


Paul Medvedev
@pashadag.bsky.social
Algorithmic Bioinformatics Researcher and Teacher. Posts about research results and educational/mentorship topics (for details, see http://bit.ly/380vX22).
Reposted by Paul Medvedev

At long last, my final PhD chapter is out: we developed a novel evolutionary simulator of bacterial pangenomes, Pansim, fitting it to data from >600K genomes using a likelihood-free framework, PopPUNK-mod, to explore neutral and adaptive pangenome dynamics www.biorxiv.org/content/10.6...
www.biorxiv.org
February 7, 2026 at 10:08 AM
At long last, my final PhD chapter is out: we developed a novel evolutionary simulator of bacterial pangenomes, Pansim, fitting it to data from >600K genomes using a likelihood-free framework, PopPUNK-mod, to explore neutral and adaptive pangenome dynamics www.biorxiv.org/content/10.6...
Reposted by Paul Medvedev

🚨UPCOMING DEADLINES🚨
RECOMB-CG: 13 February
RECOMB-RSG: 15 February
RECOMB-Privacy: 9 March
RECOMB-Seq: 12 March (abstract registration)
RECOMB-Arch: 12 March (abstract registration)
RECOMB-Genetics: 13 March
#RECOMB2026 #deadlines
RECOMB-CG: 13 February
RECOMB-RSG: 15 February
RECOMB-Privacy: 9 March
RECOMB-Seq: 12 March (abstract registration)
RECOMB-Arch: 12 March (abstract registration)
RECOMB-Genetics: 13 March
#RECOMB2026 #deadlines
February 5, 2026 at 8:41 PM
🚨UPCOMING DEADLINES🚨
RECOMB-CG: 13 February
RECOMB-RSG: 15 February
RECOMB-Privacy: 9 March
RECOMB-Seq: 12 March (abstract registration)
RECOMB-Arch: 12 March (abstract registration)
RECOMB-Genetics: 13 March
#RECOMB2026 #deadlines
RECOMB-CG: 13 February
RECOMB-RSG: 15 February
RECOMB-Privacy: 9 March
RECOMB-Seq: 12 March (abstract registration)
RECOMB-Arch: 12 March (abstract registration)
RECOMB-Genetics: 13 March
#RECOMB2026 #deadlines
Reposted by Paul Medvedev

Time for a thread on our Christmas preprint “Origin and evolution of acrocentric chromosomes in human and great apes”. I had so much fun with this project and paper. It will be hard to summarize in a thread, but I’ll try www.biorxiv.org/content/10.6... [1/21]

February 2, 2026 at 2:58 PM
Time for a thread on our Christmas preprint “Origin and evolution of acrocentric chromosomes in human and great apes”. I had so much fun with this project and paper. It will be hard to summarize in a thread, but I’ll try www.biorxiv.org/content/10.6... [1/21]
Reposted by Paul Medvedev

PREPRINT ALERT
I heard you craving for more combinatorics, here are some more for y'all !
I heard you craving for more combinatorics, here are some more for y'all !

Florian Ingels, Antoine Limasset, Camille Marchet, Mika\"el Salson: Vigemers: on the number of $k$-mers sharing the same XOR-based minimizer https://arxiv.org/abs/2602.03337 https://arxiv.org/pdf/2602.03337 https://arxiv.org/html/2602.03337
February 4, 2026 at 5:22 PM
PREPRINT ALERT
I heard you craving for more combinatorics, here are some more for y'all !
I heard you craving for more combinatorics, here are some more for y'all !
Reposted by Paul Medvedev

Preprint alert!
arxiv.org/abs/2602.03525
TLDR:
ZOR filters are STATIC filters with false positives.
-Almost memory optimal: <1% overhead over the theoretical lower bound (!!!)
-Fast queries: ~100 ns
-Construction cannot fail
A thread:
arxiv.org/abs/2602.03525
TLDR:
ZOR filters are STATIC filters with false positives.
-Almost memory optimal: <1% overhead over the theoretical lower bound (!!!)
-Fast queries: ~100 ns
-Construction cannot fail
A thread:

