




Alicia Curth
@aliciacurth.bsky.social
Machine Learner by day, 🦮 Statistician at ❤️
In search of statistical intuition for modern ML & simple explanations for complex things👀
Interested in the mysteries of modern ML, causality & all of stats. Opinions my own.
https://aliciacurth.github.io
In search of statistical intuition for modern ML & simple explanations for complex things👀
Interested in the mysteries of modern ML, causality & all of stats. Opinions my own.
https://aliciacurth.github.io
Pinned
Alicia Curth
@aliciacurth.bsky.social
· Nov 18
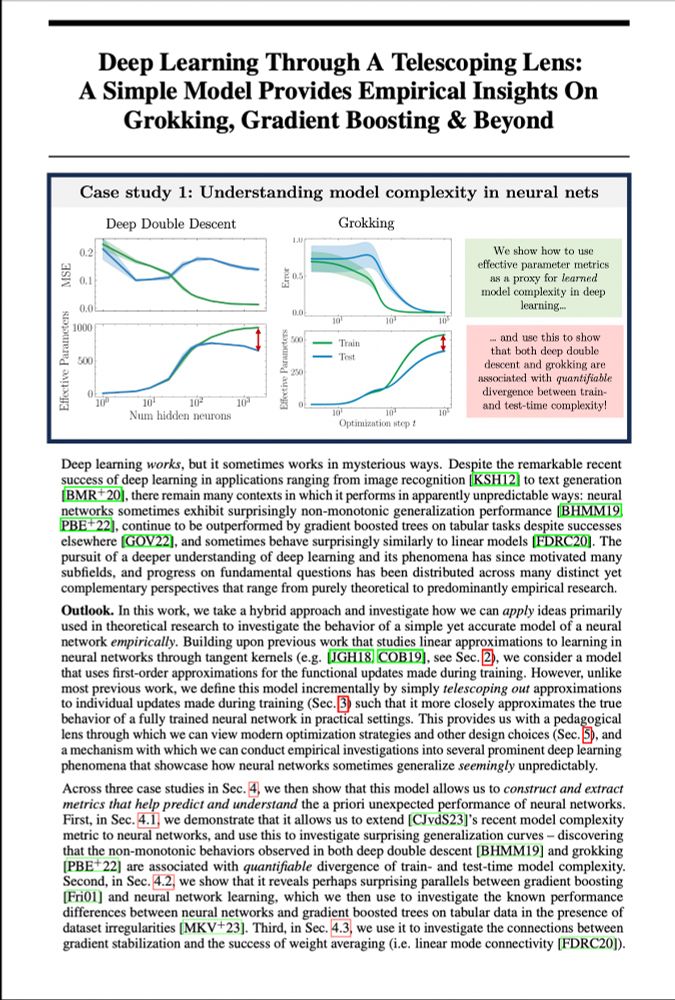
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
Reposted by Alicia Curth
Now might be the worst possible point in time to admit that I don’t own a physical copy of the book myself (yet!! I’m actually building up a textbook bookshelf for myself) BUT because Hastie, Tibshirani & Friedman are the GOATs that they are, they made the pdf free: hastie.su.domains/ElemStatLearn/
Elements of Statistical Learning: data mining, inference, and prediction. 2nd Edition.
hastie.su.domains
November 21, 2024 at 9:27 AM
Now might be the worst possible point in time to admit that I don’t own a physical copy of the book myself (yet!! I’m actually building up a textbook bookshelf for myself) BUT because Hastie, Tibshirani & Friedman are the GOATs that they are, they made the pdf free: hastie.su.domains/ElemStatLearn/
Reposted by Alicia Curth

Oh friends who are complaining about not enough Real Math^tm in their feed, I am here to help. Well, Alicia is here to help, at least!
Part 2: Why do boosted trees outperform deep learning on tabular data??
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n

November 21, 2024 at 4:42 AM
Oh friends who are complaining about not enough Real Math^tm in their feed, I am here to help. Well, Alicia is here to help, at least!
To emphasise just how accurately that reflects Alan’s approach to research (which I 100% subscribe to btw), I feel compelled to share that this is the actual slide I use whenever I present the U-turn paper in Alan’s absence 😂 (not a joke)

November 20, 2024 at 10:01 PM
To emphasise just how accurately that reflects Alan’s approach to research (which I 100% subscribe to btw), I feel compelled to share that this is the actual slide I use whenever I present the U-turn paper in Alan’s absence 😂 (not a joke)
btw this is why friends dont let friends skip the “boring classical ML” chapters in Elements of Statistical Learning‼️
(True story: the origin of this case study is that @alanjeffares.bsky.social[big EoSL nerd] looked at the neural net eq&said “kinda looks like GBTs in EoSL Ch10”&we went from there)
(True story: the origin of this case study is that @alanjeffares.bsky.social[big EoSL nerd] looked at the neural net eq&said “kinda looks like GBTs in EoSL Ch10”&we went from there)
but WAIT A MINUTE — isn’t that literally the same formula as the kernel representation of the telescoping model of a trained neural network I showed you before?? Just with a different kernel??
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n

