



Arna Ghosh
@arnaghosh.bsky.social
PhD student at Mila & McGill University, Vanier scholar • 🧠+🤖 grad student• Ex-RealityLabs, Meta AI • Believer in Bio-inspired AI • Comedy+Cricket enthusiast

Indeed! We show in the paper that the DPO objective is analogous to contrastive learning objectives used for self-supervised vision pretraining, which is indeed entropy-seeking in nature (shown in prev works).
I feel spectral metrics can go a long way in unlocking LLM understanding+design. 🚀
I feel spectral metrics can go a long way in unlocking LLM understanding+design. 🚀

November 3, 2025 at 1:51 AM
Indeed! We show in the paper that the DPO objective is analogous to contrastive learning objectives used for self-supervised vision pretraining, which is indeed entropy-seeking in nature (shown in prev works).
I feel spectral metrics can go a long way in unlocking LLM understanding+design. 🚀
I feel spectral metrics can go a long way in unlocking LLM understanding+design. 🚀
Takeaway: LLM training exhibits multi-phasic information geometry changes! ✨
- Pretraining: Compress → Expand (Memorize) → Compress (Generalize).
- Post-training: SFT/DPO → Expand; RLVR → Consolidate.
Representation geometry offers insights into when models memorize vs. generalize! 🤓
🧵8/9
- Pretraining: Compress → Expand (Memorize) → Compress (Generalize).
- Post-training: SFT/DPO → Expand; RLVR → Consolidate.
Representation geometry offers insights into when models memorize vs. generalize! 🤓
🧵8/9
October 31, 2025 at 4:19 PM
Takeaway: LLM training exhibits multi-phasic information geometry changes! ✨
- Pretraining: Compress → Expand (Memorize) → Compress (Generalize).
- Post-training: SFT/DPO → Expand; RLVR → Consolidate.
Representation geometry offers insights into when models memorize vs. generalize! 🤓
🧵8/9
- Pretraining: Compress → Expand (Memorize) → Compress (Generalize).
- Post-training: SFT/DPO → Expand; RLVR → Consolidate.
Representation geometry offers insights into when models memorize vs. generalize! 🤓
🧵8/9
Why do these geometric phases arise?🤔
We show, both through theory and with simulations in a toy model, that these non-monotonic spectral changes occur due to gradient descent dynamics with cross-entropy loss under 2 conditions:
1. skewed token frequencies
2. representation bottlenecks
🧵6/9
We show, both through theory and with simulations in a toy model, that these non-monotonic spectral changes occur due to gradient descent dynamics with cross-entropy loss under 2 conditions:
1. skewed token frequencies
2. representation bottlenecks
🧵6/9
October 31, 2025 at 4:19 PM
Why do these geometric phases arise?🤔
We show, both through theory and with simulations in a toy model, that these non-monotonic spectral changes occur due to gradient descent dynamics with cross-entropy loss under 2 conditions:
1. skewed token frequencies
2. representation bottlenecks
🧵6/9
We show, both through theory and with simulations in a toy model, that these non-monotonic spectral changes occur due to gradient descent dynamics with cross-entropy loss under 2 conditions:
1. skewed token frequencies
2. representation bottlenecks
🧵6/9
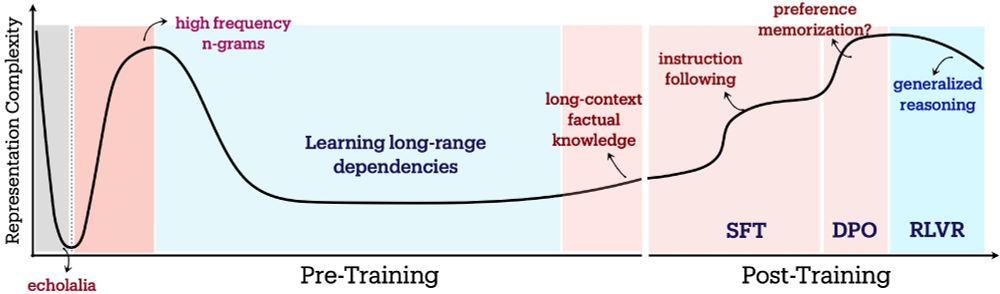
Post-training also yields distinct geometric signatures:
- SFT & DPO exhibit entropy-seeking expansion, favoring instruction memorization but reducing OOD robustness.📈
- RLVR exhibits compression-seeking consolidation, learning reward-aligned behaviors at the cost of reduced exploration.📉
🧵5/9
- SFT & DPO exhibit entropy-seeking expansion, favoring instruction memorization but reducing OOD robustness.📈
- RLVR exhibits compression-seeking consolidation, learning reward-aligned behaviors at the cost of reduced exploration.📉
🧵5/9

