



Arna Ghosh
@arnaghosh.bsky.social
Research Scientist at Google Research, working on Bio-inspired AI • PhD at Mila & McGill University, Vanier scholar • Ex-RealityLabs, Meta AI • Comedy+Cricket enthusiast
Reposted by Arna Ghosh

New paper out at PNAS: www.pnas.org/doi/10.1073/...
Revisiting the high-dimensional geometry of population responses in the visual cortex with @jpillowtime.bsky.social. The review took forever because a reviewer was doubtful our new estimator can infer eigenvalues beyond the rank of the data! (1/6)
Revisiting the high-dimensional geometry of population responses in the visual cortex with @jpillowtime.bsky.social. The review took forever because a reviewer was doubtful our new estimator can infer eigenvalues beyond the rank of the data! (1/6)
PNAS
Proceedings of the National Academy of Sciences (PNAS), a peer reviewed journal of the National Academy of Sciences (NAS) - an authoritative source of high-impact, original research that broadly spans...
www.pnas.org
January 27, 2026 at 4:34 PM
New paper out at PNAS: www.pnas.org/doi/10.1073/...
Revisiting the high-dimensional geometry of population responses in the visual cortex with @jpillowtime.bsky.social. The review took forever because a reviewer was doubtful our new estimator can infer eigenvalues beyond the rank of the data! (1/6)
Revisiting the high-dimensional geometry of population responses in the visual cortex with @jpillowtime.bsky.social. The review took forever because a reviewer was doubtful our new estimator can infer eigenvalues beyond the rank of the data! (1/6)
Reposted by Arna Ghosh

Are you thinking about doing neuroscience outreach but want to make it more exciting or hands on?
Check out RetINaBox! (A collab led by the Trenholm lab)
We tried to bring the experience of experimental neuroscience to a classroom setting:
www.eneuro.org/content/13/1...
#neuroscience 🧪
Check out RetINaBox! (A collab led by the Trenholm lab)
We tried to bring the experience of experimental neuroscience to a classroom setting:
www.eneuro.org/content/13/1...
#neuroscience 🧪

RetINaBox: A Hands-On Learning Tool for Experimental Neuroscience
An exciting aspect of neuroscience is developing and testing hypotheses via experimentation. However, due to logistical and financial hurdles, the experiment and discovery component of neuroscience is...
www.eneuro.org
January 13, 2026 at 2:56 PM
Are you thinking about doing neuroscience outreach but want to make it more exciting or hands on?
Check out RetINaBox! (A collab led by the Trenholm lab)
We tried to bring the experience of experimental neuroscience to a classroom setting:
www.eneuro.org/content/13/1...
#neuroscience 🧪
Check out RetINaBox! (A collab led by the Trenholm lab)
We tried to bring the experience of experimental neuroscience to a classroom setting:
www.eneuro.org/content/13/1...
#neuroscience 🧪
Whoaaa!! This is a fantastic effort, and an amazing resource.
Huge congratulations to the authors! 🎉
Huge congratulations to the authors! 🎉

Need more fMRI data (beyond the amazing NSD)? Introducing MOSAIC! Incredible effort led expertly by Ben Lahner, with help from grad student Mayukh Deb. Work in collaboration with the amazing Aude Oliva! @neurosky.bsky.social. More below..
December 5, 2025 at 4:16 PM
Whoaaa!! This is a fantastic effort, and an amazing resource.
Huge congratulations to the authors! 🎉
Huge congratulations to the authors! 🎉
Reposted by Arna Ghosh

Last day of poster sessions and presentations at
@neuripsconf.bsky.social. Full schedule featuring Mila-affiliated researchers presenting their work at #NeurIPS2025 here mila.quebec/en/news/foll...
@neuripsconf.bsky.social. Full schedule featuring Mila-affiliated researchers presenting their work at #NeurIPS2025 here mila.quebec/en/news/foll...

