




Alicia Curth
@aliciacurth.bsky.social
Machine Learner by day, 🦮 Statistician at ❤️
In search of statistical intuition for modern ML & simple explanations for complex things👀
Interested in the mysteries of modern ML, causality & all of stats. Opinions my own.
https://aliciacurth.github.io
In search of statistical intuition for modern ML & simple explanations for complex things👀
Interested in the mysteries of modern ML, causality & all of stats. Opinions my own.
https://aliciacurth.github.io
To emphasise just how accurately that reflects Alan’s approach to research (which I 100% subscribe to btw), I feel compelled to share that this is the actual slide I use whenever I present the U-turn paper in Alan’s absence 😂 (not a joke)

November 20, 2024 at 10:01 PM
To emphasise just how accurately that reflects Alan’s approach to research (which I 100% subscribe to btw), I feel compelled to share that this is the actual slide I use whenever I present the U-turn paper in Alan’s absence 😂 (not a joke)
Importantly, this growth in performance gap is tracked by the behaviour of the models’ kernels:
while there is no difference in kernel weights for GBTs across different input irregularity levels, the neural net’s kernel weights for the most irregular ex grow more extreme! 12/n
while there is no difference in kernel weights for GBTs across different input irregularity levels, the neural net’s kernel weights for the most irregular ex grow more extreme! 12/n

November 20, 2024 at 5:02 PM
Importantly, this growth in performance gap is tracked by the behaviour of the models’ kernels:
while there is no difference in kernel weights for GBTs across different input irregularity levels, the neural net’s kernel weights for the most irregular ex grow more extreme! 12/n
while there is no difference in kernel weights for GBTs across different input irregularity levels, the neural net’s kernel weights for the most irregular ex grow more extreme! 12/n
We test this hypothesis by varying the proportion of irregular inputs in the testset for fixed trained models.
We find that GBTs outperform NNs already in the absence of irregular ex; this speaks to diff in baseline suitability
The performance gap then indeed grows as we increase irregularity!11/n
We find that GBTs outperform NNs already in the absence of irregular ex; this speaks to diff in baseline suitability
The performance gap then indeed grows as we increase irregularity!11/n

November 20, 2024 at 5:02 PM
We test this hypothesis by varying the proportion of irregular inputs in the testset for fixed trained models.
We find that GBTs outperform NNs already in the absence of irregular ex; this speaks to diff in baseline suitability
The performance gap then indeed grows as we increase irregularity!11/n
We find that GBTs outperform NNs already in the absence of irregular ex; this speaks to diff in baseline suitability
The performance gap then indeed grows as we increase irregularity!11/n
Trees issue preds that are proper averages: all kernel weights are between 0 & 1. That is: trees never “extrapolate” from the convex hull of training observations 💡
Neural net tangent kernels OTOH are generally unbounded and could take on very different vals for unseen test inputs!😰 9/n
Neural net tangent kernels OTOH are generally unbounded and could take on very different vals for unseen test inputs!😰 9/n

November 20, 2024 at 5:02 PM
Trees issue preds that are proper averages: all kernel weights are between 0 & 1. That is: trees never “extrapolate” from the convex hull of training observations 💡
Neural net tangent kernels OTOH are generally unbounded and could take on very different vals for unseen test inputs!😰 9/n
Neural net tangent kernels OTOH are generally unbounded and could take on very different vals for unseen test inputs!😰 9/n
One diff is obvious and purely architectural: either kernel might be able to better fit a particular underlying outcome generating process!
A second diff is a lot more subtle and relates to how regular (or: predictable) the two will likely behave on new data: … 8/n
A second diff is a lot more subtle and relates to how regular (or: predictable) the two will likely behave on new data: … 8/n

November 20, 2024 at 5:02 PM
One diff is obvious and purely architectural: either kernel might be able to better fit a particular underlying outcome generating process!
A second diff is a lot more subtle and relates to how regular (or: predictable) the two will likely behave on new data: … 8/n
A second diff is a lot more subtle and relates to how regular (or: predictable) the two will likely behave on new data: … 8/n
but WAIT A MINUTE — isn’t that literally the same formula as the kernel representation of the telescoping model of a trained neural network I showed you before?? Just with a different kernel??
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n