November 20, 2024 at 8:47 PM
btw this is why friends dont let friends skip the “boring classical ML” chapters in Elements of Statistical Learning‼️
(True story: the origin of this case study is that @alanjeffares.bsky.social[big EoSL nerd] looked at the neural net eq&said “kinda looks like GBTs in EoSL Ch10”&we went from there)
(True story: the origin of this case study is that @alanjeffares.bsky.social[big EoSL nerd] looked at the neural net eq&said “kinda looks like GBTs in EoSL Ch10”&we went from there)
Part 2: Why do boosted trees outperform deep learning on tabular data??
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
November 20, 2024 at 5:02 PM
Part 2: Why do boosted trees outperform deep learning on tabular data??
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
Don’t need to know much about causal inference to know that in the counterfactual world where I didn’t join this platform I would have missed out on absolute GOLD content like this thread 🤩 ITE(join Bluesky)>>>0

This cafe must have a backdoor.
November 20, 2024 at 12:08 PM
Don’t need to know much about causal inference to know that in the counterfactual world where I didn’t join this platform I would have missed out on absolute GOLD content like this thread 🤩 ITE(join Bluesky)>>>0
Reposted by Alicia Curth

If it’s selection, we will find you.
If it’s causal, we will make you.
If it’s causal, we will make you.
The only logical conclusion from this thread is that statistics makes for happy people while machine learning makes you grumpy
Strong conclusion for n=3 but I’m willing to use a pretty strong prior here…
Strong conclusion for n=3 but I’m willing to use a pretty strong prior here…
November 19, 2024 at 3:35 PM
If it’s selection, we will find you.
If it’s causal, we will make you.
If it’s causal, we will make you.
aren’t smoothers just THE BEST??
understanding double descent, random forests, neural network complexity, and now causal inference — smoothers are just at your service when you need them
understanding double descent, random forests, neural network complexity, and now causal inference — smoothers are just at your service when you need them
How concretely?
Smoothers, we need smoothers!!! Outcome nuisance parameters have to be estimated using methods like (post-selection) OLS, (kernel) (ridge) or series regressions, tree-based methods, …
Check out @aliciacurth.bsky.social for nice references and cool insights using smoothers in ML.
Smoothers, we need smoothers!!! Outcome nuisance parameters have to be estimated using methods like (post-selection) OLS, (kernel) (ridge) or series regressions, tree-based methods, …
Check out @aliciacurth.bsky.social for nice references and cool insights using smoothers in ML.



November 19, 2024 at 1:21 PM
aren’t smoothers just THE BEST??
understanding double descent, random forests, neural network complexity, and now causal inference — smoothers are just at your service when you need them
understanding double descent, random forests, neural network complexity, and now causal inference — smoothers are just at your service when you need them
Reposted by Alicia Curth

New WP 🚨
1. Recipe to write estimators as weighted outcomes
2. Double ML and causal forests as weighting estimators
3. Plug&play classic covariate balancing checks
4. Explains why Causal ML fails to find an effect of 1 with noiseless outcome Y = 1 + D
5. More fun facts
arxiv.org/abs/2411.11559
1. Recipe to write estimators as weighted outcomes
2. Double ML and causal forests as weighting estimators
3. Plug&play classic covariate balancing checks
4. Explains why Causal ML fails to find an effect of 1 with noiseless outcome Y = 1 + D
5. More fun facts
arxiv.org/abs/2411.11559




November 19, 2024 at 12:11 PM
New WP 🚨
1. Recipe to write estimators as weighted outcomes
2. Double ML and causal forests as weighting estimators
3. Plug&play classic covariate balancing checks
4. Explains why Causal ML fails to find an effect of 1 with noiseless outcome Y = 1 + D
5. More fun facts
arxiv.org/abs/2411.11559
1. Recipe to write estimators as weighted outcomes
2. Double ML and causal forests as weighting estimators
3. Plug&play classic covariate balancing checks
4. Explains why Causal ML fails to find an effect of 1 with noiseless outcome Y = 1 + D
5. More fun facts
arxiv.org/abs/2411.11559
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
November 18, 2024 at 7:25 PM
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
I finally decided to double up with an account here hoping to find more scientific discourse :)
So: Hi, I’m Alicia, Machine Learning Researcher at MSR (since last month)! Prev I was a PhD student in Cambridge trying to make sense of the mysteries of modern Machine Learning (— to be continued!!) :)
So: Hi, I’m Alicia, Machine Learning Researcher at MSR (since last month)! Prev I was a PhD student in Cambridge trying to make sense of the mysteries of modern Machine Learning (— to be continued!!) :)
November 17, 2024 at 5:04 PM
I finally decided to double up with an account here hoping to find more scientific discourse :)
So: Hi, I’m Alicia, Machine Learning Researcher at MSR (since last month)! Prev I was a PhD student in Cambridge trying to make sense of the mysteries of modern Machine Learning (— to be continued!!) :)
So: Hi, I’m Alicia, Machine Learning Researcher at MSR (since last month)! Prev I was a PhD student in Cambridge trying to make sense of the mysteries of modern Machine Learning (— to be continued!!) :)