ZOR filters: fast and smaller than fuse filters
Probabilistic membership filters support fast approximate membership queries with a controlled false-positive probability $\varepsilon$ and are widely used across storage, analytics, networking, and b...
arxiv.org
February 4, 2026 at 12:28 PM
Preprint alert!
arxiv.org/abs/2602.03525
TLDR:
ZOR filters are STATIC filters with false positives.
-Almost memory optimal: <1% overhead over the theoretical lower bound (!!!)
-Fast queries: ~100 ns
-Construction cannot fail
A thread:
arxiv.org/abs/2602.03525
TLDR:
ZOR filters are STATIC filters with false positives.
-Almost memory optimal: <1% overhead over the theoretical lower bound (!!!)
-Fast queries: ~100 ns
-Construction cannot fail
A thread:
Reposted by Paul Medvedev

If you are an Israeli PhD student and are interested in a postdoc at Harvard Medical (my lab included!), I strongly recommend looking into the Kalaniyot fellowship program, providing 2-3 years of full support:
globalprograms.hms.harvard.edu/kalaniyot-hm...
globalprograms.hms.harvard.edu/kalaniyot-hm...
Programs
globalprograms.hms.harvard.edu
January 15, 2026 at 7:23 PM
If you are an Israeli PhD student and are interested in a postdoc at Harvard Medical (my lab included!), I strongly recommend looking into the Kalaniyot fellowship program, providing 2-3 years of full support:
globalprograms.hms.harvard.edu/kalaniyot-hm...
globalprograms.hms.harvard.edu/kalaniyot-hm...
Reposted by Paul Medvedev

The 12th edition of the 2-days workshop “Data Structures in Bioinformatics” (DSB) will take place in Venice (Italy) on February 18-19th, 2026: dsb-meeting.github.io/DSB2026/
DSB 2026 Venice - February 18-19
Workshop Data Structures in Bioinformatics
dsb-meeting.github.io
December 10, 2025 at 2:29 PM
The 12th edition of the 2-days workshop “Data Structures in Bioinformatics” (DSB) will take place in Venice (Italy) on February 18-19th, 2026: dsb-meeting.github.io/DSB2026/
This thread gives really interesting and relevant history!
December 3, 2025 at 3:29 PM
This thread gives really interesting and relevant history!
Reposted by Paul Medvedev

Kraken 2 (K2) community: we are giving more attention to our new `k2` wrapper, and a NEW functionality since 2.17.0 is: you can build several component K2 indexes, e.g. each covering a different Refseq database, and then query them all at once...
github.com/DerrickWood/... 1/6
github.com/DerrickWood/... 1/6
github.com
December 3, 2025 at 2:09 PM
Kraken 2 (K2) community: we are giving more attention to our new `k2` wrapper, and a NEW functionality since 2.17.0 is: you can build several component K2 indexes, e.g. each covering a different Refseq database, and then query them all at once...
github.com/DerrickWood/... 1/6
github.com/DerrickWood/... 1/6
Reposted by Paul Medvedev
Preprint alert!
We introduce new ideas to revisit the notion of sampling with window guarantees, also known as minimizers.
A thread:
We introduce new ideas to revisit the notion of sampling with window guarantees, also known as minimizers.
A thread:
Minimizer Density revisited: Models and Multiminimizers https://www.biorxiv.org/content/10.1101/2025.11.21.689688v1
December 2, 2025 at 11:12 AM
Preprint alert!
We introduce new ideas to revisit the notion of sampling with window guarantees, also known as minimizers.
A thread:
We introduce new ideas to revisit the notion of sampling with window guarantees, also known as minimizers.
A thread:
Reposted by Paul Medvedev

