




Andrei Bursuc
@abursuc.bsky.social
Research Scientist at valeo.ai | Teaching at Polytechnique, ENS | Alumni at Mines Paris, Inria, ENS | AI for Autonomous Driving, Computer Vision, Machine Learning | Robotics amateur
⚲ Paris, France 🔗 abursuc.github.io
⚲ Paris, France 🔗 abursuc.github.io
Post-CVPR deadline run, at last




November 15, 2025 at 12:02 AM
Post-CVPR deadline run, at last
Unlike ICLR reviews, the sunrise never disappoints

November 12, 2025 at 6:36 AM
Unlike ICLR reviews, the sunrise never disappoints
The perks of early risers


October 29, 2025 at 6:20 AM
The perks of early risers
X-mas came earlier this year!
Nvidia has just released the huge Physical AI AV Dataset
- 1727 hrs of driving data: 310K clips of 20s
- sensor rig: 7 cameras, lidar, radar
- 25 countries, 2.5K cities from US + Europe
Kudos to @kashyap7x.bsky.social et al.!
huggingface.co/datasets/nvi...
Nvidia has just released the huge Physical AI AV Dataset
- 1727 hrs of driving data: 310K clips of 20s
- sensor rig: 7 cameras, lidar, radar
- 25 countries, 2.5K cities from US + Europe
Kudos to @kashyap7x.bsky.social et al.!
huggingface.co/datasets/nvi...
October 28, 2025 at 9:59 PM
X-mas came earlier this year!
Nvidia has just released the huge Physical AI AV Dataset
- 1727 hrs of driving data: 310K clips of 20s
- sensor rig: 7 cameras, lidar, radar
- 25 countries, 2.5K cities from US + Europe
Kudos to @kashyap7x.bsky.social et al.!
huggingface.co/datasets/nvi...
Nvidia has just released the huge Physical AI AV Dataset
- 1727 hrs of driving data: 310K clips of 20s
- sensor rig: 7 cameras, lidar, radar
- 25 countries, 2.5K cities from US + Europe
Kudos to @kashyap7x.bsky.social et al.!
huggingface.co/datasets/nvi...
Some practical info:
🗓️date: Sun, Oct 11
📍room: 312
💻url: opendrivelab.com/iccv2025/wor...
A shout-out to our incredible organization team: H. Li, P. Krähenbühl, @kashyap7x.bsky.social, E. Jang, L. Chen,
and the restless H. Wang
#ICCV2025
🗓️date: Sun, Oct 11
📍room: 312
💻url: opendrivelab.com/iccv2025/wor...
A shout-out to our incredible organization team: H. Li, P. Krähenbühl, @kashyap7x.bsky.social, E. Jang, L. Chen,
and the restless H. Wang
#ICCV2025

October 19, 2025 at 8:33 PM
Some practical info:
🗓️date: Sun, Oct 11
📍room: 312
💻url: opendrivelab.com/iccv2025/wor...
A shout-out to our incredible organization team: H. Li, P. Krähenbühl, @kashyap7x.bsky.social, E. Jang, L. Chen,
and the restless H. Wang
#ICCV2025
🗓️date: Sun, Oct 11
📍room: 312
💻url: opendrivelab.com/iccv2025/wor...
A shout-out to our incredible organization team: H. Li, P. Krähenbühl, @kashyap7x.bsky.social, E. Jang, L. Chen,
and the restless H. Wang
#ICCV2025
🗒️Here's an outline of the program:
- a suite of not-to miss speakers and talks at the edge of embodied AI nowadays
- the main takeaways and winners of the NAVSIMv2 End-to-End Driving & the World Model Challenges by 1x (2nd edition)
- a debate w/ speakers & audience
#ICCV2025
- a suite of not-to miss speakers and talks at the edge of embodied AI nowadays
- the main takeaways and winners of the NAVSIMv2 End-to-End Driving & the World Model Challenges by 1x (2nd edition)
- a debate w/ speakers & audience
#ICCV2025

October 19, 2025 at 8:30 PM
🗒️Here's an outline of the program:
- a suite of not-to miss speakers and talks at the edge of embodied AI nowadays
- the main takeaways and winners of the NAVSIMv2 End-to-End Driving & the World Model Challenges by 1x (2nd edition)
- a debate w/ speakers & audience
#ICCV2025
- a suite of not-to miss speakers and talks at the edge of embodied AI nowadays
- the main takeaways and winners of the NAVSIMv2 End-to-End Driving & the World Model Challenges by 1x (2nd edition)
- a debate w/ speakers & audience
#ICCV2025
Today is the day for our @iccv.bsky.social
workshop that we've been cooking with excitement in the past months.
Learning to See: Advancing Spatial Understanding for Embodied Intelligence #ICCV2025
Join us!
opendrivelab.com/iccv2025/wor...
workshop that we've been cooking with excitement in the past months.
Learning to See: Advancing Spatial Understanding for Embodied Intelligence #ICCV2025
Join us!
opendrivelab.com/iccv2025/wor...