November 20, 2024 at 5:02 PM
but WAIT A MINUTE — isn’t that literally the same formula as the kernel representation of the telescoping model of a trained neural network I showed you before?? Just with a different kernel??
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n
Gradient boosted trees (aka OG gradient boosting) simply implement this process using trees!
From our previous work on random forests(arxiv.org/abs/2402.01502) we know we can interpret trees as adaptive kernel smoothers, so we can rewrite the GBT preds as weighted avgs over training loss grads!6/n
From our previous work on random forests(arxiv.org/abs/2402.01502) we know we can interpret trees as adaptive kernel smoothers, so we can rewrite the GBT preds as weighted avgs over training loss grads!6/n

November 20, 2024 at 5:02 PM
Gradient boosted trees (aka OG gradient boosting) simply implement this process using trees!
From our previous work on random forests(arxiv.org/abs/2402.01502) we know we can interpret trees as adaptive kernel smoothers, so we can rewrite the GBT preds as weighted avgs over training loss grads!6/n
From our previous work on random forests(arxiv.org/abs/2402.01502) we know we can interpret trees as adaptive kernel smoothers, so we can rewrite the GBT preds as weighted avgs over training loss grads!6/n
Quick refresher: what is gradient boosting?
Not to be confused with other forms of boosting (eg Adaboost), *Gradient* boosting fits a sequence of weak learners that execute steepest descent in function space directly by learning to predict the loss gradients of training examples! 5/n
Not to be confused with other forms of boosting (eg Adaboost), *Gradient* boosting fits a sequence of weak learners that execute steepest descent in function space directly by learning to predict the loss gradients of training examples! 5/n

November 20, 2024 at 5:02 PM
Quick refresher: what is gradient boosting?
Not to be confused with other forms of boosting (eg Adaboost), *Gradient* boosting fits a sequence of weak learners that execute steepest descent in function space directly by learning to predict the loss gradients of training examples! 5/n
Not to be confused with other forms of boosting (eg Adaboost), *Gradient* boosting fits a sequence of weak learners that execute steepest descent in function space directly by learning to predict the loss gradients of training examples! 5/n
And you know who continues to rule the tabular benchmarks? Gradient boosted trees (GBTs)!!(or their descendants)
While the severity of the perf gap over neural nets is disputed, arxiv.org/abs/2305.02997 still found as recently as last year that GBTs esp outperform when data is irregular! 3/n
While the severity of the perf gap over neural nets is disputed, arxiv.org/abs/2305.02997 still found as recently as last year that GBTs esp outperform when data is irregular! 3/n

November 20, 2024 at 5:02 PM
And you know who continues to rule the tabular benchmarks? Gradient boosted trees (GBTs)!!(or their descendants)
While the severity of the perf gap over neural nets is disputed, arxiv.org/abs/2305.02997 still found as recently as last year that GBTs esp outperform when data is irregular! 3/n
While the severity of the perf gap over neural nets is disputed, arxiv.org/abs/2305.02997 still found as recently as last year that GBTs esp outperform when data is irregular! 3/n
Part 2: Why do boosted trees outperform deep learning on tabular data??
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n

November 20, 2024 at 5:02 PM
Part 2: Why do boosted trees outperform deep learning on tabular data??
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
I think this is good evidence for the grumpiness I have to endure EVERY SINGLE PROJECT
November 18, 2024 at 10:49 PM
I think this is good evidence for the grumpiness I have to endure EVERY SINGLE PROJECT
Finally, we highlight that EPs also provide interesting insight into *the effect of good inductive biases on learned complexity*:
Grokking MNIST experiments use no good inits and no softmax. *With* both, models obv generalise faster — AND need much lower learned complexity! 16/n
Grokking MNIST experiments use no good inits and no softmax. *With* both, models obv generalise faster — AND need much lower learned complexity! 16/n

