




Philip Bontrager
@pbontrager.bsky.social
AI researcher & engineer @Meta working on @PyTorch torchtune in NYC; interests in generative models, RL, and evolutionary strategies
💻 https://github.com/pbontrager 📝 https://tinyurl.com/philips-papers
💻 https://github.com/pbontrager 📝 https://tinyurl.com/philips-papers
What goes into saving checkpoints is not something that many people think about, but as models get bigger this becomes a challenge. The biggest open models now have checkpoints over 700gb that can take tens of minutes every time you want to consolidate into a checkpoint.
pytorch.org/blog/hugging...
pytorch.org/blog/hugging...
June 8, 2025 at 12:07 AM
What goes into saving checkpoints is not something that many people think about, but as models get bigger this becomes a challenge. The biggest open models now have checkpoints over 700gb that can take tens of minutes every time you want to consolidate into a checkpoint.
pytorch.org/blog/hugging...
pytorch.org/blog/hugging...
Reposted by Philip Bontrager

We've built a simulated driving agent that we trained on 1.6 billion km of driving with no human data.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
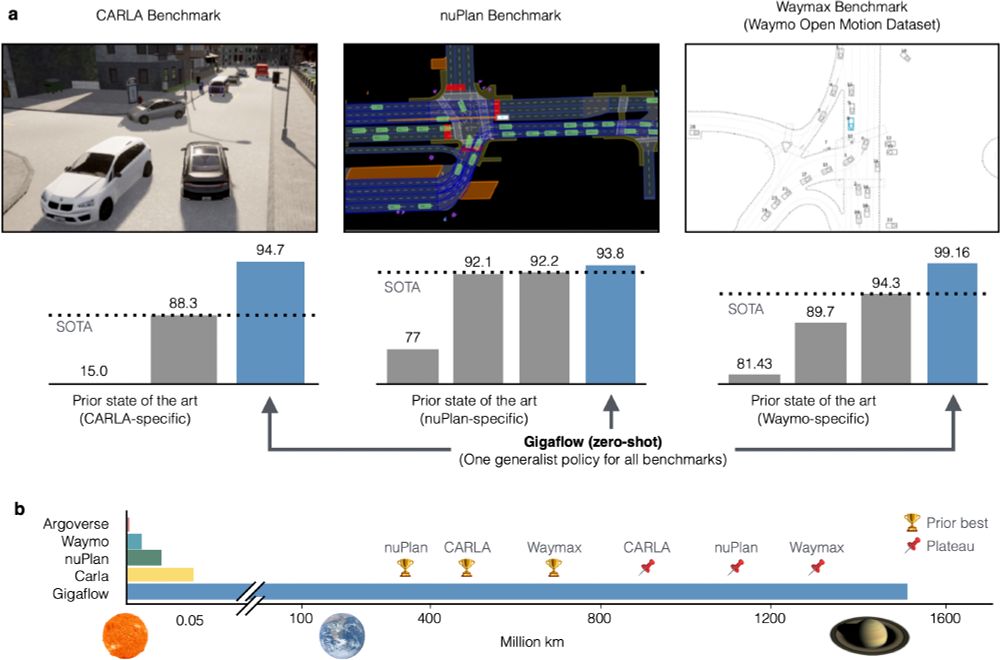
February 6, 2025 at 6:34 PM
We've built a simulated driving agent that we trained on 1.6 billion km of driving with no human data.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
It is SOTA on every planning benchmark we tried.
In self-play, it goes 20 years between collisions.
In the Alice In Wonderland (github.com/LAION-AI/AIW) reasoning and generalization benchmark, DeepSeek R1 appears to perform much more like o1 mini than o1 -preview. (Plot from laion-ai)

January 25, 2025 at 5:25 PM
In the Alice In Wonderland (github.com/LAION-AI/AIW) reasoning and generalization benchmark, DeepSeek R1 appears to perform much more like o1 mini than o1 -preview. (Plot from laion-ai)
Can we just study LLM activations/behavior because it’s interesting and it can tell us things about language and AI without imbuing artificial importance or meaning on top of it?
January 14, 2025 at 2:05 PM
Can we just study LLM activations/behavior because it’s interesting and it can tell us things about language and AI without imbuing artificial importance or meaning on top of it?
Plagiarize other people’s research


January 1, 2025 at 12:54 AM
Plagiarize other people’s research
Reposted by Philip Bontrager

this seems like a decent LLM test. 3 sequential game states of Qwirkle.
Sonnet 3.5 gets the first play but not the second
o1 is very bad at this. first play it takes 59 seconds and it’s answer isn’t even a play that’s on the board. same with second play, but only 36 seconds
Sonnet 3.5 gets the first play but not the second
o1 is very bad at this. first play it takes 59 seconds and it’s answer isn’t even a play that’s on the board. same with second play, but only 36 seconds



