



Aidan Sirbu
@sirbu.bsky.social
MSc Student @ Mila and McGill
ML & NeuroAI research
ML & NeuroAI research
Reposted by Aidan Sirbu


November 15, 2025 at 10:13 PM
Reposted by Aidan Sirbu

LLMs are trained to compress data by mapping sequences to high-dim representations!
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM

October 31, 2025 at 4:19 PM
LLMs are trained to compress data by mapping sequences to high-dim representations!
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
Reposted by Aidan Sirbu

Over the past year, my lab has been working on fleshing out theory + applications of the Platonic Representation Hypothesis.
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
October 10, 2025 at 10:13 PM
Over the past year, my lab has been working on fleshing out theory + applications of the Platonic Representation Hypothesis.
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
Reposted by Aidan Sirbu

🚨 New preprint alert!
🧠🤖
We propose a theory of how learning curriculum affects generalization through neural population dimensionality. Learning curriculum is a determining factor of neural dimensionality - where you start from determines where you end up.
🧠📈
A 🧵:
tinyurl.com/yr8tawj3
🧠🤖
We propose a theory of how learning curriculum affects generalization through neural population dimensionality. Learning curriculum is a determining factor of neural dimensionality - where you start from determines where you end up.
🧠📈
A 🧵:
tinyurl.com/yr8tawj3

The curriculum effect in visual learning: the role of readout dimensionality
Generalization of visual perceptual learning (VPL) to unseen conditions varies across tasks. Previous work suggests that training curriculum may be integral to generalization, yet a theoretical explan...
tinyurl.com
September 30, 2025 at 2:26 PM
🚨 New preprint alert!
🧠🤖
We propose a theory of how learning curriculum affects generalization through neural population dimensionality. Learning curriculum is a determining factor of neural dimensionality - where you start from determines where you end up.
🧠📈
A 🧵:
tinyurl.com/yr8tawj3
🧠🤖
We propose a theory of how learning curriculum affects generalization through neural population dimensionality. Learning curriculum is a determining factor of neural dimensionality - where you start from determines where you end up.
🧠📈
A 🧵:
tinyurl.com/yr8tawj3
A big congratulations to my supervisor for this awesome achievement. Excited to see where this will go!
1/4) I’m excited to announce that I have joined the Paradigms of Intelligence team at Google (github.com/paradigms-of...)! Our team, led by @blaiseaguera.bsky.social, is bringing forward the next stage of AI by pushing on some of the assumptions that underpin current ML.
#MLSky #AI #neuroscience
#MLSky #AI #neuroscience

Paradigms of Intelligence Team
Advance our understanding of how intelligence evolves to develop new technologies for the benefit of humanity and other sentient life - Paradigms of Intelligence Team
github.com
September 23, 2025 at 4:27 PM
A big congratulations to my supervisor for this awesome achievement. Excited to see where this will go!
Reposted by Aidan Sirbu

🧵 Everyone is chasing new diffusion models—but what about the representations they model from?
We introduce Discrete Latent Codes (DLCs):
- Discrete representation for diffusion models
- Uncond. gen. SOTA FID (1.59 on ImageNet)
- Compositional generation
- Integrates with LLM
🧱
We introduce Discrete Latent Codes (DLCs):
- Discrete representation for diffusion models
- Uncond. gen. SOTA FID (1.59 on ImageNet)
- Compositional generation
- Integrates with LLM
🧱

July 22, 2025 at 2:41 PM
🧵 Everyone is chasing new diffusion models—but what about the representations they model from?
We introduce Discrete Latent Codes (DLCs):
- Discrete representation for diffusion models
- Uncond. gen. SOTA FID (1.59 on ImageNet)
- Compositional generation
- Integrates with LLM
🧱
We introduce Discrete Latent Codes (DLCs):
- Discrete representation for diffusion models
- Uncond. gen. SOTA FID (1.59 on ImageNet)
- Compositional generation
- Integrates with LLM
🧱
Reposted by Aidan Sirbu

New preprint! 🧠🤖
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and even species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and even species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7

June 6, 2025 at 5:40 PM
New preprint! 🧠🤖
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and even species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and even species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7
Reposted by Aidan Sirbu

Preprint Alert 🚀
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)

May 14, 2025 at 12:53 PM
Preprint Alert 🚀
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
Reposted by Aidan Sirbu

This can be a game changer for embodied #NeuroAI.
Or it *could* be, if it were open source.
Just imagine the resources it takes to develop an open version of this model. Now think about how much innovation could come from building on this, rather than just trying to recreate it (at best).
Or it *could* be, if it were open source.
Just imagine the resources it takes to develop an open version of this model. Now think about how much innovation could come from building on this, rather than just trying to recreate it (at best).