December 5, 2025 at 4:07 PM
Last day of poster sessions and presentations at
@neuripsconf.bsky.social. Full schedule featuring Mila-affiliated researchers presenting their work at #NeurIPS2025 here mila.quebec/en/news/foll...
@neuripsconf.bsky.social. Full schedule featuring Mila-affiliated researchers presenting their work at #NeurIPS2025 here mila.quebec/en/news/foll...
In San Diego attending #NeurIPS2025?
Come to our poster to talk more about representation geometry in LLMs. 😃
🗓️ Friday 4:30-7:30 pm session
📍 Exhibit Hall C, D, E
🏁 Poster # 2502
Come to our poster to talk more about representation geometry in LLMs. 😃
🗓️ Friday 4:30-7:30 pm session
📍 Exhibit Hall C, D, E
🏁 Poster # 2502
LLMs are trained to compress data by mapping sequences to high-dim representations!
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM

December 5, 2025 at 2:39 PM
In San Diego attending #NeurIPS2025?
Come to our poster to talk more about representation geometry in LLMs. 😃
🗓️ Friday 4:30-7:30 pm session
📍 Exhibit Hall C, D, E
🏁 Poster # 2502
Come to our poster to talk more about representation geometry in LLMs. 😃
🗓️ Friday 4:30-7:30 pm session
📍 Exhibit Hall C, D, E
🏁 Poster # 2502
Reposted by Arna Ghosh

(1/n) We are excited to share our new paper in Nature Communications, by Hagar Lavian (@hlavian.bsky.social) and team, revealing how the zebrafish brain integrates visual navigation signals! www.nature.com/articles/s41...

Visual motion and landmark position align with heading direction in the zebrafish interpeduncular nucleus - Nature Communications
How are various visual signals integrated in the vertebrate brain for navigation? Here authors show that different spatial signals are topographically organized and align to one another in the zebrafi...
www.nature.com
November 24, 2025 at 4:17 PM
(1/n) We are excited to share our new paper in Nature Communications, by Hagar Lavian (@hlavian.bsky.social) and team, revealing how the zebrafish brain integrates visual navigation signals! www.nature.com/articles/s41...
Reposted by Arna Ghosh
1/ Why does RL struggle with social dilemmas? How can we ensure that AI learns to cooperate rather than compete?
Introducing our new framework: MUPI (Embedded Universal Predictive Intelligence) which provides a theoretical basis for new cooperative solutions in RL.
Preprint🧵👇
(Paper link below.)
Introducing our new framework: MUPI (Embedded Universal Predictive Intelligence) which provides a theoretical basis for new cooperative solutions in RL.
Preprint🧵👇
(Paper link below.)

December 3, 2025 at 7:19 PM
1/ Why does RL struggle with social dilemmas? How can we ensure that AI learns to cooperate rather than compete?
Introducing our new framework: MUPI (Embedded Universal Predictive Intelligence) which provides a theoretical basis for new cooperative solutions in RL.
Preprint🧵👇
(Paper link below.)
Introducing our new framework: MUPI (Embedded Universal Predictive Intelligence) which provides a theoretical basis for new cooperative solutions in RL.
Preprint🧵👇
(Paper link below.)
Population coding 🙌

“I will die on the hill that population coding is the relevant level of encoding information in the brain.” In the latest “This paper changed my life,” Nancy Padilla-Coreano discusses a paper on mixed selectivity neurons.
#neuroskyence
www.thetransmitter.org/this-paper-c...
#neuroskyence
www.thetransmitter.org/this-paper-c...

This paper changed my life: Nancy Padilla-Coreano on learning the value of population coding
The 2013 Nature paper by Mattia Rigotti and his colleagues revealed how mixed selectivity neurons—cells that are not selectively tuned to a stimulus—play a key role in cognition.
www.thetransmitter.org
December 2, 2025 at 6:07 AM
Population coding 🙌
Reposted by Arna Ghosh

How I contributed to rejecting one of my favorite papers of all times, Yes, I teach it to students daily, and refer to it in lots of papers. Sorry. open.substack.com/pub/kording/...