Interested in a post-doc in Israel? The deadline for the Azrieli International Postdoctoral Fellowship is November 19. The fellowship offers generous funding for postdocs to conduct research in any academic discipline at eligible Israeli institutions: azrielifoundation.org/fellows/inte...
International Postdoctoral Fellowship - The Azrieli Foundation
The Azrieli Fellows Program is an elite group of academics who cultivate a network of leading professionals in Israel and around the world.
azrielifoundation.org
November 10, 2025 at 8:59 AM
Interested in a post-doc in Israel? The deadline for the Azrieli International Postdoctoral Fellowship is November 19. The fellowship offers generous funding for postdocs to conduct research in any academic discipline at eligible Israeli institutions: azrielifoundation.org/fellows/inte...
Reposted by Paul Medvedev

Haonan Wu gives a talk on "A k-mer-based estimator of the substitution rate between repetitive sequences"
www.biorxiv.org/content/10.1...
This work tackles the issue of Mash which ignores repeats in the genome, providing better distance estimation #GI2025
www.biorxiv.org/content/10.1...
This work tackles the issue of Mash which ignores repeats in the genome, providing better distance estimation #GI2025


November 6, 2025 at 4:38 PM
Haonan Wu gives a talk on "A k-mer-based estimator of the substitution rate between repetitive sequences"
www.biorxiv.org/content/10.1...
This work tackles the issue of Mash which ignores repeats in the genome, providing better distance estimation #GI2025
www.biorxiv.org/content/10.1...
This work tackles the issue of Mash which ignores repeats in the genome, providing better distance estimation #GI2025
Reposted by Paul Medvedev
After years of research and continuous refinement, we’re thrilled to share that our paper on the MetaGraph framework — enabling Petabase-scale search across sequencing data — has been published today in Nature (www.nature.com/articles/s41...)

Efficient and accurate search in petabase-scale sequence repositories - Nature
MetaGraph enables scalable indexing of large sets of DNA, RNA or protein sequences using annotated de Bruijn graphs.
www.nature.com
October 8, 2025 at 8:56 PM
After years of research and continuous refinement, we’re thrilled to share that our paper on the MetaGraph framework — enabling Petabase-scale search across sequencing data — has been published today in Nature (www.nature.com/articles/s41...)
Reposted by Paul Medvedev

And it's posted! If you're interested and eligible, please consider applying through the UMD portal: umd.wd1.myworkdayjobs.com/en-US/UMCP/j....
If you're a PI working in algorithmic genomics (& you can recommend my lab to your top graduating students ;P), please let them know!
If you're a PI working in algorithmic genomics (& you can recommend my lab to your top graduating students ;P), please let them know!
October 8, 2025 at 4:53 PM
And it's posted! If you're interested and eligible, please consider applying through the UMD portal: umd.wd1.myworkdayjobs.com/en-US/UMCP/j....
If you're a PI working in algorithmic genomics (& you can recommend my lab to your top graduating students ;P), please let them know!
If you're a PI working in algorithmic genomics (& you can recommend my lab to your top graduating students ;P), please let them know!
Reposted by Paul Medvedev
I've added 7 videos to my Burrows-Wheeler indexing playlist (www.youtube.com/playlist?lis...), rounding out the r-index series and adding a 5-part series on the move structure. Now 27 videos in that playlist. I aim to add videos on prefix-free parsing, PBWT, Wheeler languages/automata in the future.

Burrows-Wheeler Indexing - YouTube
Videos on : (a) the Burrows-Wheeler Transform (BWT), (b) the FM Index, which uses the BWT to construct a full-text index, (c) Wheeler graphs, (d) r-index, an...
www.youtube.com
October 7, 2025 at 2:17 PM
I've added 7 videos to my Burrows-Wheeler indexing playlist (www.youtube.com/playlist?lis...), rounding out the r-index series and adding a 5-part series on the move structure. Now 27 videos in that playlist. I aim to add videos on prefix-free parsing, PBWT, Wheeler languages/automata in the future.
Reposted by Paul Medvedev

Our preprint on our new metagenomic HiFi assembler Alice is out 🥳 Based on a *new sketching method* (🧵1/6)
👉 Preprint www.biorxiv.org/content/10.1...
👉 Github github.com/rolandfaure/...
👉 Preprint www.biorxiv.org/content/10.1...
👉 Github github.com/rolandfaure/...

