



Arna Ghosh
@arnaghosh.bsky.social
PhD student at Mila & McGill University, Vanier scholar • 🧠+🤖 grad student• Ex-RealityLabs, Meta AI • Believer in Bio-inspired AI • Comedy+Cricket enthusiast
You mean the algorithms "generate" some auxilliary targets and then do supervised learning?
November 8, 2025 at 8:17 AM
You mean the algorithms "generate" some auxilliary targets and then do supervised learning?

Indeed! We show in the paper that the DPO objective is analogous to contrastive learning objectives used for self-supervised vision pretraining, which is indeed entropy-seeking in nature (shown in prev works).
I feel spectral metrics can go a long way in unlocking LLM understanding+design. 🚀
I feel spectral metrics can go a long way in unlocking LLM understanding+design. 🚀

November 3, 2025 at 1:51 AM
Indeed! We show in the paper that the DPO objective is analogous to contrastive learning objectives used for self-supervised vision pretraining, which is indeed entropy-seeking in nature (shown in prev works).
I feel spectral metrics can go a long way in unlocking LLM understanding+design. 🚀
I feel spectral metrics can go a long way in unlocking LLM understanding+design. 🚀
A big shoutout to @koustuvsinha.com for insightful discussions that shaped this work, and
@natolambert.bsky.social + the OLMo team!
Paper 📝: arxiv.org/abs/2509.23024
👩💻 Code : Coming soon! 👨💻
@natolambert.bsky.social + the OLMo team!
Paper 📝: arxiv.org/abs/2509.23024
👩💻 Code : Coming soon! 👨💻

