


Adhiraj Ghosh@ACL2025
@adhirajghosh.bsky.social
ELLIS PhD, University of Tübingen | Data-centric Vision and Language @bethgelab.bsky.social
Website: adhirajghosh.github.io
Twitter: https://x.com/adhiraj_ghosh98
Website: adhirajghosh.github.io
Twitter: https://x.com/adhiraj_ghosh98
Excited to be in Vienna for #ACL2025 🇦🇹!You'll find @dziadzio.bsky.social and I by our ONEBench poster, so do drop by!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!

July 27, 2025 at 10:26 PM
Excited to be in Vienna for #ACL2025 🇦🇹!You'll find @dziadzio.bsky.social and I by our ONEBench poster, so do drop by!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!
🗓️Wed, July 30, 11-12:30 CET
📍Hall 4/5
I’m also excited to talk about lifelong and personalised benchmarking, data curation and vision-language in general! Let’s connect!
Finally, we probe open-ended capabilities by defining a query pool to test, as proof-of-concept, and generating personalised model rankings. Expanding ONEBench can only improve reliability and scale of these queries and we’re excited to extend this framework.
More insights like these in the paper!
More insights like these in the paper!

December 10, 2024 at 5:50 PM
Finally, we probe open-ended capabilities by defining a query pool to test, as proof-of-concept, and generating personalised model rankings. Expanding ONEBench can only improve reliability and scale of these queries and we’re excited to extend this framework.
More insights like these in the paper!
More insights like these in the paper!
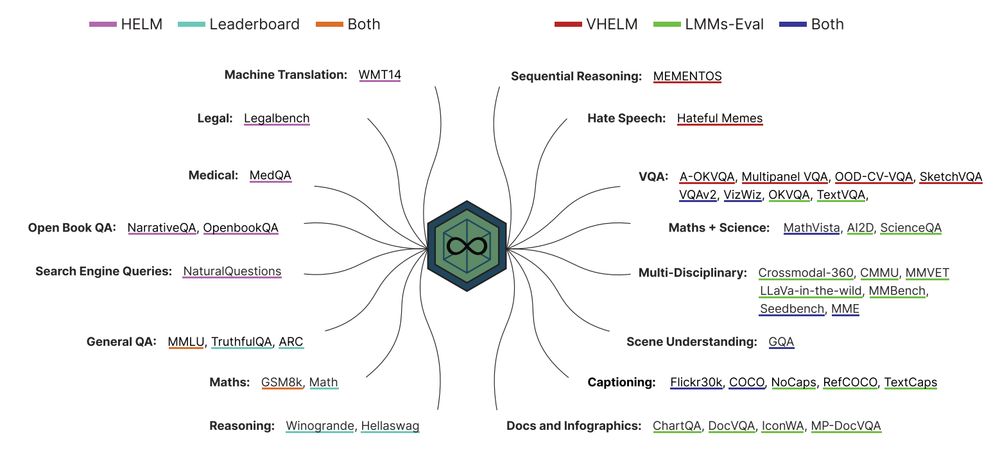
Let's look under the hood! ONEBench comprises ONEBench-LLM, and ONEBench-LMM: the largest pool of evaluation samples for foundation models(~50K for LLMs and ~600K for LMMs), spanning various domains and tasks. ONEBench will be continually expanded to accommodate more models and datasets.
December 10, 2024 at 5:49 PM
Let's look under the hood! ONEBench comprises ONEBench-LLM, and ONEBench-LMM: the largest pool of evaluation samples for foundation models(~50K for LLMs and ~600K for LMMs), spanning various domains and tasks. ONEBench will be continually expanded to accommodate more models and datasets.
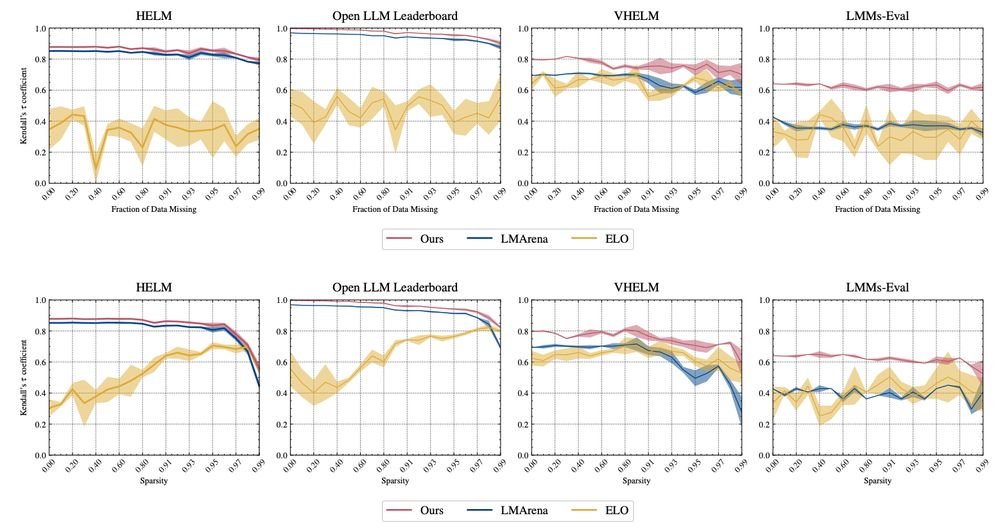
We compare our Plackett-Luce implementation to ELO and ELO-distribution based ranking methods, not only showing superior correlation to the aggregated mean model scores for each test set but also extremely stable correlations to missing datapoints and missing measurements, even up to 95% sparsity!
December 10, 2024 at 5:49 PM
We compare our Plackett-Luce implementation to ELO and ELO-distribution based ranking methods, not only showing superior correlation to the aggregated mean model scores for each test set but also extremely stable correlations to missing datapoints and missing measurements, even up to 95% sparsity!
✅ ONEBench uses these rankings and aggregates them using the Plackett-Luce framework: providing an extremely efficient MLE from the aggregated probabilities of individual rankings, resulting in an estimate of the parameters of the strength(or utility value) of models in a ranking.