Alice: fast and haplotype-aware assembly of high-fidelity reads based on MSR sketching
We introduce Mapping-friendly Sequence Reduction (MSR) sketches, a sketching method for high-fidelity (HiFi) long reads, and Alice, an assembler that operates directly on these sketches. MSR produces ...
www.biorxiv.org
October 3, 2025 at 2:51 PM
Our preprint on our new metagenomic HiFi assembler Alice is out 🥳 Based on a *new sketching method* (🧵1/6)
👉 Preprint www.biorxiv.org/content/10.1...
👉 Github github.com/rolandfaure/...
👉 Preprint www.biorxiv.org/content/10.1...
👉 Github github.com/rolandfaure/...
Reposted by Paul Medvedev

Alice: fast and haplotype-aware assembly of high-fidelity reads based on MSR sketching https://www.biorxiv.org/content/10.1101/2025.09.29.679204v1
October 1, 2025 at 1:47 AM
Alice: fast and haplotype-aware assembly of high-fidelity reads based on MSR sketching https://www.biorxiv.org/content/10.1101/2025.09.29.679204v1
Reposted by Paul Medvedev
#RECOMB2026 will be in Thessaloniki, Greece on May 26-29, 2026. Satellites on May 24-25. Save the date!
Το συνέδριο #RECOMB2026 θα πραγματοποιηθεί στη Θεσσαλονίκη, στις 26-29 Μαΐου 2026. Οι δορυφορικές εκδηλώσεις θα διεξαχθούν στις 24-25 Μαΐου 2026. Σημειώστε την ημερομηνία!
Το συνέδριο #RECOMB2026 θα πραγματοποιηθεί στη Θεσσαλονίκη, στις 26-29 Μαΐου 2026. Οι δορυφορικές εκδηλώσεις θα διεξαχθούν στις 24-25 Μαΐου 2026. Σημειώστε την ημερομηνία!

September 26, 2025 at 3:03 PM
#RECOMB2026 will be in Thessaloniki, Greece on May 26-29, 2026. Satellites on May 24-25. Save the date!
Το συνέδριο #RECOMB2026 θα πραγματοποιηθεί στη Θεσσαλονίκη, στις 26-29 Μαΐου 2026. Οι δορυφορικές εκδηλώσεις θα διεξαχθούν στις 24-25 Μαΐου 2026. Σημειώστε την ημερομηνία!
Το συνέδριο #RECOMB2026 θα πραγματοποιηθεί στη Θεσσαλονίκη, στις 26-29 Μαΐου 2026. Οι δορυφορικές εκδηλώσεις θα διεξαχθούν στις 24-25 Μαΐου 2026. Σημειώστε την ημερομηνία!
If you're wondering why we're hosting the pre-print via dropbox, its because arXiv (and bioRxiv) did not accept it (because it is a review). Its a bit disconcerting, because a review is precisely the type of paper that would benefit a lot from pre-publication dissemination and feedback.
Thank you folks for your feedback on our survey about Hash functions in genomic sequence analysis. We've updated the paper and you can see the new version here: tinyurl.com/4kk9ccmt.
September 25, 2025 at 1:25 PM
If you're wondering why we're hosting the pre-print via dropbox, its because arXiv (and bioRxiv) did not accept it (because it is a review). Its a bit disconcerting, because a review is precisely the type of paper that would benefit a lot from pre-publication dissemination and feedback.
Thank you folks for your feedback on our survey about Hash functions in genomic sequence analysis. We've updated the paper and you can see the new version here: tinyurl.com/4kk9ccmt.
September 25, 2025 at 1:21 PM
Thank you folks for your feedback on our survey about Hash functions in genomic sequence analysis. We've updated the paper and you can see the new version here: tinyurl.com/4kk9ccmt.
Reposted by Paul Medvedev
Excited to share our EvANI benchmarking workflow, published in Briefings in Bioinformatics doi.org/10.1093/bib/...
Computing average nucleotide identity (ANI) is neither conceptually nor computationally trivial. Its definition has evolved over years, with different meanings and assumptions (1/5)
Computing average nucleotide identity (ANI) is neither conceptually nor computationally trivial. Its definition has evolved over years, with different meanings and assumptions (1/5)