Tracing the Representation Geometry of Language Models from Pretraining to Post-training
Standard training metrics like loss fail to explain the emergence of complex capabilities in large language models. We take a spectral approach to investigate the geometry of learned representations a...
arxiv.org
October 31, 2025 at 4:19 PM
A big shoutout to @koustuvsinha.com for insightful discussions that shaped this work, and
@natolambert.bsky.social + the OLMo team!
Paper 📝: arxiv.org/abs/2509.23024
👩💻 Code : Coming soon! 👨💻
@natolambert.bsky.social + the OLMo team!
Paper 📝: arxiv.org/abs/2509.23024
👩💻 Code : Coming soon! 👨💻
This work was done with dream team 🤩
@melodylizx.bsky.social @kumarkagrawal.bsky.social Komal Teru @glajoie.bsky.social @adamsantoro.bsky.social @tyrellturing.bsky.social
at @mila-quebec.bsky.social @berkeleyair.bsky.social @cohere.com & @googleresearch.bsky.social!
🧵9/9
@melodylizx.bsky.social @kumarkagrawal.bsky.social Komal Teru @glajoie.bsky.social @adamsantoro.bsky.social @tyrellturing.bsky.social
at @mila-quebec.bsky.social @berkeleyair.bsky.social @cohere.com & @googleresearch.bsky.social!
🧵9/9
October 31, 2025 at 4:19 PM
This work was done with dream team 🤩
@melodylizx.bsky.social @kumarkagrawal.bsky.social Komal Teru @glajoie.bsky.social @adamsantoro.bsky.social @tyrellturing.bsky.social
at @mila-quebec.bsky.social @berkeleyair.bsky.social @cohere.com & @googleresearch.bsky.social!
🧵9/9
@melodylizx.bsky.social @kumarkagrawal.bsky.social Komal Teru @glajoie.bsky.social @adamsantoro.bsky.social @tyrellturing.bsky.social
at @mila-quebec.bsky.social @berkeleyair.bsky.social @cohere.com & @googleresearch.bsky.social!
🧵9/9
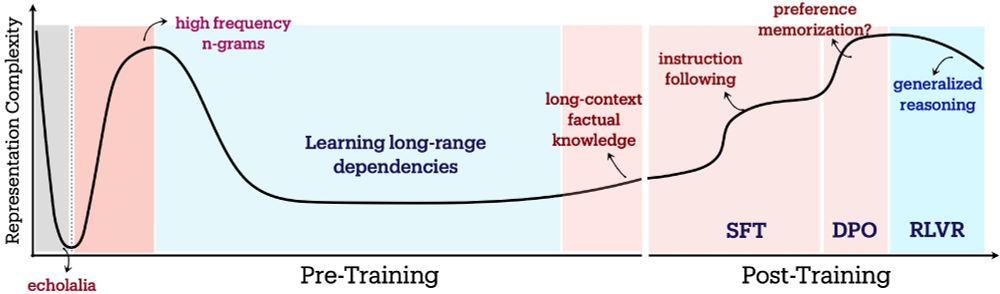
Takeaway: LLM training exhibits multi-phasic information geometry changes! ✨
- Pretraining: Compress → Expand (Memorize) → Compress (Generalize).
- Post-training: SFT/DPO → Expand; RLVR → Consolidate.
Representation geometry offers insights into when models memorize vs. generalize! 🤓
🧵8/9
- Pretraining: Compress → Expand (Memorize) → Compress (Generalize).
- Post-training: SFT/DPO → Expand; RLVR → Consolidate.
Representation geometry offers insights into when models memorize vs. generalize! 🤓
🧵8/9
October 31, 2025 at 4:19 PM
Takeaway: LLM training exhibits multi-phasic information geometry changes! ✨
- Pretraining: Compress → Expand (Memorize) → Compress (Generalize).
- Post-training: SFT/DPO → Expand; RLVR → Consolidate.
Representation geometry offers insights into when models memorize vs. generalize! 🤓
🧵8/9
- Pretraining: Compress → Expand (Memorize) → Compress (Generalize).
- Post-training: SFT/DPO → Expand; RLVR → Consolidate.
Representation geometry offers insights into when models memorize vs. generalize! 🤓
🧵8/9
BONUS: Is task-relevant info contained in the top eigendirections?
On SciQ:
- Removing top 10/50 directions barely hurts accuracy.✅
- Retaining only top 10/50 directions CRUSHES accuracy.📉
As supported by our theoretical results, eigenspectrum tail encodes critical task information! 🤯
🧵7/9
On SciQ:
- Removing top 10/50 directions barely hurts accuracy.✅
- Retaining only top 10/50 directions CRUSHES accuracy.📉
As supported by our theoretical results, eigenspectrum tail encodes critical task information! 🤯
🧵7/9
October 31, 2025 at 4:19 PM
BONUS: Is task-relevant info contained in the top eigendirections?
On SciQ:
- Removing top 10/50 directions barely hurts accuracy.✅
- Retaining only top 10/50 directions CRUSHES accuracy.📉
As supported by our theoretical results, eigenspectrum tail encodes critical task information! 🤯
🧵7/9
On SciQ:
- Removing top 10/50 directions barely hurts accuracy.✅
- Retaining only top 10/50 directions CRUSHES accuracy.📉
As supported by our theoretical results, eigenspectrum tail encodes critical task information! 🤯
🧵7/9
Why do these geometric phases arise?🤔
We show, both through theory and with simulations in a toy model, that these non-monotonic spectral changes occur due to gradient descent dynamics with cross-entropy loss under 2 conditions:
1. skewed token frequencies
2. representation bottlenecks
🧵6/9
We show, both through theory and with simulations in a toy model, that these non-monotonic spectral changes occur due to gradient descent dynamics with cross-entropy loss under 2 conditions:
1. skewed token frequencies
2. representation bottlenecks
🧵6/9
October 31, 2025 at 4:19 PM
Why do these geometric phases arise?🤔
We show, both through theory and with simulations in a toy model, that these non-monotonic spectral changes occur due to gradient descent dynamics with cross-entropy loss under 2 conditions:
1. skewed token frequencies
2. representation bottlenecks
🧵6/9
We show, both through theory and with simulations in a toy model, that these non-monotonic spectral changes occur due to gradient descent dynamics with cross-entropy loss under 2 conditions:
1. skewed token frequencies
2. representation bottlenecks
🧵6/9
Post-training also yields distinct geometric signatures:
- SFT & DPO exhibit entropy-seeking expansion, favoring instruction memorization but reducing OOD robustness.📈
- RLVR exhibits compression-seeking consolidation, learning reward-aligned behaviors at the cost of reduced exploration.📉
🧵5/9
- SFT & DPO exhibit entropy-seeking expansion, favoring instruction memorization but reducing OOD robustness.📈
- RLVR exhibits compression-seeking consolidation, learning reward-aligned behaviors at the cost of reduced exploration.📉
🧵5/9

October 31, 2025 at 4:19 PM
Post-training also yields distinct geometric signatures:
- SFT & DPO exhibit entropy-seeking expansion, favoring instruction memorization but reducing OOD robustness.📈
- RLVR exhibits compression-seeking consolidation, learning reward-aligned behaviors at the cost of reduced exploration.📉
🧵5/9
- SFT & DPO exhibit entropy-seeking expansion, favoring instruction memorization but reducing OOD robustness.📈
- RLVR exhibits compression-seeking consolidation, learning reward-aligned behaviors at the cost of reduced exploration.📉
🧵5/9
How do these phases relate to LLM behavior?
- Entropy-seeking: Correlates with short-sequence memorization (♾️-gram alignment).
- Compression-seeking: Correlates with dramatic gains in long-context factual reasoning, e.g. TriviaQA.
Curious about ♾️-grams?
See: bsky.app/profile/liuj...
🧵4/9
- Entropy-seeking: Correlates with short-sequence memorization (♾️-gram alignment).
- Compression-seeking: Correlates with dramatic gains in long-context factual reasoning, e.g. TriviaQA.
Curious about ♾️-grams?
See: bsky.app/profile/liuj...
🧵4/9