November 18, 2024 at 7:25 PM
Finally, we highlight that EPs also provide interesting insight into *the effect of good inductive biases on learned complexity*:
Grokking MNIST experiments use no good inits and no softmax. *With* both, models obv generalise faster — AND need much lower learned complexity! 16/n
Grokking MNIST experiments use no good inits and no softmax. *With* both, models obv generalise faster — AND need much lower learned complexity! 16/n
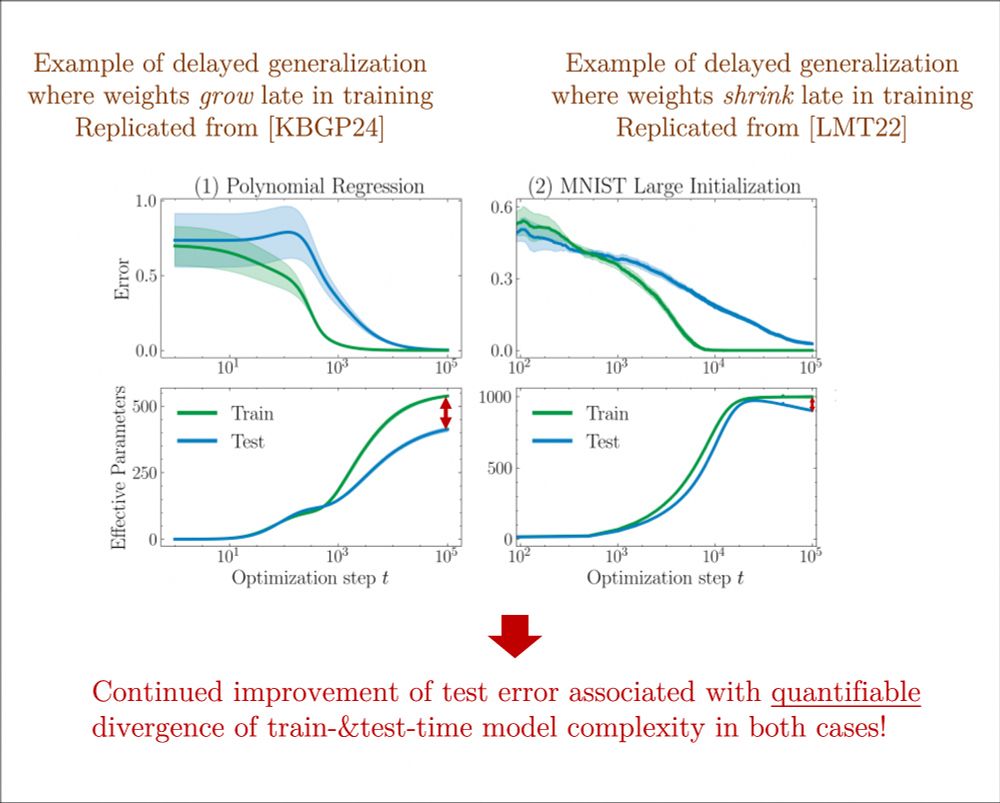
In arxiv.org/abs/2210.01117 grokking was shown to be associated with late weight decay, while arxiv.org/abs/2310.06110 show it can also occur w/ late weight growth 🤔
Using EPs, we reconcile the two & show that onset of performance is associated with divergence of train&test complexity in both! 15/n
Using EPs, we reconcile the two & show that onset of performance is associated with divergence of train&test complexity in both! 15/n
November 18, 2024 at 7:25 PM
In arxiv.org/abs/2210.01117 grokking was shown to be associated with late weight decay, while arxiv.org/abs/2310.06110 show it can also occur w/ late weight growth 🤔
Using EPs, we reconcile the two & show that onset of performance is associated with divergence of train&test complexity in both! 15/n
Using EPs, we reconcile the two & show that onset of performance is associated with divergence of train&test complexity in both! 15/n
We use this to track train- and test-time EPs in deep double descent experiments (model size on x axis) and find that the second descent is associated with a *decrease* in test-time *effective* complexity — just like we found for non-neural models in arxiv.org/abs/2310.18988 last year!12/n

November 18, 2024 at 7:25 PM
We use this to track train- and test-time EPs in deep double descent experiments (model size on x axis) and find that the second descent is associated with a *decrease* in test-time *effective* complexity — just like we found for non-neural models in arxiv.org/abs/2310.18988 last year!12/n
Fortunately the telescoping model makes precisely this possible! For the special case of squared loss, we can now explicitly write out the functional updates and express trained neural nets as approximate smoothers with *learned* weights
Now we can compute effective parameters for trained nets! 11/n
Now we can compute effective parameters for trained nets! 11/n