Really cool new work out of Deep Mind for video game world generation using latent diffusion! Soon you'll be able to speed run a game just by tricking a model to morph you from one location to another.
deepmind.google/discover/blo...
deepmind.google/discover/blo...
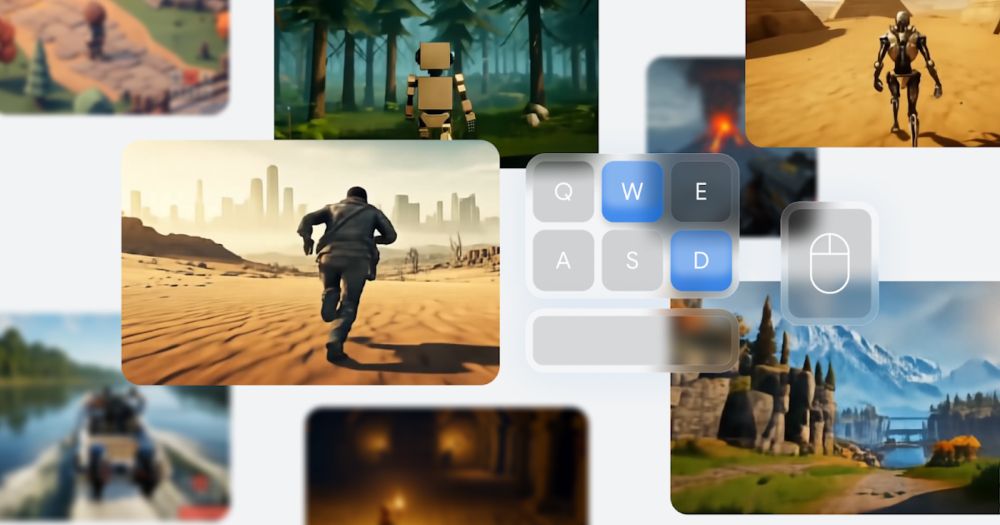
Genie 2: A large-scale foundation world model
Generating unlimited diverse training environments for future general agents
deepmind.google
December 4, 2024 at 5:01 PM
This can be a game changer for embodied #NeuroAI.
Or it *could* be, if it were open source.
Just imagine the resources it takes to develop an open version of this model. Now think about how much innovation could come from building on this, rather than just trying to recreate it (at best).
Or it *could* be, if it were open source.
Just imagine the resources it takes to develop an open version of this model. Now think about how much innovation could come from building on this, rather than just trying to recreate it (at best).
Reposted by Aidan Sirbu

I recently wrote a primer on UMAP for Nature Reviews Primers. If you are looking for an overview of the method, a getting started primer, or best practices it is a good place to start.
rdcu.be/d0YZT
rdcu.be/d0YZT
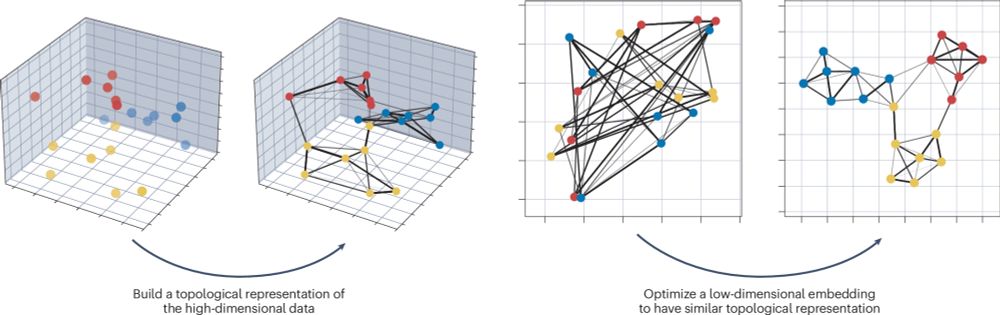
Uniform manifold approximation and projection
Nature Reviews Methods Primers - Uniform manifold approximation and projection is a dimensionality reduction technique used to visualize and understand high-dimensional data. In this Primer, Healy...
rdcu.be
November 22, 2024 at 12:02 AM
I recently wrote a primer on UMAP for Nature Reviews Primers. If you are looking for an overview of the method, a getting started primer, or best practices it is a good place to start.
rdcu.be/d0YZT
rdcu.be/d0YZT
Reposted by Aidan Sirbu