September 21, 2025 at 3:26 PM
Excited to share our EvANI benchmarking workflow, published in Briefings in Bioinformatics doi.org/10.1093/bib/...
Computing average nucleotide identity (ANI) is neither conceptually nor computationally trivial. Its definition has evolved over years, with different meanings and assumptions (1/5)
Computing average nucleotide identity (ANI) is neither conceptually nor computationally trivial. Its definition has evolved over years, with different meanings and assumptions (1/5)
Reposted by Paul Medvedev

Preprint out for myloasm, our new nanopore / HiFi metagenome assembler!
Nanopore's getting accurate, but
1. Can this lead to better metagenome assemblies?
2. How, algorithmically, to leverage them?
with co-author Max Marin @mgmarin.bsky.social, supervised by Heng Li @lh3lh3.bsky.social
1 / N
Nanopore's getting accurate, but
1. Can this lead to better metagenome assemblies?
2. How, algorithmically, to leverage them?
with co-author Max Marin @mgmarin.bsky.social, supervised by Heng Li @lh3lh3.bsky.social
1 / N
High-resolution metagenome assembly for modern long reads with myloasm https://www.biorxiv.org/content/10.1101/2025.09.05.674543v1
September 7, 2025 at 11:35 PM
Preprint out for myloasm, our new nanopore / HiFi metagenome assembler!
Nanopore's getting accurate, but
1. Can this lead to better metagenome assemblies?
2. How, algorithmically, to leverage them?
with co-author Max Marin @mgmarin.bsky.social, supervised by Heng Li @lh3lh3.bsky.social
1 / N
Nanopore's getting accurate, but
1. Can this lead to better metagenome assemblies?
2. How, algorithmically, to leverage them?
with co-author Max Marin @mgmarin.bsky.social, supervised by Heng Li @lh3lh3.bsky.social
1 / N
Reposted by Paul Medvedev

🌎👩🔬 For 15+ years biology has accumulated petabytes (million gigabytes) of🧬DNA sequencing data🧬 from the far reaches of our planet.🦠🍄🌵
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
doi.org/10.1101/2024...
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
doi.org/10.1101/2024...

September 3, 2025 at 8:39 AM
🌎👩🔬 For 15+ years biology has accumulated petabytes (million gigabytes) of🧬DNA sequencing data🧬 from the far reaches of our planet.🦠🍄🌵
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
doi.org/10.1101/2024...
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
doi.org/10.1101/2024...
Reposted by Paul Medvedev