November 18, 2024 at 7:25 PM
Fortunately the telescoping model makes precisely this possible! For the special case of squared loss, we can now explicitly write out the functional updates and express trained neural nets as approximate smoothers with *learned* weights
Now we can compute effective parameters for trained nets! 11/n
Now we can compute effective parameters for trained nets! 11/n
The effective parameter (EP) measure from arxiv.org/abs/2310.18988 is thus a better candidate bc it applies to a specific trained model, AND it can distinguish train from testtime complexity!
BUT it requires to write predictions as a linear combination of the training labels... 🤔 10/n
BUT it requires to write predictions as a linear combination of the training labels... 🤔 10/n

November 18, 2024 at 7:25 PM
The effective parameter (EP) measure from arxiv.org/abs/2310.18988 is thus a better candidate bc it applies to a specific trained model, AND it can distinguish train from testtime complexity!
BUT it requires to write predictions as a linear combination of the training labels... 🤔 10/n
BUT it requires to write predictions as a linear combination of the training labels... 🤔 10/n
Recall: Phenomena like double descent and grokking highlight that classical complexity metrics which capture *capacity for overfitting* can't explain realised performance in deep learning...
Intuitively it's not about what models *could* learn, it's all about what they *have learned*! 9/n
Intuitively it's not about what models *could* learn, it's all about what they *have learned*! 9/n

November 18, 2024 at 7:25 PM
Recall: Phenomena like double descent and grokking highlight that classical complexity metrics which capture *capacity for overfitting* can't explain realised performance in deep learning...
Intuitively it's not about what models *could* learn, it's all about what they *have learned*! 9/n
Intuitively it's not about what models *could* learn, it's all about what they *have learned*! 9/n
Now we can finally ask: does this simple approx of a trained neural network help us understand some of deep learning’s notoriously weird behaviors? Plus can it help us better understand design choices?
Today I’ll tell you about case study 1: understanding *learned* model complexity! 8/n
Today I’ll tell you about case study 1: understanding *learned* model complexity! 8/n

November 18, 2024 at 7:25 PM
Now we can finally ask: does this simple approx of a trained neural network help us understand some of deep learning’s notoriously weird behaviors? Plus can it help us better understand design choices?
Today I’ll tell you about case study 1: understanding *learned* model complexity! 8/n
Today I’ll tell you about case study 1: understanding *learned* model complexity! 8/n
Before I (finally😅) tell you why this idea is really useful to understand deep learning phenomena, let’s quickly verify that this approx is better than the linear one:
Essentially by design, it matches the full networks’ predictions more closely -- AND performs categorically more similarly! 7/n
Essentially by design, it matches the full networks’ predictions more closely -- AND performs categorically more similarly! 7/n

November 18, 2024 at 7:25 PM
Before I (finally😅) tell you why this idea is really useful to understand deep learning phenomena, let’s quickly verify that this approx is better than the linear one:
Essentially by design, it matches the full networks’ predictions more closely -- AND performs categorically more similarly! 7/n
Essentially by design, it matches the full networks’ predictions more closely -- AND performs categorically more similarly! 7/n
We exploit that you can express preds of a trained network as a telescoping sum over all training steps💡
For a single step changes are small,so we can better linearly approximate individual steps sequentially(instead of the whole trajectory at once)
➡️ We refer to this as ✨telescoping approx✨!6/n
For a single step changes are small,so we can better linearly approximate individual steps sequentially(instead of the whole trajectory at once)
➡️ We refer to this as ✨telescoping approx✨!6/n

November 18, 2024 at 7:25 PM
We exploit that you can express preds of a trained network as a telescoping sum over all training steps💡
For a single step changes are small,so we can better linearly approximate individual steps sequentially(instead of the whole trajectory at once)
➡️ We refer to this as ✨telescoping approx✨!6/n
For a single step changes are small,so we can better linearly approximate individual steps sequentially(instead of the whole trajectory at once)
➡️ We refer to this as ✨telescoping approx✨!6/n
Unfortunately for theory, model grads don’t usually stay constant in practice 😓
We thus explore a subtly different idea. We ask: “if you give us access to the optimisation trajectory of your trained net, what can we tell you about what it *has* learned in training?” 5/n
We thus explore a subtly different idea. We ask: “if you give us access to the optimisation trajectory of your trained net, what can we tell you about what it *has* learned in training?” 5/n

