy to announce that our paper "IPA: An Information-Reconstructive Input Projection Framework for Efficient Foundation Model Adaptation" got the best paper award at the #CCFM workshop at #NeurIPS2025
Many thanks to the reviewers and organizers.
Kudos to @yuanyinnn.bsky.social & team!
Many thanks to the reviewers and organizers.
Kudos to @yuanyinnn.bsky.social & team!
Reposted by Andrei Bursuc
Our @spyrosgidaris.bsky.social is speaking this morning (Wed, Dec 10th, 11:00 am Paris time) about "Latent Representations for Better Generative Image Modeling" in the Hi! PARIS - ELLIS monthly seminar.
The talk will be live-streamed: www.hi-paris.fr/2025/09/26/a...
The talk will be live-streamed: www.hi-paris.fr/2025/09/26/a...
AI Seminar Cycle – Hi! PARIS
www.hi-paris.fr
December 10, 2025 at 9:15 AM
Our @spyrosgidaris.bsky.social is speaking this morning (Wed, Dec 10th, 11:00 am Paris time) about "Latent Representations for Better Generative Image Modeling" in the Hi! PARIS - ELLIS monthly seminar.
The talk will be live-streamed: www.hi-paris.fr/2025/09/26/a...
The talk will be live-streamed: www.hi-paris.fr/2025/09/26/a...
Robotics researchers, this is an occasion not to be missed: top-notch speakers in an excellent location in the Alps this February 🤖⛷️
It's the Winter School on Social Robotics, Artificial Intelligence and Multimedia (SoRAIM), 9-13 Feb 2026 👇
It's the Winter School on Social Robotics, Artificial Intelligence and Multimedia (SoRAIM), 9-13 Feb 2026 👇


December 8, 2025 at 9:56 AM
Robotics researchers, this is an occasion not to be missed: top-notch speakers in an excellent location in the Alps this February 🤖⛷️
It's the Winter School on Social Robotics, Artificial Intelligence and Multimedia (SoRAIM), 9-13 Feb 2026 👇
It's the Winter School on Social Robotics, Artificial Intelligence and Multimedia (SoRAIM), 9-13 Feb 2026 👇
Tired Europe: Let's do tons of AI regulations
Wired Europe: Let's do tons of AI open source
#aiPULSE2025
Wired Europe: Let's do tons of AI open source
#aiPULSE2025
December 5, 2025 at 8:00 PM
Tired Europe: Let's do tons of AI regulations
Wired Europe: Let's do tons of AI open source
#aiPULSE2025
Wired Europe: Let's do tons of AI open source
#aiPULSE2025
I'm speaking at #aiPULSE2025 today on Open & re-purposable foundation models for the automotive industry.
The morning keynotes talked a lot about open source so my slide here might be timely.
The morning keynotes talked a lot about open source so my slide here might be timely.

December 4, 2025 at 10:34 AM
I'm speaking at #aiPULSE2025 today on Open & re-purposable foundation models for the automotive industry.
The morning keynotes talked a lot about open source so my slide here might be timely.
The morning keynotes talked a lot about open source so my slide here might be timely.
Hey #NeurIPS2025! We have a fun deck of works with the team and friends to present this year. Check them out!
Check out our works at @NeurIPSConf #NeurIPS2025 this week!
We present 5 full papers + 1 workshop about:
💡 self-supervised & representation learning
🖼️ generative image models
🧠 finetuning and understanding LLMs & multimodal LLMs
🔎 feature upsampling
valeoai.github.io/posts/neurip...
We present 5 full papers + 1 workshop about:
💡 self-supervised & representation learning
🖼️ generative image models
🧠 finetuning and understanding LLMs & multimodal LLMs
🔎 feature upsampling
valeoai.github.io/posts/neurip...