How I contributed to rejecting one of my favorite papers of all time
I believe we should talk about the mistakes we make.
open.substack.com
December 2, 2025 at 1:27 AM
How I contributed to rejecting one of my favorite papers of all times, Yes, I teach it to students daily, and refer to it in lots of papers. Sorry. open.substack.com/pub/kording/...
This is an excellent blueprint on a very fascinating use of AI scientist! And the results and super cool and interesting! 🤩
I have been asked this when talking about our work on using powerlaws to study representation quality in deep neural networks, glad to have a more concrete answer now! 😃
I have been asked this when talking about our work on using powerlaws to study representation quality in deep neural networks, glad to have a more concrete answer now! 😃

1. New preprint resolving a conundrum in systems neuroscience with an AI scientist, and humans Reilly Tilbury, Dabin Kwon, @haydari.bsky.social, @jacobmratliff.bsky.social, @bio-emergent.bsky.social, @carandinilab.net, @kevinjmiller.bsky.social, @neurokim.bsky.social
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...

Characterizing neuronal population geometry with AI equation discovery
The visual cortex contains millions of neurons, whose combined activity forms a population code representing visual stimuli. There is, however, a discrepancy between our understanding of this code at ...
www.biorxiv.org
November 16, 2025 at 10:29 PM
This is an excellent blueprint on a very fascinating use of AI scientist! And the results and super cool and interesting! 🤩
I have been asked this when talking about our work on using powerlaws to study representation quality in deep neural networks, glad to have a more concrete answer now! 😃
I have been asked this when talking about our work on using powerlaws to study representation quality in deep neural networks, glad to have a more concrete answer now! 😃
Reposted by Arna Ghosh

Conrad Hal Waddington was born OTD in 1905.
His “epigenetic landscape” is a diagrammatic representation of the constraints influencing embryonic development.
On his 50th birthday, his colleagues gave him a pinball machine on the model of the epigenetic landscape.
🧪 🦫🦋 🌱🐋 #HistSTM #philsci #evobio
His “epigenetic landscape” is a diagrammatic representation of the constraints influencing embryonic development.
On his 50th birthday, his colleagues gave him a pinball machine on the model of the epigenetic landscape.
🧪 🦫🦋 🌱🐋 #HistSTM #philsci #evobio

November 8, 2025 at 4:03 PM
Reposted by Arna Ghosh

I’m looking for interns to join our lab for a project on foundation models in neuroscience.
Funded by @ivado.bsky.social and in collaboration with the IVADO regroupement 1 (AI and Neuroscience: ivado.ca/en/regroupem...).
Interested? See the details in the comments. (1/3)
🧠🤖
Funded by @ivado.bsky.social and in collaboration with the IVADO regroupement 1 (AI and Neuroscience: ivado.ca/en/regroupem...).
Interested? See the details in the comments. (1/3)
🧠🤖

AI and Neuroscience | IVADO
ivado.ca
November 7, 2025 at 1:52 PM
I’m looking for interns to join our lab for a project on foundation models in neuroscience.
Funded by @ivado.bsky.social and in collaboration with the IVADO regroupement 1 (AI and Neuroscience: ivado.ca/en/regroupem...).
Interested? See the details in the comments. (1/3)
🧠🤖
Funded by @ivado.bsky.social and in collaboration with the IVADO regroupement 1 (AI and Neuroscience: ivado.ca/en/regroupem...).
Interested? See the details in the comments. (1/3)
🧠🤖
Reposted by Arna Ghosh

A tad late (announcements coming) but very happy to share the latest developments in my previous preprint!
Previously, we show that neural representations for control of movement are largely distinct following supervised or reinforcement learning. The latter most closely matches NHP recordings.
Previously, we show that neural representations for control of movement are largely distinct following supervised or reinforcement learning. The latter most closely matches NHP recordings.
Here’s our latest work at @glajoie.bsky.social and @mattperich.bsky.social ‘s labs! Excited to see this out.
We used a combination of neural recordings & modelling to show that RL yields neural dynamics closer to biology, with useful continual learning properties.
www.biorxiv.org/content/10.1...
We used a combination of neural recordings & modelling to show that RL yields neural dynamics closer to biology, with useful continual learning properties.
www.biorxiv.org/content/10.1...

