



Thaddäus Wiedemer
@thwiedemer.bsky.social
Intern at Google Deepmind Toronto | PhD student in ML at Max Planck Institute Tübingen and University of Tübingen.
Pinned
Thaddäus Wiedemer
@thwiedemer.bsky.social
· Sep 25

Are we experiencing a 'GPT moment' in vision?
In our new preprint, we show that generative video models can solve a wide range of tasks across the entire vision stack without being explicitly trained for it.
🌐 video-zero-shot.github.io
1/n
In our new preprint, we show that generative video models can solve a wide range of tasks across the entire vision stack without being explicitly trained for it.
🌐 video-zero-shot.github.io
1/n
How useful are self-generated 'mental images' (visual aids) in MLLM/UMM reasoning?
Turns out: currently not very. Visualizations have small errors that compound in multi-step problems, and models often ignore correct visual aids in their decision making.
Turns out: currently not very. Visualizations have small errors that compound in multi-step problems, and models often ignore correct visual aids in their decision making.

Can AI reason by “imagining” — not just by seeing or reading?
We introduce Mentis Oculi, a benchmark for machine mental imagery: multi-step visual puzzles that require maintaining and updating visual states over time.
📄 arxiv.org/abs/2602.02465
🌐 jana-z.github.io/mentis-oculi/
🧵⬇️
We introduce Mentis Oculi, a benchmark for machine mental imagery: multi-step visual puzzles that require maintaining and updating visual states over time.
📄 arxiv.org/abs/2602.02465
🌐 jana-z.github.io/mentis-oculi/
🧵⬇️
February 3, 2026 at 9:50 AM
How useful are self-generated 'mental images' (visual aids) in MLLM/UMM reasoning?
Turns out: currently not very. Visualizations have small errors that compound in multi-step problems, and models often ignore correct visual aids in their decision making.
Turns out: currently not very. Visualizations have small errors that compound in multi-step problems, and models often ignore correct visual aids in their decision making.
Reposted by Thaddäus Wiedemer

🚀 We're hiring! The @ellisinsttue.bsky.social leads the AI development for Germany’s new open-source nationwide Adaptive Intelligent System learning platform for schools (as part of a consortium led by Assecor & KI macht Schule, and mandated by the FWU).
👉 Apply now: forms.gle/XmLkwEDD45fY...
👉 Apply now: forms.gle/XmLkwEDD45fY...

December 15, 2025 at 1:37 PM
🚀 We're hiring! The @ellisinsttue.bsky.social leads the AI development for Germany’s new open-source nationwide Adaptive Intelligent System learning platform for schools (as part of a consortium led by Assecor & KI macht Schule, and mandated by the FWU).
👉 Apply now: forms.gle/XmLkwEDD45fY...
👉 Apply now: forms.gle/XmLkwEDD45fY...
Reposted by Thaddäus Wiedemer
🎉 Excited to present our paper VGGSounder: Audio‑Visual Evaluations for Foundation Models today at #ICCV2025!
🕦 Poster Session 1 | 11:30–13:30
📍 Poster #88
Come by if you're into audio-visual learning and want to know whether multiple modalities actually help or hurt.
🕦 Poster Session 1 | 11:30–13:30
📍 Poster #88
Come by if you're into audio-visual learning and want to know whether multiple modalities actually help or hurt.
October 21, 2025 at 6:06 PM
🎉 Excited to present our paper VGGSounder: Audio‑Visual Evaluations for Foundation Models today at #ICCV2025!
🕦 Poster Session 1 | 11:30–13:30
📍 Poster #88
Come by if you're into audio-visual learning and want to know whether multiple modalities actually help or hurt.
🕦 Poster Session 1 | 11:30–13:30
📍 Poster #88
Come by if you're into audio-visual learning and want to know whether multiple modalities actually help or hurt.
Are we experiencing a 'GPT moment' in vision?
In our new preprint, we show that generative video models can solve a wide range of tasks across the entire vision stack without being explicitly trained for it.
🌐 video-zero-shot.github.io
1/n
In our new preprint, we show that generative video models can solve a wide range of tasks across the entire vision stack without being explicitly trained for it.
🌐 video-zero-shot.github.io
1/n
September 25, 2025 at 5:02 PM
Are we experiencing a 'GPT moment' in vision?
In our new preprint, we show that generative video models can solve a wide range of tasks across the entire vision stack without being explicitly trained for it.
🌐 video-zero-shot.github.io
1/n
In our new preprint, we show that generative video models can solve a wide range of tasks across the entire vision stack without being explicitly trained for it.
🌐 video-zero-shot.github.io
1/n
Check out our newest paper!
As always, it was super fun working on this with @prasannamayil.bsky.social
As always, it was super fun working on this with @prasannamayil.bsky.social