October 31, 2025 at 4:19 PM
Post-training also yields distinct geometric signatures:
- SFT & DPO exhibit entropy-seeking expansion, favoring instruction memorization but reducing OOD robustness.📈
- RLVR exhibits compression-seeking consolidation, learning reward-aligned behaviors at the cost of reduced exploration.📉
🧵5/9
- SFT & DPO exhibit entropy-seeking expansion, favoring instruction memorization but reducing OOD robustness.📈
- RLVR exhibits compression-seeking consolidation, learning reward-aligned behaviors at the cost of reduced exploration.📉
🧵5/9
How do these phases relate to LLM behavior?
- Entropy-seeking: Correlates with short-sequence memorization (♾️-gram alignment).
- Compression-seeking: Correlates with dramatic gains in long-context factual reasoning, e.g. TriviaQA.
Curious about ♾️-grams?
See: bsky.app/profile/liuj...
🧵4/9
- Entropy-seeking: Correlates with short-sequence memorization (♾️-gram alignment).
- Compression-seeking: Correlates with dramatic gains in long-context factual reasoning, e.g. TriviaQA.
Curious about ♾️-grams?
See: bsky.app/profile/liuj...
🧵4/9

October 31, 2025 at 4:19 PM
How do these phases relate to LLM behavior?
- Entropy-seeking: Correlates with short-sequence memorization (♾️-gram alignment).
- Compression-seeking: Correlates with dramatic gains in long-context factual reasoning, e.g. TriviaQA.
Curious about ♾️-grams?
See: bsky.app/profile/liuj...
🧵4/9
- Entropy-seeking: Correlates with short-sequence memorization (♾️-gram alignment).
- Compression-seeking: Correlates with dramatic gains in long-context factual reasoning, e.g. TriviaQA.
Curious about ♾️-grams?
See: bsky.app/profile/liuj...
🧵4/9
LLMs have 3 pretraining phases:
Warmup: Rapid compression, collapsing representation to dominant directions.
Entropy-seeking: Manifold expansion, adding info in non-dominant directions.📈
Compression-seeking: Anisotropic consolidation, selectively packing more info in dominant directions.📉
🧵3/9
Warmup: Rapid compression, collapsing representation to dominant directions.
Entropy-seeking: Manifold expansion, adding info in non-dominant directions.📈
Compression-seeking: Anisotropic consolidation, selectively packing more info in dominant directions.📉
🧵3/9

October 31, 2025 at 4:19 PM
LLMs have 3 pretraining phases:
Warmup: Rapid compression, collapsing representation to dominant directions.
Entropy-seeking: Manifold expansion, adding info in non-dominant directions.📈
Compression-seeking: Anisotropic consolidation, selectively packing more info in dominant directions.📉
🧵3/9
Warmup: Rapid compression, collapsing representation to dominant directions.
Entropy-seeking: Manifold expansion, adding info in non-dominant directions.📈
Compression-seeking: Anisotropic consolidation, selectively packing more info in dominant directions.📉
🧵3/9
📐We measured representation complexity using the #eigenspectrum of the final layer representations. We used 2 spectral metrics:
- Spectral Decay Rate, αReQ: Fraction of variance in non-dominant directions.
- RankMe: Effective Rank; #dims truly active.
⬇️αReQ ⇒ ⬆️RankMe ⇒ More complex!
🧵1/9
- Spectral Decay Rate, αReQ: Fraction of variance in non-dominant directions.
- RankMe: Effective Rank; #dims truly active.
⬇️αReQ ⇒ ⬆️RankMe ⇒ More complex!
🧵1/9