December 23, 2024 at 1:31 AM
this seems like a decent LLM test. 3 sequential game states of Qwirkle.
Sonnet 3.5 gets the first play but not the second
o1 is very bad at this. first play it takes 59 seconds and it’s answer isn’t even a play that’s on the board. same with second play, but only 36 seconds
Sonnet 3.5 gets the first play but not the second
o1 is very bad at this. first play it takes 59 seconds and it’s answer isn’t even a play that’s on the board. same with second play, but only 36 seconds
Contrary to what I see in a lot of online discussions, AI benchmarks are not meant to show how capable an AI system is, but instead they show what they can’t do.
December 24, 2024 at 5:29 PM
Contrary to what I see in a lot of online discussions, AI benchmarks are not meant to show how capable an AI system is, but instead they show what they can’t do.
If you have a lot of experience training and fine-tuning ML models and want to help bring that expertise to the community, we’re looking to hire a new member for the torchtune team!
www.metacareers.com/jobs/5121890...
www.metacareers.com/jobs/5121890...

Software Engineer - PyTorch Domains
Meta's mission is to build the future of human connection and the technology that makes it possible.
www.metacareers.com
December 22, 2024 at 9:20 PM
If you have a lot of experience training and fine-tuning ML models and want to help bring that expertise to the community, we’re looking to hire a new member for the torchtune team!
www.metacareers.com/jobs/5121890...
www.metacareers.com/jobs/5121890...
New release of torchtune right before Christmas! We have new recipes, better integration with vLLM and HF, support for Gemma2, and more. We've also now added support for Kaggle notebooks!
www.kaggle.com/code/felipem...
www.kaggle.com/code/felipem...
torchtune in kaggle
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
December 20, 2024 at 9:54 PM
New release of torchtune right before Christmas! We have new recipes, better integration with vLLM and HF, support for Gemma2, and more. We've also now added support for Kaggle notebooks!
www.kaggle.com/code/felipem...
www.kaggle.com/code/felipem...
New encoder using all the latest training tricks! One thing I’m wondering is how this compares to something like SmolLM (similar size). I know encoder models should provide better embeddings but I wonder what this looks like in practice.

I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
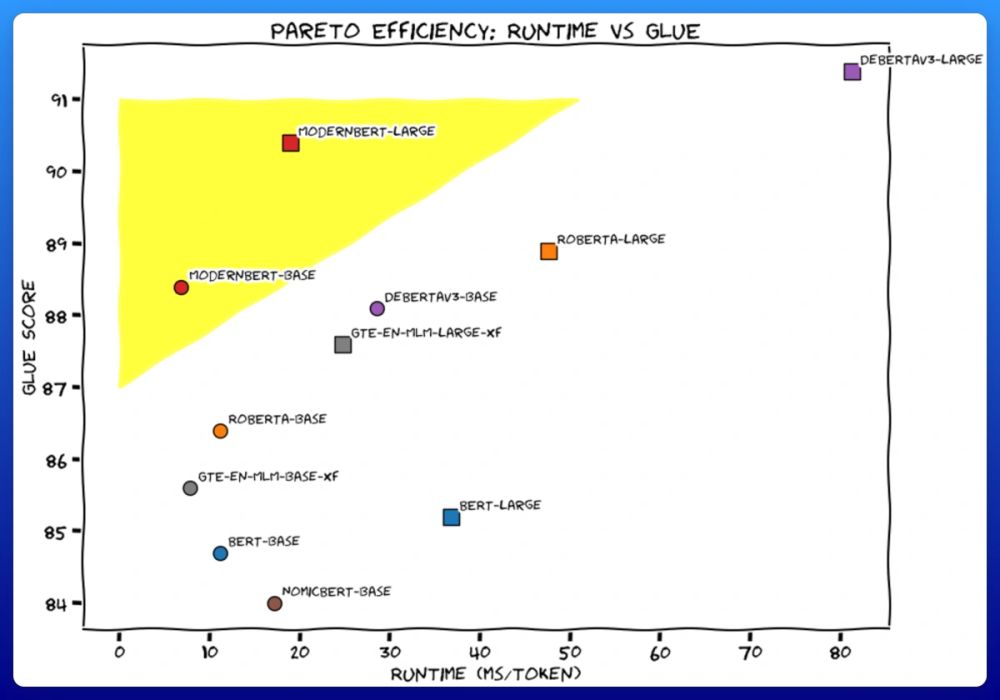
December 19, 2024 at 8:05 PM
New encoder using all the latest training tricks! One thing I’m wondering is how this compares to something like SmolLM (similar size). I know encoder models should provide better embeddings but I wonder what this looks like in practice.
Reposted by Philip Bontrager

Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!