October 19, 2025 at 8:29 PM
Today is the day for our @iccv.bsky.social
workshop that we've been cooking with excitement in the past months.
Learning to See: Advancing Spatial Understanding for Embodied Intelligence #ICCV2025
Join us!
opendrivelab.com/iccv2025/wor...
workshop that we've been cooking with excitement in the past months.
Learning to See: Advancing Spatial Understanding for Embodied Intelligence #ICCV2025
Join us!
opendrivelab.com/iccv2025/wor...
Trying to mitigate ICCV FOMO today.
Staying at home this time.
Have fun everybody!
Staying at home this time.
Have fun everybody!




October 18, 2025 at 1:41 PM
Trying to mitigate ICCV FOMO today.
Staying at home this time.
Have fun everybody!
Staying at home this time.
Have fun everybody!





Some night runs seem more like sightseeing than running




October 2, 2025 at 8:56 AM
Some night runs seem more like sightseeing than running
In my brain every time I connect to overleaf during deadline periods, I see this
September 24, 2025 at 6:55 PM
In my brain every time I connect to overleaf during deadline periods, I see this
A new season in full swing with a winning duo: kids do hockey, dad does overleaf

September 20, 2025 at 8:15 AM
A new season in full swing with a winning duo: kids do hockey, dad does overleaf
The French often mention the roundabout at Arc de Triomphe as one of the ultimate tests for a self-driving vehicle.
I would say that the equivalent for humanoid robots would be to unwrap Chupa Chups Lollipop.
Take that Embodied AI!
I would say that the equivalent for humanoid robots would be to unwrap Chupa Chups Lollipop.
Take that Embodied AI!

September 19, 2025 at 10:32 PM
The French often mention the roundabout at Arc de Triomphe as one of the ultimate tests for a self-driving vehicle.
I would say that the equivalent for humanoid robots would be to unwrap Chupa Chups Lollipop.
Take that Embodied AI!
I would say that the equivalent for humanoid robots would be to unwrap Chupa Chups Lollipop.
Take that Embodied AI!
Quite a hefty video dataset just released: 7K hours of video with various annotations: camera pose, depth maps, dynamic object masks, scene text descriptions (camera, motion trends, summary)
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations nju-3dv.github.io/projects/Spa...
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations nju-3dv.github.io/projects/Spa...

September 15, 2025 at 10:00 PM
Quite a hefty video dataset just released: 7K hours of video with various annotations: camera pose, depth maps, dynamic object masks, scene text descriptions (camera, motion trends, summary)
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations nju-3dv.github.io/projects/Spa...
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations nju-3dv.github.io/projects/Spa...




Look what I got in my mail today: the new book @thomwolf.bsky.social
The ultra-scale playbook: Training LLMs on large GPU clusters 🚀
The ultra-scale playbook: Training LLMs on large GPU clusters 🚀

August 19, 2025 at 8:44 PM
Look what I got in my mail today: the new book @thomwolf.bsky.social
The ultra-scale playbook: Training LLMs on large GPU clusters 🚀
The ultra-scale playbook: Training LLMs on large GPU clusters 🚀
I'm still not fully used with these particular causal masks
Image
Image

August 16, 2025 at 9:39 PM
I'm still not fully used with these particular causal masks
Image
Image
Time to update your bag of default picks for your ViT architectures

August 15, 2025 at 1:56 PM
Time to update your bag of default picks for your ViT architectures
Wow! Indeed impressive.
I had a similar surprise not long ago when stumbling upon LED shuttlecocks for night badminton.
I had a similar surprise not long ago when stumbling upon LED shuttlecocks for night badminton.