Brain-like neural dynamics for behavioral control develop through reinforcement learning
During development, neural circuits are shaped continuously as we learn to control our bodies. The ultimate goal of this process is to produce neural dynamics that enable the rich repertoire of behavi...
www.biorxiv.org
November 6, 2025 at 2:10 AM
A tad late (announcements coming) but very happy to share the latest developments in my previous preprint!
Previously, we show that neural representations for control of movement are largely distinct following supervised or reinforcement learning. The latter most closely matches NHP recordings.
Previously, we show that neural representations for control of movement are largely distinct following supervised or reinforcement learning. The latter most closely matches NHP recordings.
LLMs are trained to compress data by mapping sequences to high-dim representations!
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
October 31, 2025 at 4:19 PM
LLMs are trained to compress data by mapping sequences to high-dim representations!
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
Very cool study, with interesting insights about theta sequences and learning!

1/
🚨 New preprint! 🚨
Excited and proud (& a little nervous 😅) to share our latest work on the importance of #theta-timescale spiking during #locomotion in #learning. If you care about how organisms learn, buckle up. 🧵👇
📄 www.biorxiv.org/content/10.1...
💻 code + data 🔗 below 🤩
#neuroskyence
🚨 New preprint! 🚨
Excited and proud (& a little nervous 😅) to share our latest work on the importance of #theta-timescale spiking during #locomotion in #learning. If you care about how organisms learn, buckle up. 🧵👇
📄 www.biorxiv.org/content/10.1...
💻 code + data 🔗 below 🤩
#neuroskyence
September 19, 2025 at 7:07 AM
Very cool study, with interesting insights about theta sequences and learning!
Reposted by Arna Ghosh
Together with @repromancer.bsky.social, I have been musing for a while that the exponentiated gradient algorithm we've advocated for comp neuro would work well with low-precision ANNs.
This group got it working!
arxiv.org/abs/2506.17768
May be a great way to reduce AI energy use!!!
#MLSky 🧪
This group got it working!
arxiv.org/abs/2506.17768
May be a great way to reduce AI energy use!!!
#MLSky 🧪

Log-Normal Multiplicative Dynamics for Stable Low-Precision Training of Large Networks
Studies in neuroscience have shown that biological synapses follow a log-normal distribution whose transitioning can be explained by noisy multiplicative dynamics. Biological networks can function sta...
arxiv.org
July 9, 2025 at 2:34 PM
Together with @repromancer.bsky.social, I have been musing for a while that the exponentiated gradient algorithm we've advocated for comp neuro would work well with low-precision ANNs.
This group got it working!
arxiv.org/abs/2506.17768
May be a great way to reduce AI energy use!!!
#MLSky 🧪
This group got it working!
arxiv.org/abs/2506.17768
May be a great way to reduce AI energy use!!!
#MLSky 🧪
This looks like a very cool result! 😀
Can't wait to read in detail.
Can't wait to read in detail.

