



Adhiraj Ghosh@ACL2025
@adhirajghosh.bsky.social
ELLIS PhD, University of Tübingen | Data-centric Vision and Language @bethgelab.bsky.social
Website: adhirajghosh.github.io
Twitter: https://x.com/adhiraj_ghosh98
Website: adhirajghosh.github.io
Twitter: https://x.com/adhiraj_ghosh98
I feel like my “following” and “popular with friends” feeds are well tuned as I have complete control over them. Just that people still are posting less on bsky and are more active on Twitter. Once that changes (and I think it will), we’ll have the same experience as it is on Twitter right now.
January 12, 2025 at 11:34 PM
I feel like my “following” and “popular with friends” feeds are well tuned as I have complete control over them. Just that people still are posting less on bsky and are more active on Twitter. Once that changes (and I think it will), we’ll have the same experience as it is on Twitter right now.
Welcome, stranger
December 10, 2024 at 9:25 PM
Welcome, stranger
This extremely ambitious project would not have been possible without @dziadzio.bsky.social @bayesiankitten.bsky.social @vishaalurao.bsky.social @samuelalbanie.bsky.social and Matthias Bethge!
Special thanks to everyone at @bethgelab.bsky.social, Bo Li, Yujie Lu and Palzer Lama for all your help!
Special thanks to everyone at @bethgelab.bsky.social, Bo Li, Yujie Lu and Palzer Lama for all your help!
December 10, 2024 at 5:52 PM
This extremely ambitious project would not have been possible without @dziadzio.bsky.social @bayesiankitten.bsky.social @vishaalurao.bsky.social @samuelalbanie.bsky.social and Matthias Bethge!
Special thanks to everyone at @bethgelab.bsky.social, Bo Li, Yujie Lu and Palzer Lama for all your help!
Special thanks to everyone at @bethgelab.bsky.social, Bo Li, Yujie Lu and Palzer Lama for all your help!
In summary, we release ONEBench as a valuable tool for comprehensively evaluating foundation models and generating customised benchmarks, in the hopes of sparking a restructuring how benchmarking is done. We plan on publishing the code, benchmark and metadata for capability probing very soon.
December 10, 2024 at 5:51 PM
In summary, we release ONEBench as a valuable tool for comprehensively evaluating foundation models and generating customised benchmarks, in the hopes of sparking a restructuring how benchmarking is done. We plan on publishing the code, benchmark and metadata for capability probing very soon.
Finally, we probe open-ended capabilities by defining a query pool to test, as proof-of-concept, and generating personalised model rankings. Expanding ONEBench can only improve reliability and scale of these queries and we’re excited to extend this framework.
More insights like these in the paper!
More insights like these in the paper!

December 10, 2024 at 5:50 PM
Finally, we probe open-ended capabilities by defining a query pool to test, as proof-of-concept, and generating personalised model rankings. Expanding ONEBench can only improve reliability and scale of these queries and we’re excited to extend this framework.
More insights like these in the paper!
More insights like these in the paper!
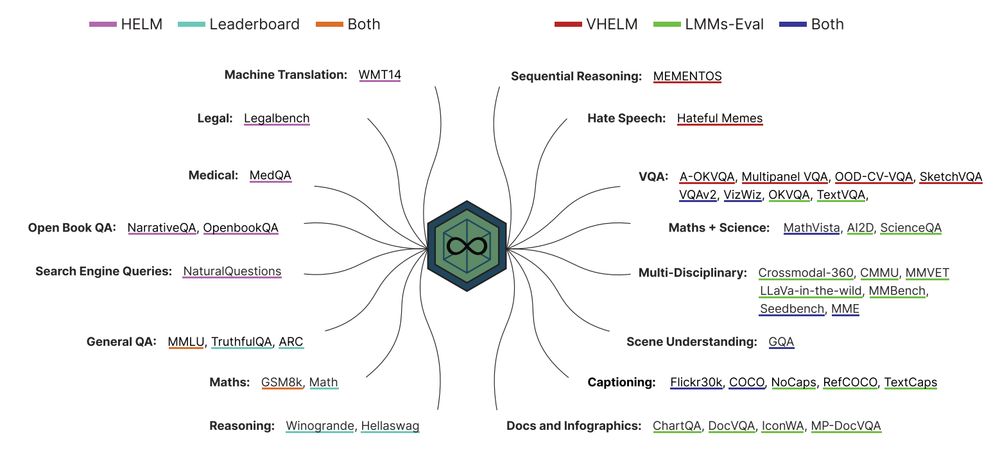
Let's look under the hood! ONEBench comprises ONEBench-LLM, and ONEBench-LMM: the largest pool of evaluation samples for foundation models(~50K for LLMs and ~600K for LMMs), spanning various domains and tasks. ONEBench will be continually expanded to accommodate more models and datasets.
December 10, 2024 at 5:49 PM
Let's look under the hood! ONEBench comprises ONEBench-LLM, and ONEBench-LMM: the largest pool of evaluation samples for foundation models(~50K for LLMs and ~600K for LMMs), spanning various domains and tasks. ONEBench will be continually expanded to accommodate more models and datasets.
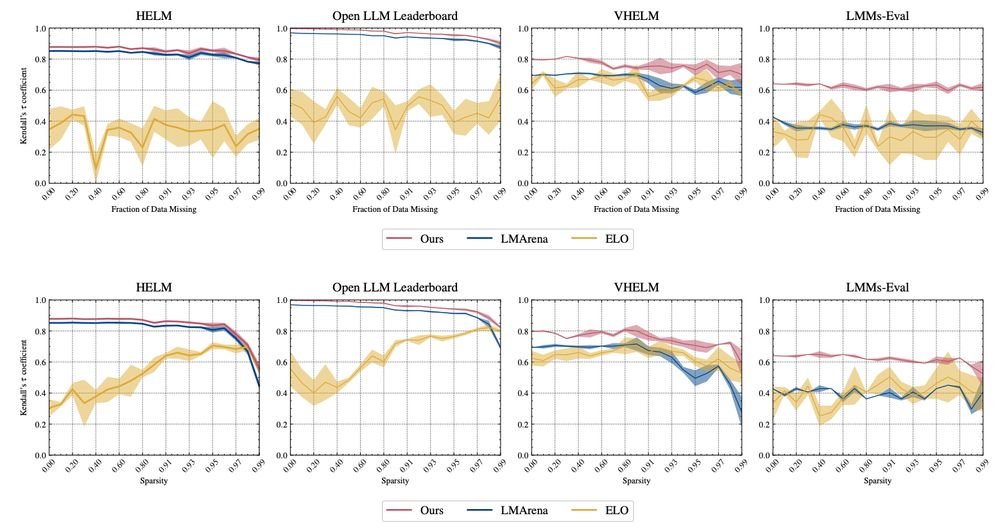
We compare our Plackett-Luce implementation to ELO and ELO-distribution based ranking methods, not only showing superior correlation to the aggregated mean model scores for each test set but also extremely stable correlations to missing datapoints and missing measurements, even up to 95% sparsity!
December 10, 2024 at 5:49 PM
We compare our Plackett-Luce implementation to ELO and ELO-distribution based ranking methods, not only showing superior correlation to the aggregated mean model scores for each test set but also extremely stable correlations to missing datapoints and missing measurements, even up to 95% sparsity!