December 16, 2024 at 9:42 PM
Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
Reposted by Philip Bontrager

1/ Okay, one thing that has been revealed to me from the replies to this is that many people don't know (or refuse to recognize) the following fact:
The unts in ANN are actually not a terrible approximation of how real neurons work!
A tiny 🧵.
🧠📈 #NeuroAI #MLSky
The unts in ANN are actually not a terrible approximation of how real neurons work!
A tiny 🧵.
🧠📈 #NeuroAI #MLSky
Why does anyone have any issue with this?
I've seen people suggesting it's problematic, that neuroscientists won't like it, and so on.
But, I literally don't see why this is problematic...
I've seen people suggesting it's problematic, that neuroscientists won't like it, and so on.
But, I literally don't see why this is problematic...

This would be funny if it weren't sad...
Coming from the "giants" of AI.
Or maybe this was posted out of context? Please clarify.
I can't process this...
Coming from the "giants" of AI.
Or maybe this was posted out of context? Please clarify.
I can't process this...
December 16, 2024 at 8:03 PM
Excited to see diffusion language models getting scaled up to sizes where we can start to compare them to auto-regressive approaches (though this model is a bit of a hybrid)

Proud to share our work on Large Concept Models (LCMs)! This is a new direction in language modeling that moves beyond traditional token-level LLMs.
Paper: ai.meta.com/research/pub...
Code: github.com/facebookrese...
Paper: ai.meta.com/research/pub...
Code: github.com/facebookrese...

GitHub - facebookresearch/large_concept_model: Large Concept Models: Language modeling in a sentence representation space
Large Concept Models: Language modeling in a sentence representation space - facebookresearch/large_concept_model
github.com
December 15, 2024 at 10:10 PM
Excited to see diffusion language models getting scaled up to sizes where we can start to compare them to auto-regressive approaches (though this model is a bit of a hybrid)
I’m at the age where I have to go on LinkedIn if I want to see what my old high school friends are up too.
December 14, 2024 at 11:17 PM
I’m at the age where I have to go on LinkedIn if I want to see what my old high school friends are up too.
Reposted by Philip Bontrager

"pre training as we know it will end (because we will run out of data)" is, in other words, "learning to complete partial observations is not sufficient to get to intelligence". i think this was kinda obvious to many, but maybe noteworthy that a true scale-believer said it.
December 14, 2024 at 12:32 PM
"pre training as we know it will end (because we will run out of data)" is, in other words, "learning to complete partial observations is not sufficient to get to intelligence". i think this was kinda obvious to many, but maybe noteworthy that a true scale-believer said it.
The way you can tell if an image is AI generated or not is by looking at the hands. If the hands look weird they’re probably human drawn.

December 14, 2024 at 12:13 AM
The way you can tell if an image is AI generated or not is by looking at the hands. If the hands look weird they’re probably human drawn.
As a counterpoint, when I was applying for grad schools, a professor where I was applying told me that ML was just linear algebra and my PhD would just be that. Almost made me reconsider

"Attention" in attention layers. How about sum-product layers? Key-query products? ... Neural attention has little to do with human attention. And the intuitive baggage of the name probably constrains our thinking about how transformers work. (1/2)

If you could fix one☝🏻 piece of terminology in your field, what would it be?
I’ll go first👇🏻(replying to myself like it’s normal)
I’ll go first👇🏻(replying to myself like it’s normal)
December 11, 2024 at 1:35 PM
As a counterpoint, when I was applying for grad schools, a professor where I was applying told me that ML was just linear algebra and my PhD would just be that. Almost made me reconsider
Reposted by Philip Bontrager

December 9, 2024 at 7:52 AM
Reposted by Philip Bontrager

A very nice blog from Przemek Pietrzkiewicz, offering thoughts on our recent result in AI for competitive programming 🏆
Przemek co-led the Hash Code contest, which we used as the main test-bed to evaluate our approach 🚀
Worth a read if you want to understand implications of our work! Link below ⬇️
Przemek co-led the Hash Code contest, which we used as the main test-bed to evaluate our approach 🚀
Worth a read if you want to understand implications of our work! Link below ⬇️

December 8, 2024 at 12:34 PM
A very nice blog from Przemek Pietrzkiewicz, offering thoughts on our recent result in AI for competitive programming 🏆
Przemek co-led the Hash Code contest, which we used as the main test-bed to evaluate our approach 🚀
Worth a read if you want to understand implications of our work! Link below ⬇️
Przemek co-led the Hash Code contest, which we used as the main test-bed to evaluate our approach 🚀
Worth a read if you want to understand implications of our work! Link below ⬇️
If the internet gets filled up with AI generated text, presumably it’s the good text that humans decided to keep from the models. Does that mean over time all model training becomes RLHF? 🤔
December 7, 2024 at 11:00 PM
If the internet gets filled up with AI generated text, presumably it’s the good text that humans decided to keep from the models. Does that mean over time all model training becomes RLHF? 🤔
Llama 3.3 70B is out getting very close benchmarks results to the 405B model. If you want to fine-tune it on a bit more than 48GB of VRAM, checkout this torchtune config
gist.github.com/pbontrager/b...
gist.github.com/pbontrager/b...