December 10, 2024 at 5:48 PM
✅ ONEBench uses these rankings and aggregates them using the Plackett-Luce framework: providing an extremely efficient MLE from the aggregated probabilities of individual rankings, resulting in an estimate of the parameters of the strength(or utility value) of models in a ranking.
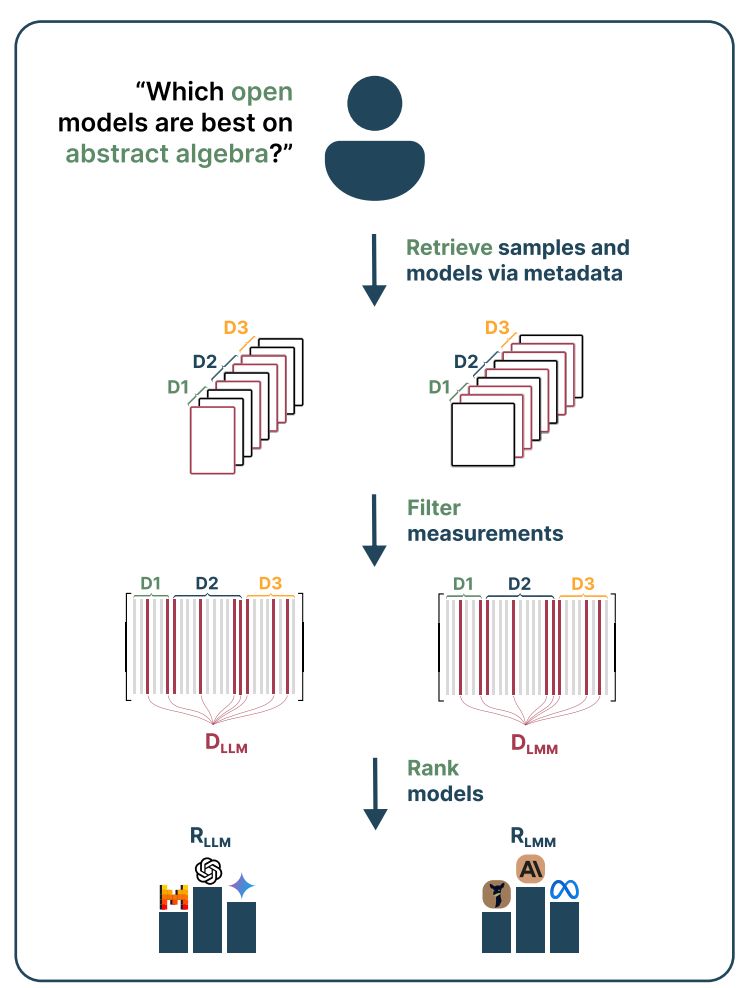
Given a query of interest from a practitioner, we are able to pick relevant samples from the data pool by top-k retrieval in the embedding space or searching through sample-specific metadata.
Aggregating through relevant samples and model performance on them, we obtain our final model rankings.
Aggregating through relevant samples and model performance on them, we obtain our final model rankings.
December 10, 2024 at 5:45 PM
Given a query of interest from a practitioner, we are able to pick relevant samples from the data pool by top-k retrieval in the embedding space or searching through sample-specific metadata.
Aggregating through relevant samples and model performance on them, we obtain our final model rankings.