October 31, 2025 at 4:19 PM
📐We measured representation complexity using the #eigenspectrum of the final layer representations. We used 2 spectral metrics:
- Spectral Decay Rate, αReQ: Fraction of variance in non-dominant directions.
- RankMe: Effective Rank; #dims truly active.
⬇️αReQ ⇒ ⬆️RankMe ⇒ More complex!
🧵1/9
- Spectral Decay Rate, αReQ: Fraction of variance in non-dominant directions.
- RankMe: Effective Rank; #dims truly active.
⬇️αReQ ⇒ ⬆️RankMe ⇒ More complex!
🧵1/9
LLMs are trained to compress data by mapping sequences to high-dim representations!
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM

October 31, 2025 at 4:19 PM
LLMs are trained to compress data by mapping sequences to high-dim representations!
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
Are you training self-supervised/foundation models, and worried if they are learning good representations? We got you covered! 💪
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning

April 1, 2025 at 6:24 PM
Are you training self-supervised/foundation models, and worried if they are learning good representations? We got you covered! 💪
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning
🦖Introducing Reptrix, a #Python library to evaluate representation quality metrics for neural nets: github.com/BARL-SSL/rep...
🧵👇[1/6]
#DeepLearning
Just over a week since I defended my 🤖+🧠PhD thesis, and the feeling is just sinking in. Extremely grateful to
@tyrellturing.bsky.social for supporting me through this amazing journey! 🙏
Big thanks to all members of the LiNC lab, and colleagues at mcgill University and @mila-quebec.bsky.social. ❤️😁
@tyrellturing.bsky.social for supporting me through this amazing journey! 🙏
Big thanks to all members of the LiNC lab, and colleagues at mcgill University and @mila-quebec.bsky.social. ❤️😁


February 10, 2025 at 12:36 PM
Just over a week since I defended my 🤖+🧠PhD thesis, and the feeling is just sinking in. Extremely grateful to
@tyrellturing.bsky.social for supporting me through this amazing journey! 🙏
Big thanks to all members of the LiNC lab, and colleagues at mcgill University and @mila-quebec.bsky.social. ❤️😁
@tyrellturing.bsky.social for supporting me through this amazing journey! 🙏
Big thanks to all members of the LiNC lab, and colleagues at mcgill University and @mila-quebec.bsky.social. ❤️😁
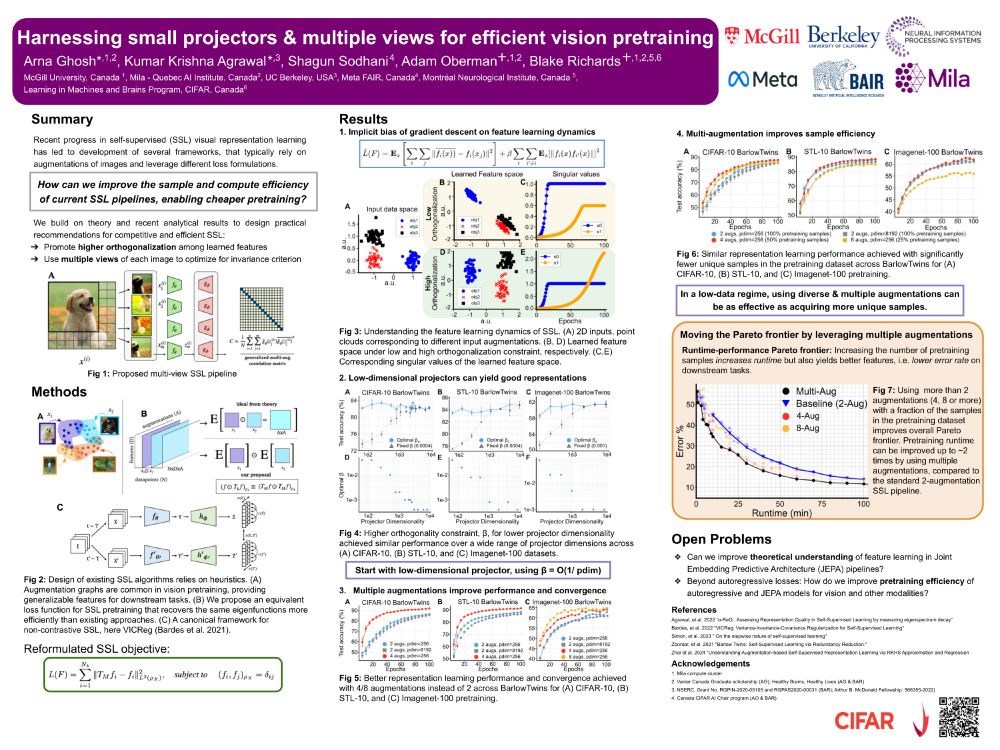
🧵 7/8 Combining smaller projectors, higher # augmentations, and optimal orthogonalization advances the compute-performance Pareto frontier in SSL: 50% less compute for the same downstream performance or better accuracy at a fixed compute budget. 📈