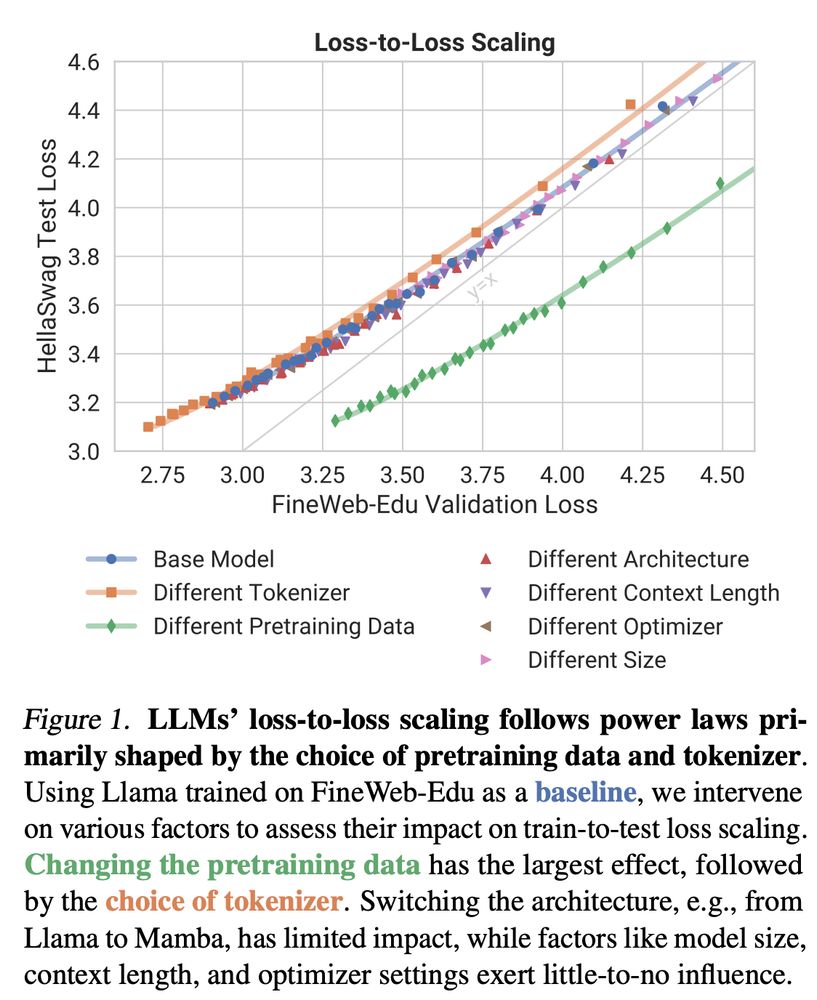
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
February 18, 2025 at 2:12 PM
Check out our newest paper!
As always, it was super fun working on this with @prasannamayil.bsky.social
As always, it was super fun working on this with @prasannamayil.bsky.social
Reposted by Thaddäus Wiedemer

CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
February 17, 2025 at 6:22 PM
CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Reposted by Thaddäus Wiedemer
🚀 We’re hiring! Join Bernhard Schölkopf & me at @ellisinsttue.bsky.social to push the frontier of #AI in education!
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...

February 11, 2025 at 4:34 PM
🚀 We’re hiring! Join Bernhard Schölkopf & me at @ellisinsttue.bsky.social to push the frontier of #AI in education!
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...