Aggregating through relevant samples and model performance on them, we obtain our final model rankings.
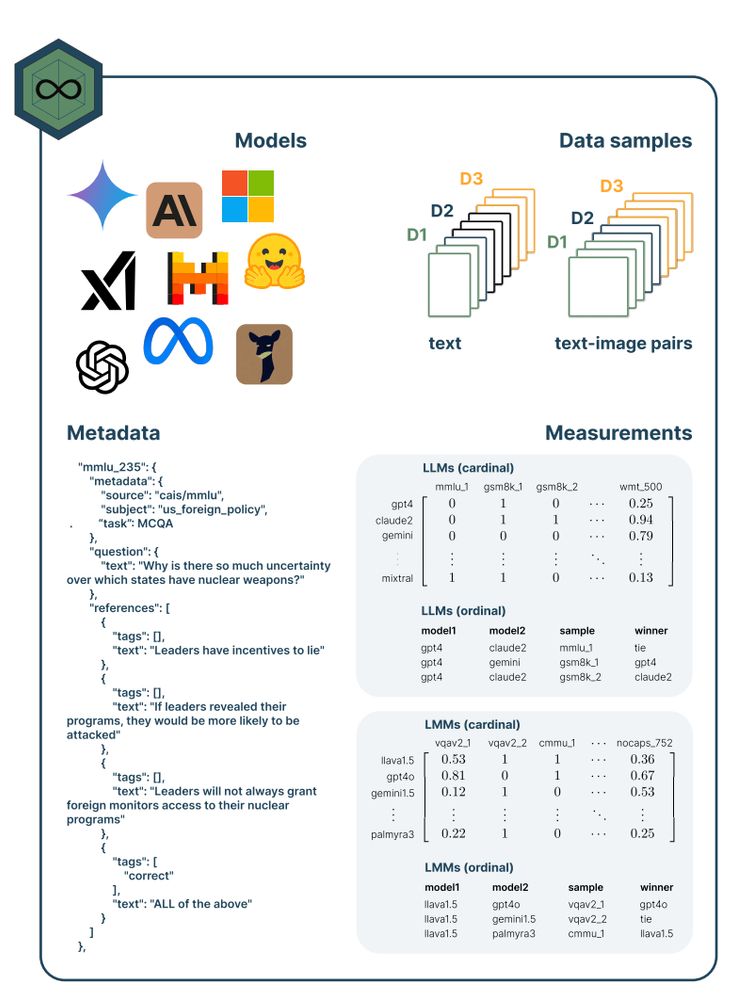
❗Status quo: Benchmarking on large testsets is costly. Static benchmarks fail to use truly held-out data and also can’t probe the ever-evolving capabilities of LLMs/VLMs.
ONEBench mitigates this by re-structuring static benchmarks to accommodate an ever-expanding pool of datasets and models.
ONEBench mitigates this by re-structuring static benchmarks to accommodate an ever-expanding pool of datasets and models.
December 10, 2024 at 5:45 PM
❗Status quo: Benchmarking on large testsets is costly. Static benchmarks fail to use truly held-out data and also can’t probe the ever-evolving capabilities of LLMs/VLMs.
ONEBench mitigates this by re-structuring static benchmarks to accommodate an ever-expanding pool of datasets and models.
ONEBench mitigates this by re-structuring static benchmarks to accommodate an ever-expanding pool of datasets and models.
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745

December 10, 2024 at 5:44 PM
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745