August 13, 2025 at 9:10 AM
Wow! Indeed impressive.
I had a similar surprise not long ago when stumbling upon LED shuttlecocks for night badminton.
I had a similar surprise not long ago when stumbling upon LED shuttlecocks for night badminton.
Training with such synthetic data improves performance on lane detection, 3d object detection (from cameras or from Lidar), policy learning
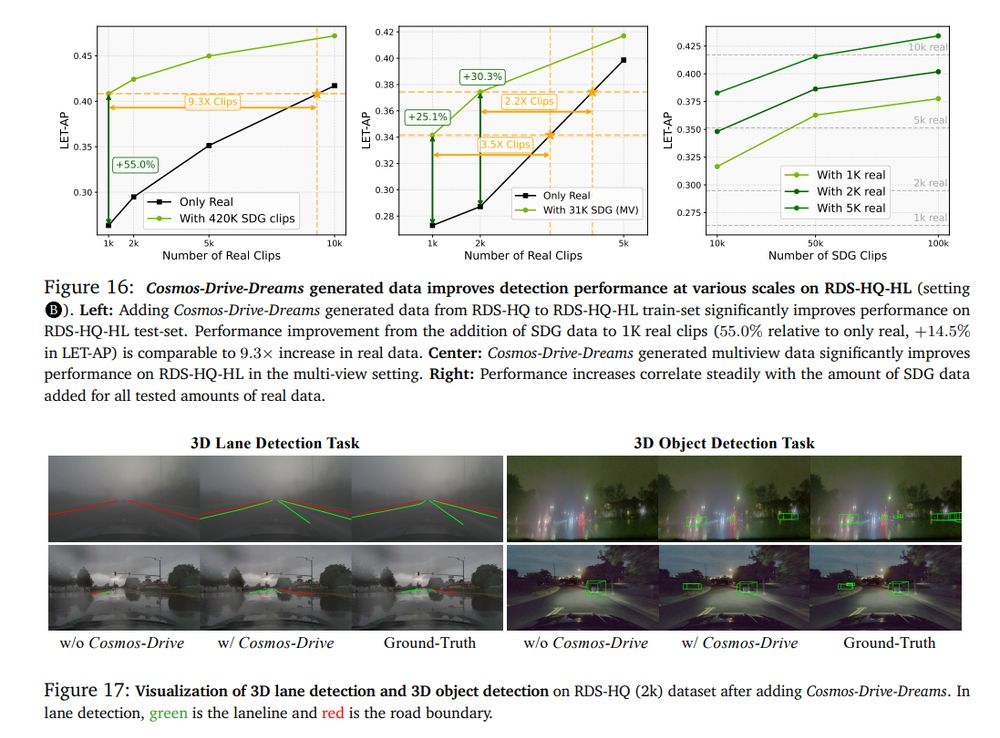