December 3, 2025 at 10:54 PM
Hey #NeurIPS2025! We have a fun deck of works with the team and friends to present this year. Check them out!
We fermented our thoughts on understanding LoRA & ended up with IPA🍺
We found an asymmetry in LoRA: during training, A changes little & B eats most task-specific adaptation.
So we pre-train A to preserve information before adaptation w/ excellent parameter efficiency #NeurIPS2025 #CCFM 👇
We found an asymmetry in LoRA: during training, A changes little & B eats most task-specific adaptation.
So we pre-train A to preserve information before adaptation w/ excellent parameter efficiency #NeurIPS2025 #CCFM 👇
1/Serve your PEFT with a fresh IPA!🍺
Finetuning large models is cheaper thanks to LoRA, but is its random init optimal?🤔
Meet IPA: a feature-aware alternative to random projections
#NeurIPS2025 WS #CCFM Oral+Best Paper
Work w/
S. Venkataramanan @tuanhungvu.bsky.social @abursuc.bsky.social M. Cord
🧵
Finetuning large models is cheaper thanks to LoRA, but is its random init optimal?🤔
Meet IPA: a feature-aware alternative to random projections
#NeurIPS2025 WS #CCFM Oral+Best Paper
Work w/
S. Venkataramanan @tuanhungvu.bsky.social @abursuc.bsky.social M. Cord
🧵
December 2, 2025 at 11:16 AM
We fermented our thoughts on understanding LoRA & ended up with IPA🍺
We found an asymmetry in LoRA: during training, A changes little & B eats most task-specific adaptation.
So we pre-train A to preserve information before adaptation w/ excellent parameter efficiency #NeurIPS2025 #CCFM 👇
We found an asymmetry in LoRA: during training, A changes little & B eats most task-specific adaptation.
So we pre-train A to preserve information before adaptation w/ excellent parameter efficiency #NeurIPS2025 #CCFM 👇
I also think that stopping the process and letting ACs decide based on original reviews would be the safest thing to do at this point to avoid any skewed or suspicion of skewed decisions because of the leak #ICLR2026

#ICLR Program chairs, Just stop the process already! We can trust the AC to make decision with reviews and responses but we cannot trust anything that happened since the leak.
November 28, 2025 at 12:34 PM
I also think that stopping the process and letting ACs decide based on original reviews would be the safest thing to do at this point to avoid any skewed or suspicion of skewed decisions because of the leak #ICLR2026
Reposted by Andrei Bursuc
This is by a large margin the most serious problem and mistake in conference peer review I have seen in my career. Apparently a many people were aware of this and many could find out who their reviewers were. This probably has created a large number of unnecessary enmities.
@iclr-conf.bsky.social
@iclr-conf.bsky.social

November 27, 2025 at 7:45 PM
This is by a large margin the most serious problem and mistake in conference peer review I have seen in my career. Apparently a many people were aware of this and many could find out who their reviewers were. This probably has created a large number of unnecessary enmities.
@iclr-conf.bsky.social
@iclr-conf.bsky.social
Check out NAF: an effective ViT feature upsampler to produce excellent (and eye-candy) pixel-level feature maps.
NAF outperform both VFM-specific upsamplers (FeatUp, JAFAR) and VFM-agnostic methods (JBU, AnyUp) over multiple downstream tasks 👇
NAF outperform both VFM-specific upsamplers (FeatUp, JAFAR) and VFM-agnostic methods (JBU, AnyUp) over multiple downstream tasks 👇
Need pixel-level features from your backbone (DINOv3, CLIP, RADIO, FRANCA...)?
🚀Introducing NAF: A universal, zero-shot feature upsampler.
It turns low-res ViT features into pixel-perfect maps.
-⚡ Model-agnostic
-🥇 SoTA results
-🚀 4× faster than SoTA
-📈 Scales up to 2K res
🚀Introducing NAF: A universal, zero-shot feature upsampler.
It turns low-res ViT features into pixel-perfect maps.
-⚡ Model-agnostic
-🥇 SoTA results
-🚀 4× faster than SoTA
-📈 Scales up to 2K res
November 25, 2025 at 6:36 PM
Check out NAF: an effective ViT feature upsampler to produce excellent (and eye-candy) pixel-level feature maps.
NAF outperform both VFM-specific upsamplers (FeatUp, JAFAR) and VFM-agnostic methods (JBU, AnyUp) over multiple downstream tasks 👇
NAF outperform both VFM-specific upsamplers (FeatUp, JAFAR) and VFM-agnostic methods (JBU, AnyUp) over multiple downstream tasks 👇