November 18, 2024 at 7:25 PM
Unfortunately for theory, model grads don’t usually stay constant in practice 😓
We thus explore a subtly different idea. We ask: “if you give us access to the optimisation trajectory of your trained net, what can we tell you about what it *has* learned in training?” 5/n
We thus explore a subtly different idea. We ask: “if you give us access to the optimisation trajectory of your trained net, what can we tell you about what it *has* learned in training?” 5/n
.. that model grads (wrt the params) stay ≈constant during training — then linearity holds! This lit essentially uses this to do theory of the form:“if you promise your grads stay constant, I’ll tell you what your net will learn without you having to train!”
V neat! BUT… 4/n
V neat! BUT… 4/n

November 18, 2024 at 7:25 PM
.. that model grads (wrt the params) stay ≈constant during training — then linearity holds! This lit essentially uses this to do theory of the form:“if you promise your grads stay constant, I’ll tell you what your net will learn without you having to train!”
V neat! BUT… 4/n
V neat! BUT… 4/n
One way of getting back to linearity is to say: What if a trained neural network was well-approximated by its first order Taylor expansion (linear approx) around the init?
That’s essentially the idea behind the neural tangent kernel/lazy learning literature!! They assume.. 3/n
That’s essentially the idea behind the neural tangent kernel/lazy learning literature!! They assume.. 3/n

November 18, 2024 at 7:25 PM
One way of getting back to linearity is to say: What if a trained neural network was well-approximated by its first order Taylor expansion (linear approx) around the init?
That’s essentially the idea behind the neural tangent kernel/lazy learning literature!! They assume.. 3/n
That’s essentially the idea behind the neural tangent kernel/lazy learning literature!! They assume.. 3/n
The problem with neural nets is that they are black boxes in many ways: its opaque how the functions they learn depend on training data, optimizers & even their model params + we have no clue what theyll converge to.
Ppl like linear models bc they have none of these problems 2/n
Ppl like linear models bc they have none of these problems 2/n

November 18, 2024 at 7:25 PM
The problem with neural nets is that they are black boxes in many ways: its opaque how the functions they learn depend on training data, optimizers & even their model params + we have no clue what theyll converge to.
Ppl like linear models bc they have none of these problems 2/n
Ppl like linear models bc they have none of these problems 2/n
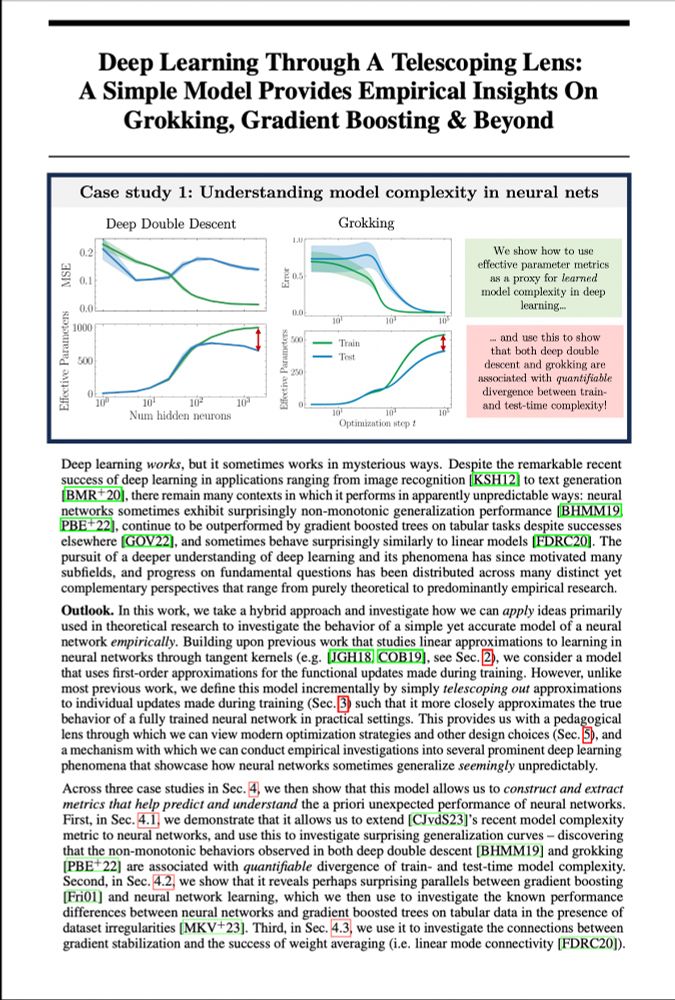
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
November 18, 2024 at 7:25 PM
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n