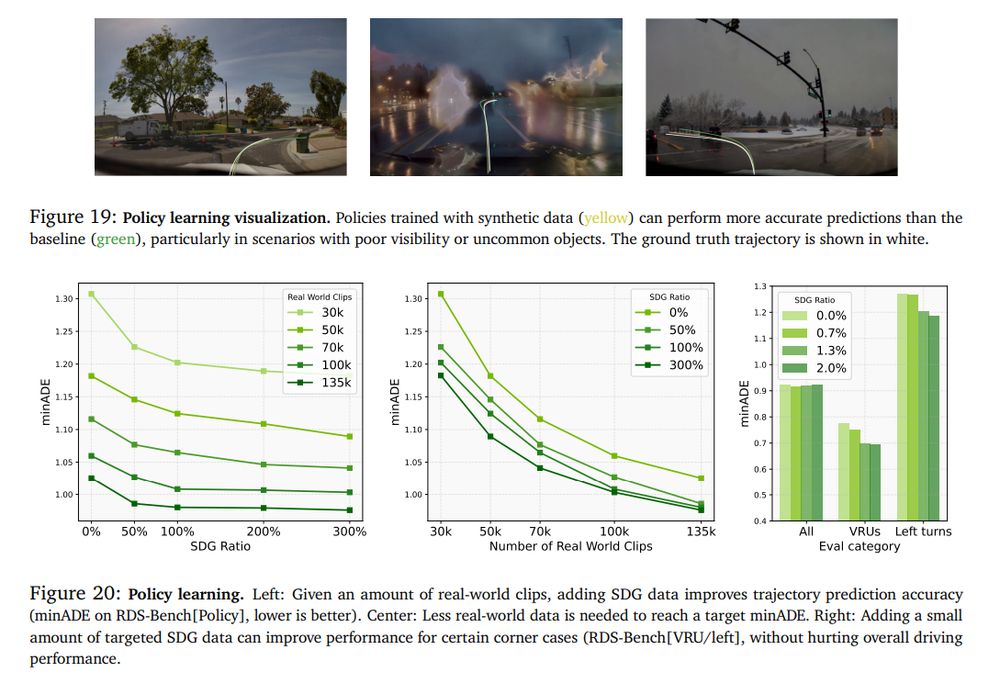
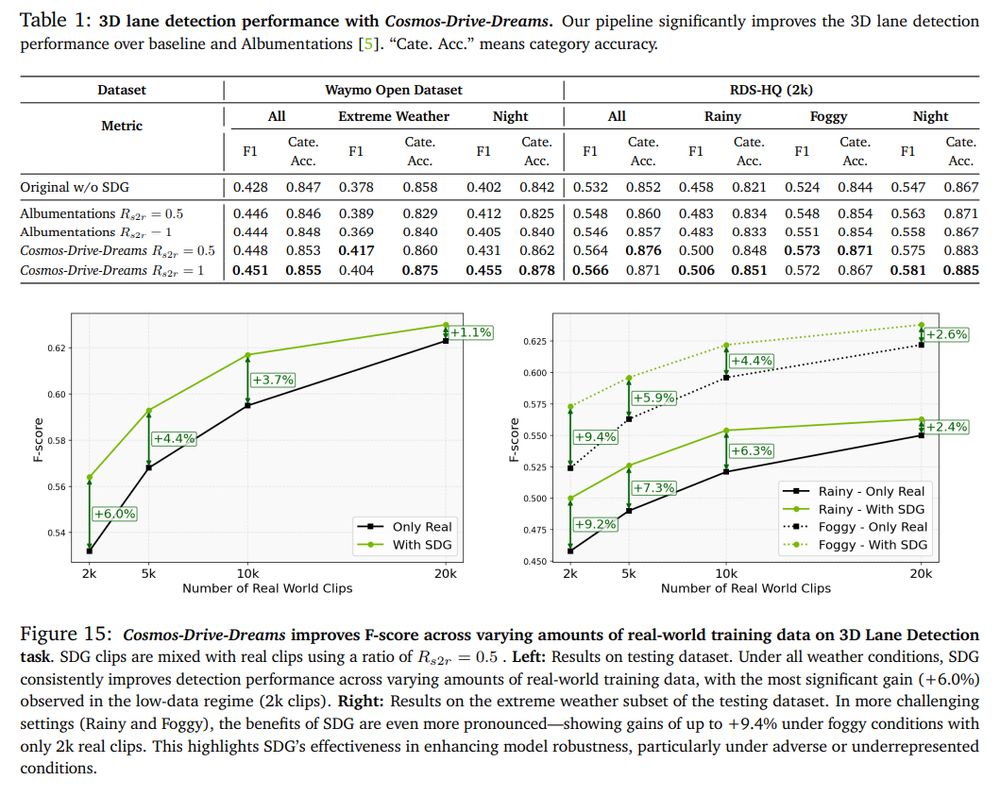
August 6, 2025 at 8:38 PM
Training with such synthetic data improves performance on lane detection, 3d object detection (from cameras or from Lidar), policy learning
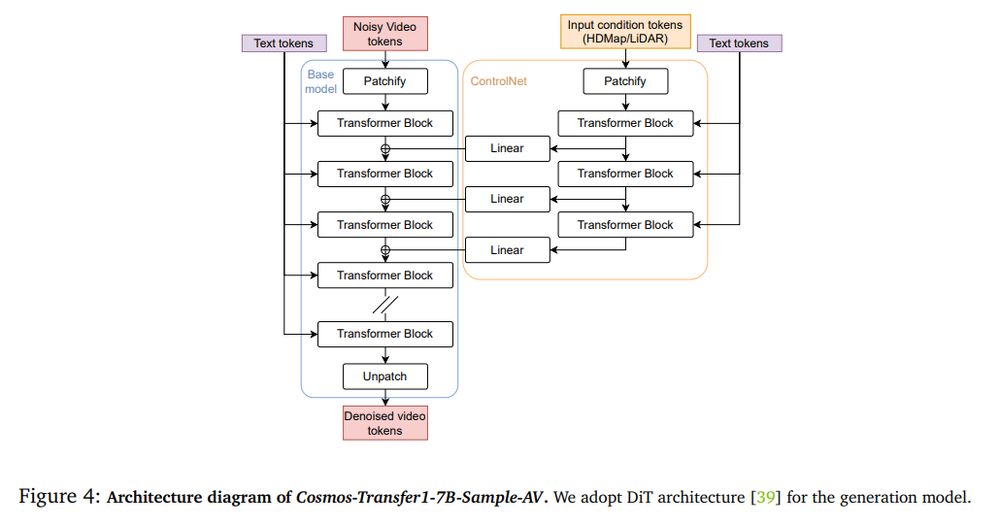
You can train different forms of generative models (diffusion) and conditionings, including text: camera to lidar, hdmap to camera, camera to hdmap + lidar, single camera to multi-camera, ...
They have a unified architecture for point clouds and images
They have a unified architecture for point clouds and images
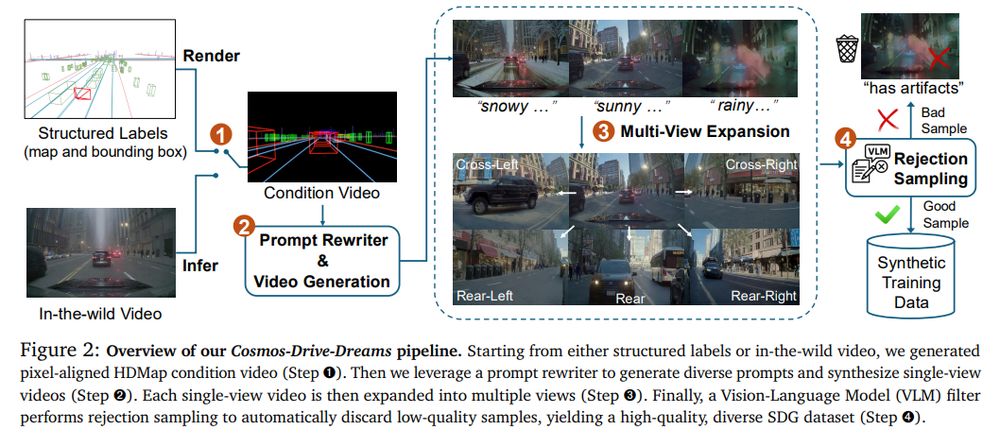
August 6, 2025 at 8:38 PM
You can train different forms of generative models (diffusion) and conditionings, including text: camera to lidar, hdmap to camera, camera to hdmap + lidar, single camera to multi-camera, ...