1/ I work in #NeuroAI, a growing field of research, which many people have only the haziest conception of...
As way of introduction to this research approach, I'll provide here a very short thread outlining the definition of the field I gave recently at our BRAIN NeuroAI workshop at the NIH.
🧠📈
As way of introduction to this research approach, I'll provide here a very short thread outlining the definition of the field I gave recently at our BRAIN NeuroAI workshop at the NIH.
🧠📈
November 21, 2024 at 4:20 PM
1/ I work in #NeuroAI, a growing field of research, which many people have only the haziest conception of...
As way of introduction to this research approach, I'll provide here a very short thread outlining the definition of the field I gave recently at our BRAIN NeuroAI workshop at the NIH.
🧠📈
As way of introduction to this research approach, I'll provide here a very short thread outlining the definition of the field I gave recently at our BRAIN NeuroAI workshop at the NIH.
🧠📈
Reposted by Aidan Sirbu

I'm making an unofficial starter pack with some of my colleagues at Mila. WIP for now but here's the link!
go.bsky.app/BHKxoss
go.bsky.app/BHKxoss
November 20, 2024 at 3:19 PM
I'm making an unofficial starter pack with some of my colleagues at Mila. WIP for now but here's the link!
go.bsky.app/BHKxoss
go.bsky.app/BHKxoss
Reposted by Aidan Sirbu

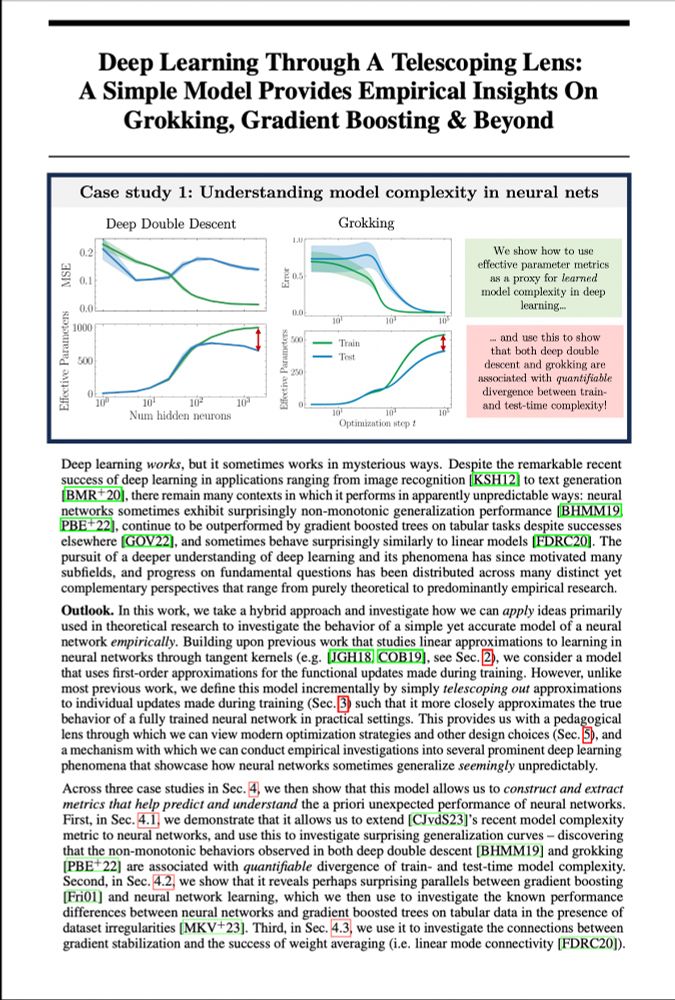
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
November 18, 2024 at 7:25 PM
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n