December 13, 2024 at 3:44 AM
🧵 7/8 Combining smaller projectors, higher # augmentations, and optimal orthogonalization advances the compute-performance Pareto frontier in SSL: 50% less compute for the same downstream performance or better accuracy at a fixed compute budget. 📈
🧵 6/8 Multiple augmentations lead to better approximation of the underlying data similarity kernel. More views → better kernel estimation → improved convergence and sample efficiency, matching larger datasets in low-data settings.
4 views 50% data 🤝 2 views 100% data. 📊
4 views 50% data 🤝 2 views 100% data. 📊


December 13, 2024 at 3:44 AM
🧵 6/8 Multiple augmentations lead to better approximation of the underlying data similarity kernel. More views → better kernel estimation → improved convergence and sample efficiency, matching larger datasets in low-data settings.
4 views 50% data 🤝 2 views 100% data. 📊
4 views 50% data 🤝 2 views 100% data. 📊
🧵 5/8 Surprising result: Smaller projector dimensions (reducing projector params by up to 100x) + stronger orthogonalization can match the performance of high-dim projectors! We can get the same representation quality while using less compute 🔥.

December 13, 2024 at 3:44 AM
🧵 5/8 Surprising result: Smaller projector dimensions (reducing projector params by up to 100x) + stronger orthogonalization can match the performance of high-dim projectors! We can get the same representation quality while using less compute 🔥.
🧵 4/8 First key finding: Gradient descent's implicit bias reveals a sweet spot in feature learning. Too little orthogonalization → feature collapse. Too much → unstable learning dynamics.We characterized this trade-off for harnessing the value of small projectors 🎯
December 13, 2024 at 3:44 AM
🧵 4/8 First key finding: Gradient descent's implicit bias reveals a sweet spot in feature learning. Too little orthogonalization → feature collapse. Too much → unstable learning dynamics.We characterized this trade-off for harnessing the value of small projectors 🎯
🧵2/8 While SSL algos like SimCLR/VICReg use diff losses, they optimize the same objective: match the similarity struct given by augmentations. Most are limited to 2 views & need massive compute. We derive an equivalent but computationally efficient formulation of this loss. 🔍

December 13, 2024 at 3:44 AM
🧵2/8 While SSL algos like SimCLR/VICReg use diff losses, they optimize the same objective: match the similarity struct given by augmentations. Most are limited to 2 views & need massive compute. We derive an equivalent but computationally efficient formulation of this loss. 🔍
The problem with current SSL? It's hungry. Very hungry. 🤖
Training time: Weeks
Dataset size: Millions of images
Compute costs: 💸💸💸
Our #NeurIPS2024 poster makes SSL pipelines 2x faster and achieves similar accuracy at 50% pretraining cost! 💪🏼✨
🧵 1/8
Training time: Weeks
Dataset size: Millions of images
Compute costs: 💸💸💸
Our #NeurIPS2024 poster makes SSL pipelines 2x faster and achieves similar accuracy at 50% pretraining cost! 💪🏼✨
🧵 1/8
December 13, 2024 at 3:44 AM
The problem with current SSL? It's hungry. Very hungry. 🤖
Training time: Weeks
Dataset size: Millions of images
Compute costs: 💸💸💸
Our #NeurIPS2024 poster makes SSL pipelines 2x faster and achieves similar accuracy at 50% pretraining cost! 💪🏼✨
🧵 1/8
Training time: Weeks
Dataset size: Millions of images
Compute costs: 💸💸💸
Our #NeurIPS2024 poster makes SSL pipelines 2x faster and achieves similar accuracy at 50% pretraining cost! 💪🏼✨
🧵 1/8