Two papers in today's issue of @nature.com : 1) we assemble 65 genomes to near completion, including centromeres and the MHC. tinyurl.com/3huhax6w. 2) we sequence 1,019 genomes from the 1kGP with long reads, revealing SVs down to low allele frequencies tinyurl.com/wbx3we9x.
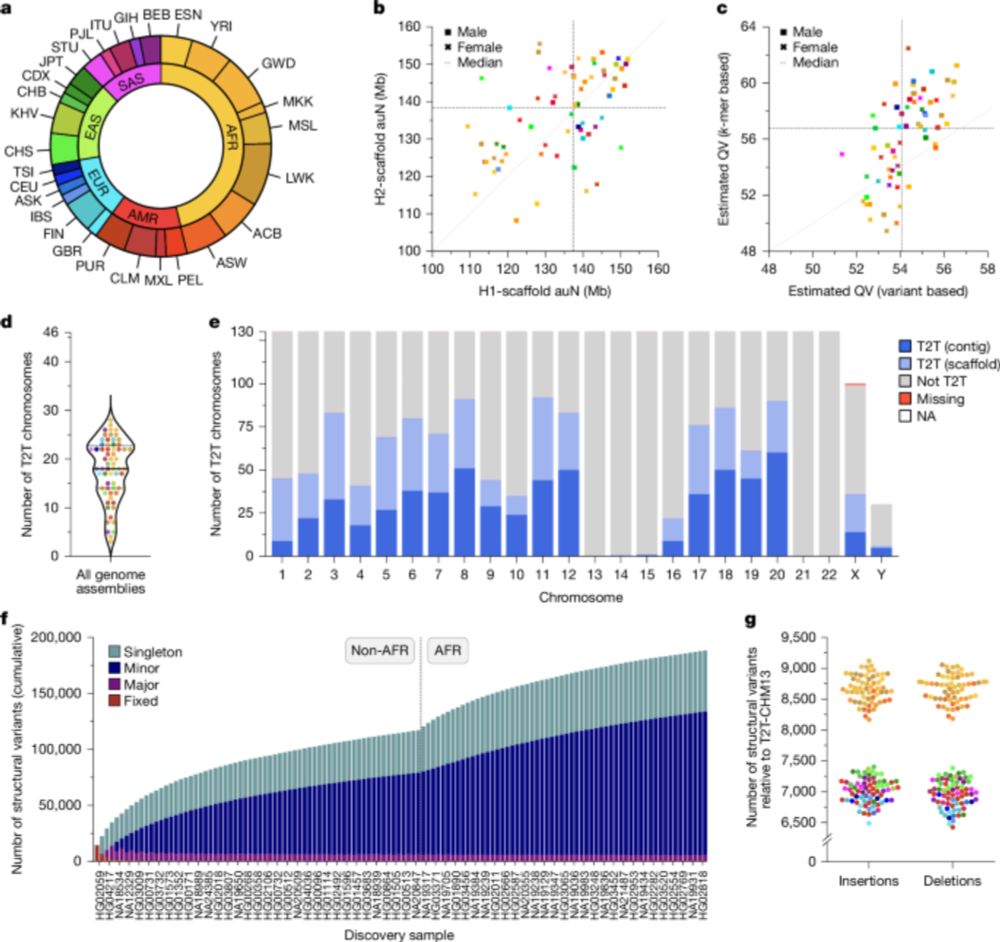
Complex genetic variation in nearly complete human genomes - Nature
Using sequencing and haplotype-resolved assembly of 65 diverse human genomes, complex regions including the major histocompatibility complex and centromeres are analysed.
tinyurl.com
July 23, 2025 at 3:12 PM
Two papers in today's issue of @nature.com : 1) we assemble 65 genomes to near completion, including centromeres and the MHC. tinyurl.com/3huhax6w. 2) we sequence 1,019 genomes from the 1kGP with long reads, revealing SVs down to low allele frequencies tinyurl.com/wbx3we9x.
Reposted by Paul Medvedev

Interested in a tool that aligns millions of proteins in minutes with quality similar to or better than the state-of-the-art utilities? Please take a look at our FAMSA2 paper: www.biorxiv.org/content/10.1...
and GH repo: github.com/refresh-bio/...
and GH repo: github.com/refresh-bio/...

FAMSA2 enables accurate multiple sequence alignment at protein-universe scale
We introduce FAMSA2, an algorithm that produces high-accuracy multiple protein sequence alignments with unprecedented speed. Across structural, phylogenetic, and functional benchmarks, FAMSA2 matches ...
www.biorxiv.org
July 19, 2025 at 9:28 PM
Interested in a tool that aligns millions of proteins in minutes with quality similar to or better than the state-of-the-art utilities? Please take a look at our FAMSA2 paper: www.biorxiv.org/content/10.1...
and GH repo: github.com/refresh-bio/...
and GH repo: github.com/refresh-bio/...