They have a unified architecture for point clouds and images
They have a unified architecture for point clouds and images
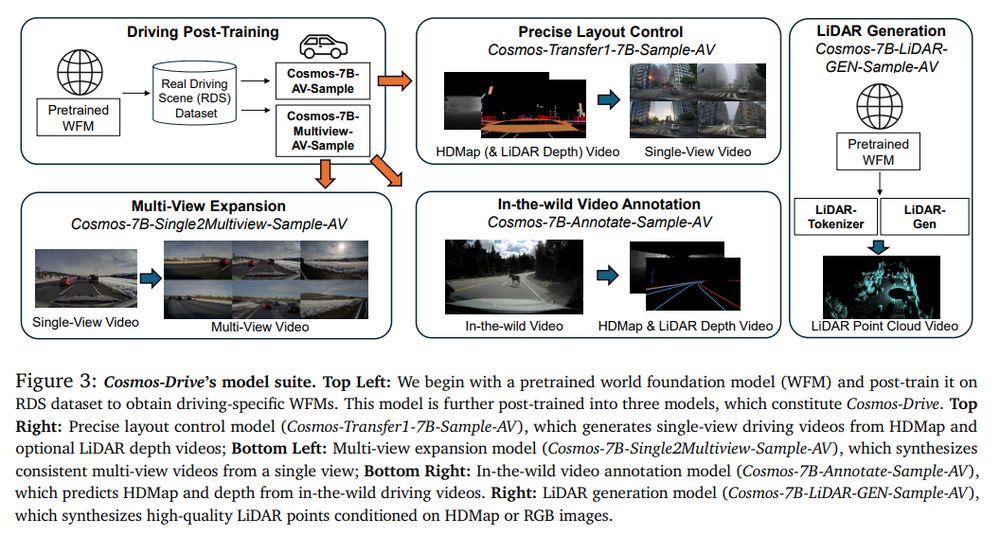
They compile a driving dataset with multi-cameras and high quality annotations RDS-HQ of 750hours of 30 fps 6-camera videos. They release a subset of 5842 clips of 10 seconds with lane and box annotations, hdmap, camera extrinsics+intrinsics
August 6, 2025 at 8:38 PM
They compile a driving dataset with multi-cameras and high quality annotations RDS-HQ of 750hours of 30 fps 6-camera videos. They release a subset of 5842 clips of 10 seconds with lane and box annotations, hdmap, camera extrinsics+intrinsics
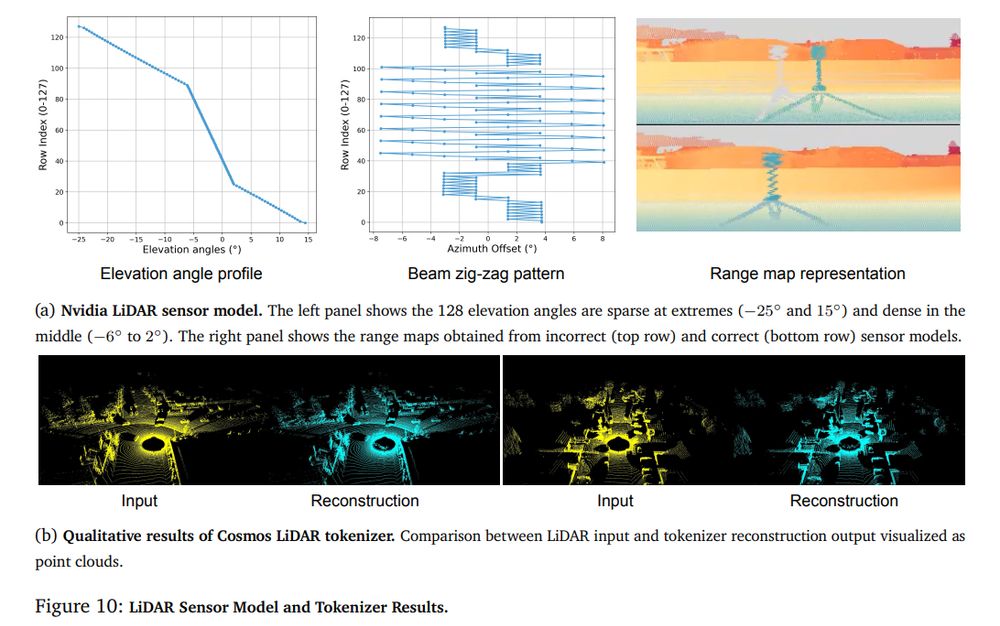