October 31, 2025 at 4:19 PM
How do these phases relate to LLM behavior?
- Entropy-seeking: Correlates with short-sequence memorization (♾️-gram alignment).
- Compression-seeking: Correlates with dramatic gains in long-context factual reasoning, e.g. TriviaQA.
Curious about ♾️-grams?
See: bsky.app/profile/liuj...
🧵4/9
- Entropy-seeking: Correlates with short-sequence memorization (♾️-gram alignment).
- Compression-seeking: Correlates with dramatic gains in long-context factual reasoning, e.g. TriviaQA.
Curious about ♾️-grams?
See: bsky.app/profile/liuj...
🧵4/9
LLMs have 3 pretraining phases:
Warmup: Rapid compression, collapsing representation to dominant directions.
Entropy-seeking: Manifold expansion, adding info in non-dominant directions.📈
Compression-seeking: Anisotropic consolidation, selectively packing more info in dominant directions.📉
🧵3/9
Warmup: Rapid compression, collapsing representation to dominant directions.
Entropy-seeking: Manifold expansion, adding info in non-dominant directions.📈
Compression-seeking: Anisotropic consolidation, selectively packing more info in dominant directions.📉
🧵3/9

October 31, 2025 at 4:19 PM
LLMs have 3 pretraining phases:
Warmup: Rapid compression, collapsing representation to dominant directions.
Entropy-seeking: Manifold expansion, adding info in non-dominant directions.📈
Compression-seeking: Anisotropic consolidation, selectively packing more info in dominant directions.📉
🧵3/9
Warmup: Rapid compression, collapsing representation to dominant directions.
Entropy-seeking: Manifold expansion, adding info in non-dominant directions.📈
Compression-seeking: Anisotropic consolidation, selectively packing more info in dominant directions.📉
🧵3/9
When investigating OLMo (@ai2.bsky.social) & Pythia (@eleutherai.bsky.social) model checkpoints, as expected, pretraining loss ⬇️monotonically.
BUT
🎢The spectral metrics (RankMe, αReQ) change non-monotonically (with more pretraining)!
Takeaway: We discover geometric phases of LLM learning!
🧵2/9
BUT
🎢The spectral metrics (RankMe, αReQ) change non-monotonically (with more pretraining)!
Takeaway: We discover geometric phases of LLM learning!
🧵2/9
October 31, 2025 at 4:19 PM
When investigating OLMo (@ai2.bsky.social) & Pythia (@eleutherai.bsky.social) model checkpoints, as expected, pretraining loss ⬇️monotonically.
BUT
🎢The spectral metrics (RankMe, αReQ) change non-monotonically (with more pretraining)!
Takeaway: We discover geometric phases of LLM learning!
🧵2/9
BUT
🎢The spectral metrics (RankMe, αReQ) change non-monotonically (with more pretraining)!
Takeaway: We discover geometric phases of LLM learning!
🧵2/9
📐We measured representation complexity using the #eigenspectrum of the final layer representations. We used 2 spectral metrics:
- Spectral Decay Rate, αReQ: Fraction of variance in non-dominant directions.
- RankMe: Effective Rank; #dims truly active.
⬇️αReQ ⇒ ⬆️RankMe ⇒ More complex!
🧵1/9
- Spectral Decay Rate, αReQ: Fraction of variance in non-dominant directions.
- RankMe: Effective Rank; #dims truly active.
⬇️αReQ ⇒ ⬆️RankMe ⇒ More complex!
🧵1/9

October 31, 2025 at 4:19 PM
📐We measured representation complexity using the #eigenspectrum of the final layer representations. We used 2 spectral metrics:
- Spectral Decay Rate, αReQ: Fraction of variance in non-dominant directions.
- RankMe: Effective Rank; #dims truly active.
⬇️αReQ ⇒ ⬆️RankMe ⇒ More complex!
🧵1/9
- Spectral Decay Rate, αReQ: Fraction of variance in non-dominant directions.
- RankMe: Effective Rank; #dims truly active.
⬇️αReQ ⇒ ⬆️RankMe ⇒ More complex!
🧵1/9
Congratulations, Dan!! 😁
June 24, 2025 at 9:44 PM
Congratulations, Dan!! 😁
Re diff implicit biases of architecture: the metrics implemented here (roughly) characterize the eigenspectrum (eigenval distribution) of the representation space. They don't really incorporate the eigenvector information --> hence, "what" features don't matter, only "how" matters.
April 2, 2025 at 3:16 AM
Re diff implicit biases of architecture: the metrics implemented here (roughly) characterize the eigenspectrum (eigenval distribution) of the representation space. They don't really incorporate the eigenvector information --> hence, "what" features don't matter, only "how" matters.