Ultra Low Memory Llama 3.3 Finetuning Config
Ultra Low Memory Llama 3.3 Finetuning Config. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
December 6, 2024 at 8:46 PM
Llama 3.3 70B is out getting very close benchmarks results to the 405B model. If you want to fine-tune it on a bit more than 48GB of VRAM, checkout this torchtune config
gist.github.com/pbontrager/b...
gist.github.com/pbontrager/b...
Really cool new work out of Deep Mind for video game world generation using latent diffusion! Soon you'll be able to speed run a game just by tricking a model to morph you from one location to another.
deepmind.google/discover/blo...
deepmind.google/discover/blo...
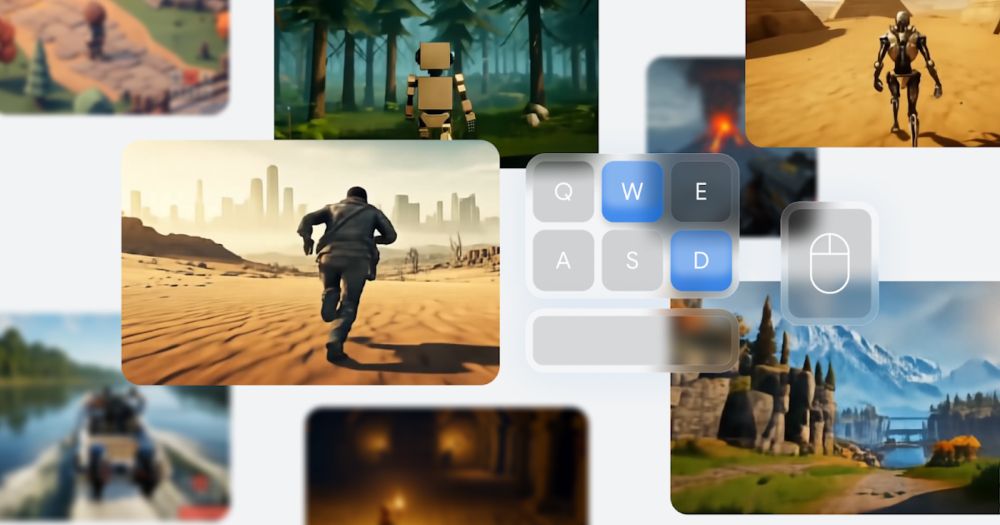
Genie 2: A large-scale foundation world model
Generating unlimited diverse training environments for future general agents
deepmind.google
December 4, 2024 at 4:31 PM
Really cool new work out of Deep Mind for video game world generation using latent diffusion! Soon you'll be able to speed run a game just by tricking a model to morph you from one location to another.
deepmind.google/discover/blo...
deepmind.google/discover/blo...
Reposted by Philip Bontrager

How to drive your research forward?
“I tested the idea we discussed last time. Here are some results. It does not work. (… awkward silence)”
Such conversations happen so many times when meetings with students. How do we move forward?
You need …
“I tested the idea we discussed last time. Here are some results. It does not work. (… awkward silence)”
Such conversations happen so many times when meetings with students. How do we move forward?
You need …
December 1, 2024 at 10:09 PM
How to drive your research forward?
“I tested the idea we discussed last time. Here are some results. It does not work. (… awkward silence)”
Such conversations happen so many times when meetings with students. How do we move forward?
You need …
“I tested the idea we discussed last time. Here are some results. It does not work. (… awkward silence)”
Such conversations happen so many times when meetings with students. How do we move forward?
You need …
When building torchtune we’ve had lots of discussions on where to put code. All in the top level recipe? In utilities? Build a trainer?
The goal is always to make experimentation and hacking with the recipes easy. I’m curious what your opinions are on using trainers vs recipes style scripts.
The goal is always to make experimentation and hacking with the recipes easy. I’m curious what your opinions are on using trainers vs recipes style scripts.
November 27, 2024 at 7:53 PM
When building torchtune we’ve had lots of discussions on where to put code. All in the top level recipe? In utilities? Build a trainer?
The goal is always to make experimentation and hacking with the recipes easy. I’m curious what your opinions are on using trainers vs recipes style scripts.
The goal is always to make experimentation and hacking with the recipes easy. I’m curious what your opinions are on using trainers vs recipes style scripts.