Does the brain learn by gradient descent?
It's a pleasure to share our paper at @cp-cell.bsky.social, showing how mice learning over long timescales display key hallmarks of gradient descent (GD).
The culmination of my PhD supervised by @laklab.bsky.social, @saxelab.bsky.social and Rafal Bogacz!
It's a pleasure to share our paper at @cp-cell.bsky.social, showing how mice learning over long timescales display key hallmarks of gradient descent (GD).
The culmination of my PhD supervised by @laklab.bsky.social, @saxelab.bsky.social and Rafal Bogacz!
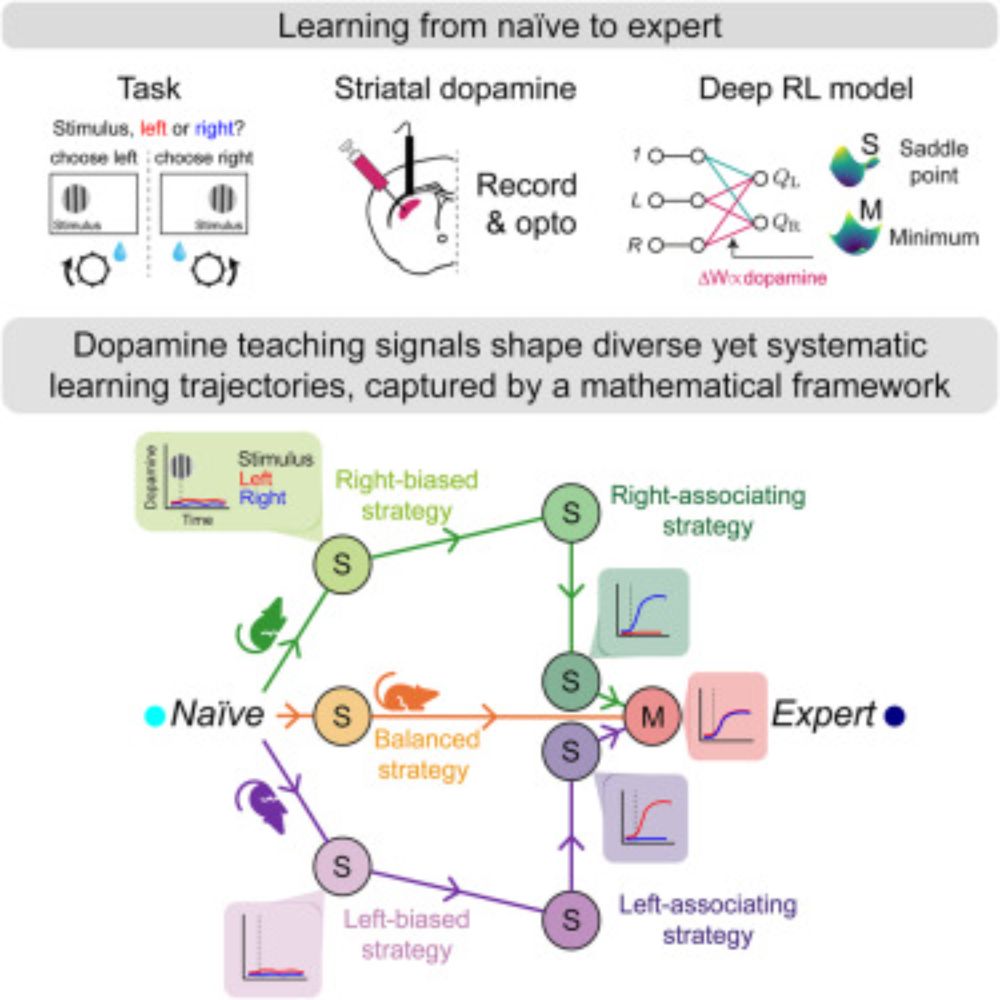
Dopamine encodes deep network teaching signals for individual learning trajectories
Longitudinal tracking of long-term learning behavior and striatal dopamine reveals
that dopamine teaching signals shape individually diverse yet systematic learning
trajectories, captured mathematical...
www.cell.com
June 15, 2025 at 11:03 PM
This looks like a very cool result! 😀
Can't wait to read in detail.
Can't wait to read in detail.