The authors start looking at Lidar and train a Lidar tokenizer starting from Cosmos and range images. The key ingredients to make it work are: row repetition x 4 on range images, motion compensations, high precision on depth fp32
August 6, 2025 at 8:37 PM
The authors start looking at Lidar and train a Lidar tokenizer starting from Cosmos and range images. The key ingredients to make it work are: row repetition x 4 on range images, motion compensations, high precision on depth fp32
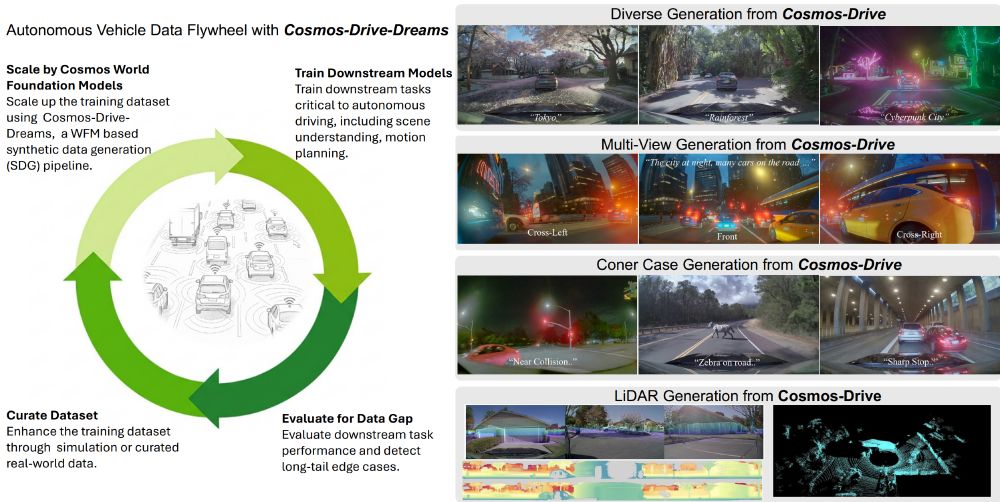
It becomes difficult to keep track of all the Cosmos variants released out there.
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
August 6, 2025 at 8:37 PM
It becomes difficult to keep track of all the Cosmos variants released out there.
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models