Preprint Alert 🚀
Multi-agent reinforcement learning (MARL) often assumes that agents know when other agents cooperate with them. But for humans, this isn’t always the case. For example, plains indigenous groups used to leave resources for others to use at effigies called Manitokan.
1/8
Multi-agent reinforcement learning (MARL) often assumes that agents know when other agents cooperate with them. But for humans, this isn’t always the case. For example, plains indigenous groups used to leave resources for others to use at effigies called Manitokan.
1/8

June 9, 2025 at 6:16 AM
Reposted by Arna Ghosh

Research Scientist, Paradigms of Intelligence — Google Careers
www.google.com
May 8, 2025 at 9:23 PM
Also, big shoutout to @quentin-garrido.bsky.social+gang and
@aggieinca.bsky.social+gang for developing Rankme and Lidar, respectively.
Reptrix incorporates these representation quality metrics. 🚀
Let's make it easier to select good SSL/foundation models. 💪
@aggieinca.bsky.social+gang for developing Rankme and Lidar, respectively.
Reptrix incorporates these representation quality metrics. 🚀
Let's make it easier to select good SSL/foundation models. 💪
Are you training self-supervised/foundation models, and worried if they are learning good representations? We got you covered! 💪
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning

April 1, 2025 at 8:58 PM
Also, big shoutout to @quentin-garrido.bsky.social+gang and
@aggieinca.bsky.social+gang for developing Rankme and Lidar, respectively.
Reptrix incorporates these representation quality metrics. 🚀
Let's make it easier to select good SSL/foundation models. 💪
@aggieinca.bsky.social+gang for developing Rankme and Lidar, respectively.
Reptrix incorporates these representation quality metrics. 🚀
Let's make it easier to select good SSL/foundation models. 💪
Are you training self-supervised/foundation models, and worried if they are learning good representations? We got you covered! 💪
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning
April 1, 2025 at 6:24 PM
Are you training self-supervised/foundation models, and worried if they are learning good representations? We got you covered! 💪
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning
Super cool paper!
It formalizes a lot of ideas I have been mulling over the past year, and connects tons of historical ideas neatly.
Definitely worth a read if you are working/interested in mechanistic interp and neural representations.
It formalizes a lot of ideas I have been mulling over the past year, and connects tons of historical ideas neatly.
Definitely worth a read if you are working/interested in mechanistic interp and neural representations.

🔵 New paper! We explore sparse coding, superposition, and the Linear Representation Hypothesis (LRH) through identifiability theory, compressed sensing, and interpretability. If you’re curious about lifting neural reps out of superposition, this might interest you! 🤓
arxiv.org/abs/2503.01824
arxiv.org/abs/2503.01824

From superposition to sparse codes: interpretable representations in neural networks
Understanding how information is represented in neural networks is a fundamental challenge in both neuroscience and artificial intelligence. Despite their nonlinear architectures, recent evidence sugg...
arxiv.org
March 8, 2025 at 6:01 AM
Super cool paper!
It formalizes a lot of ideas I have been mulling over the past year, and connects tons of historical ideas neatly.
Definitely worth a read if you are working/interested in mechanistic interp and neural representations.
It formalizes a lot of ideas I have been mulling over the past year, and connects tons of historical ideas neatly.
Definitely worth a read if you are working/interested in mechanistic interp and neural representations.
Just over a week since I defended my 🤖+🧠PhD thesis, and the feeling is just sinking in. Extremely grateful to
@tyrellturing.bsky.social for supporting me through this amazing journey! 🙏
Big thanks to all members of the LiNC lab, and colleagues at mcgill University and @mila-quebec.bsky.social. ❤️😁
@tyrellturing.bsky.social for supporting me through this amazing journey! 🙏
Big thanks to all members of the LiNC lab, and colleagues at mcgill University and @mila-quebec.bsky.social. ❤️😁


February 10, 2025 at 12:36 PM
Just over a week since I defended my 🤖+🧠PhD thesis, and the feeling is just sinking in. Extremely grateful to
@tyrellturing.bsky.social for supporting me through this amazing journey! 🙏
Big thanks to all members of the LiNC lab, and colleagues at mcgill University and @mila-quebec.bsky.social. ❤️😁
@tyrellturing.bsky.social for supporting me through this amazing journey! 🙏
Big thanks to all members of the LiNC lab, and colleagues at mcgill University and @mila-quebec.bsky.social. ❤️😁
Reposted by Arna Ghosh

Just giving this a boost for those who may not have seen it yet... we have a PI position (molecular and cellular basis of cognition) at The Hospital for Sick Children (Toronto). The position comes with an appointment at Assist/Assoc Prof level at U of T. Share widely!
can-acn.org/scientist-se...
can-acn.org/scientist-se...
Scientist/Senior Scientist – Research Institute, Hospital for Sick Children, University of Toronto – Canadian Association for Neuroscience
can-acn.org
January 23, 2025 at 2:16 PM
Just giving this a boost for those who may not have seen it yet... we have a PI position (molecular and cellular basis of cognition) at The Hospital for Sick Children (Toronto). The position comes with an appointment at Assist/Assoc Prof level at U of T. Share widely!
can-acn.org/scientist-se...
can-acn.org/scientist-se...
Come say hi at the noon poster session today in the East hall, poster #2201. 🚀
#NeurIPS2024
#NeurIPS2024
The problem with current SSL? It's hungry. Very hungry. 🤖
Training time: Weeks
Dataset size: Millions of images
Compute costs: 💸💸💸
Our #NeurIPS2024 poster makes SSL pipelines 2x faster and achieves similar accuracy at 50% pretraining cost! 💪🏼✨
🧵 1/8
Training time: Weeks
Dataset size: Millions of images
Compute costs: 💸💸💸
Our #NeurIPS2024 poster makes SSL pipelines 2x faster and achieves similar accuracy at 50% pretraining cost! 💪🏼✨
🧵 1/8
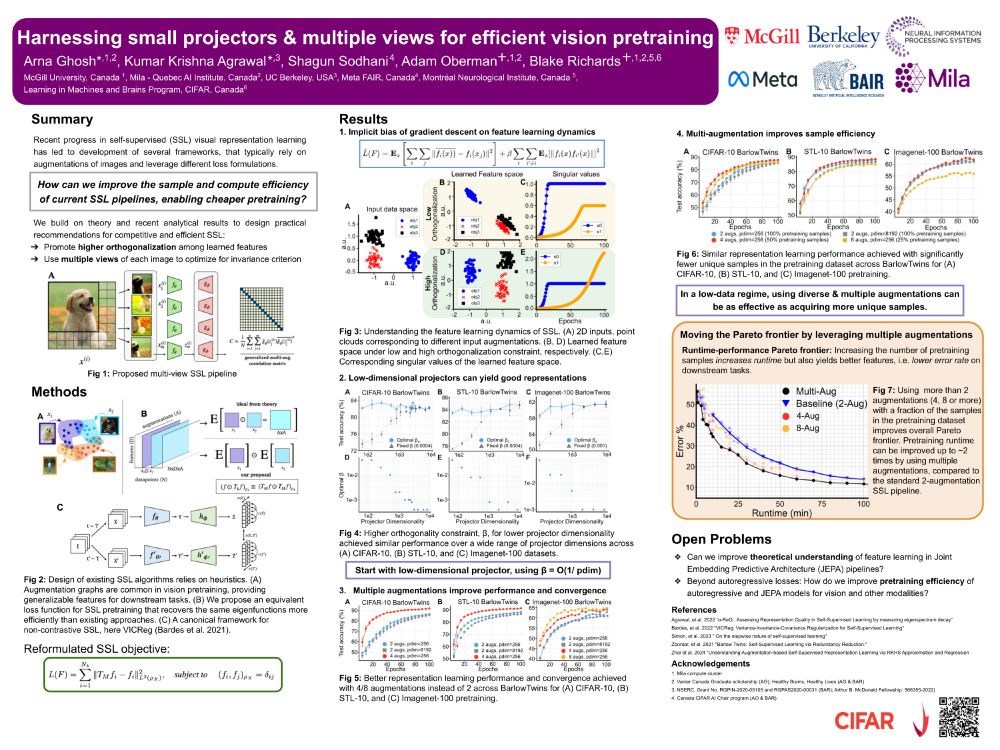
December 13, 2024 at 6:47 PM
Come say hi at the noon poster session today in the East hall, poster #2201. 🚀
#NeurIPS2024
#NeurIPS2024