



Ekdeep Singh @ ICML
@ekdeepl.bsky.social
Postdoc at CBS, Harvard University
(New around here)
(New around here)
Tubingen just got ultra-exciting :D

🚨 Incredibly excited to share that I'm starting my research group focusing on AI safety and alignment at the ELLIS Institute Tübingen and Max Planck Institute for Intelligent Systems in September 2025! 🚨
1/n
1/n

August 6, 2025 at 3:49 PM
Tubingen just got ultra-exciting :D
Submit your latest and greatest papers to the hottest workshop on the block---on cognitive interpretability! 🔥
Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
Home
First Workshop on Interpreting Cognition in Deep Learning Models (NeurIPS 2025)
coginterp.github.io
July 16, 2025 at 2:12 PM
Submit your latest and greatest papers to the hottest workshop on the block---on cognitive interpretability! 🔥
Reposted by Ekdeep Singh @ ICML

Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
Home
First Workshop on Interpreting Cognition in Deep Learning Models (NeurIPS 2025)
coginterp.github.io
July 16, 2025 at 1:08 PM
Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
I'll be at ICML beginning this Monday---hit me up if you'd like to chat!
July 12, 2025 at 12:33 AM
I'll be at ICML beginning this Monday---hit me up if you'd like to chat!
Check out one of the most exciting papers of the year! :D

🚨New paper! We know models learn distinct in-context learning strategies, but *why*? Why generalize instead of memorize to lower loss? And why is generalization transient?
Our work explains this & *predicts Transformer behavior throughout training* without its weights! 🧵
1/
Our work explains this & *predicts Transformer behavior throughout training* without its weights! 🧵
1/
June 28, 2025 at 4:49 AM
Check out one of the most exciting papers of the year! :D
I'll be attending NAACL at New Mexico beginning today---hit me up if you'd like to chat!
April 29, 2025 at 2:10 PM
I'll be attending NAACL at New Mexico beginning today---hit me up if you'd like to chat!
Check out our new work on the duality between SAEs and how concepts are organized in model representations!
New preprint alert!
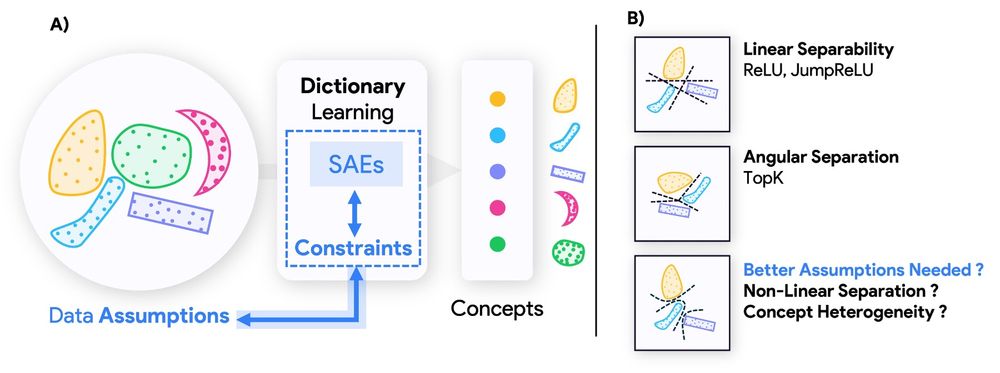
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
March 7, 2025 at 2:56 AM
Check out our new work on the duality between SAEs and how concepts are organized in model representations!
Reposted by Ekdeep Singh @ ICML

New preprint alert!
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
March 7, 2025 at 2:48 AM
New preprint alert!
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
Reposted by Ekdeep Singh @ ICML

Very nice paper; quite aligned with the ideas in our recent perspective on the broader spectrum of ICL. In large models, there's probably a complicated, context dependent mixture of strategies that get learned, not a single ability.
New paper–accepted as *spotlight* at #ICLR2025! 🧵👇
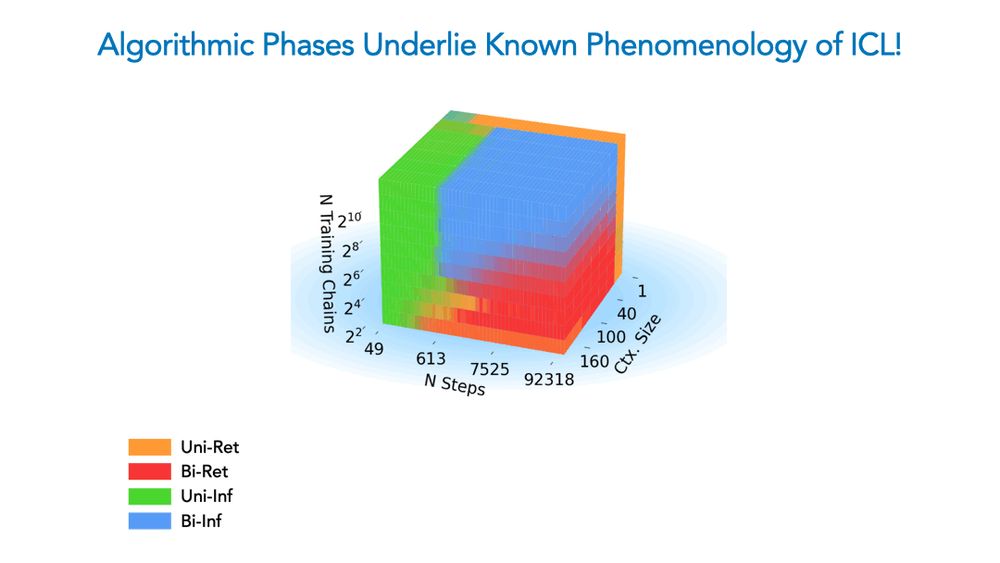
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
February 16, 2025 at 7:22 PM
Very nice paper; quite aligned with the ideas in our recent perspective on the broader spectrum of ICL. In large models, there's probably a complicated, context dependent mixture of strategies that get learned, not a single ability.
New paper–accepted as *spotlight* at #ICLR2025! 🧵👇
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
February 16, 2025 at 6:57 PM
New paper–accepted as *spotlight* at #ICLR2025! 🧵👇
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
There's never been a more exciting time to explore the science of intelligence! 🧠
What can ideas and approaches from science tell us about how AI works?
What might superhuman AI reveal about human cognition?
Join us for an internship at Harvard to explore together!
1/
What can ideas and approaches from science tell us about how AI works?
What might superhuman AI reveal about human cognition?
Join us for an internship at Harvard to explore together!
1/

February 12, 2025 at 4:30 PM
There's never been a more exciting time to explore the science of intelligence! 🧠
What can ideas and approaches from science tell us about how AI works?
What might superhuman AI reveal about human cognition?
Join us for an internship at Harvard to explore together!
1/
What can ideas and approaches from science tell us about how AI works?
What might superhuman AI reveal about human cognition?
Join us for an internship at Harvard to explore together!
1/
Now accepted at NAACL! This would be my first time presenting at an ACL conference---I've got almost first-year grad school level of excitement! :P
Paper alert––*Awarded best paper* at NeurIPS workshop on Foundation Model Interventions! 🧵👇
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
January 23, 2025 at 7:15 AM
Now accepted at NAACL! This would be my first time presenting at an ACL conference---I've got almost first-year grad school level of excitement! :P
Reposted by Ekdeep Singh @ ICML

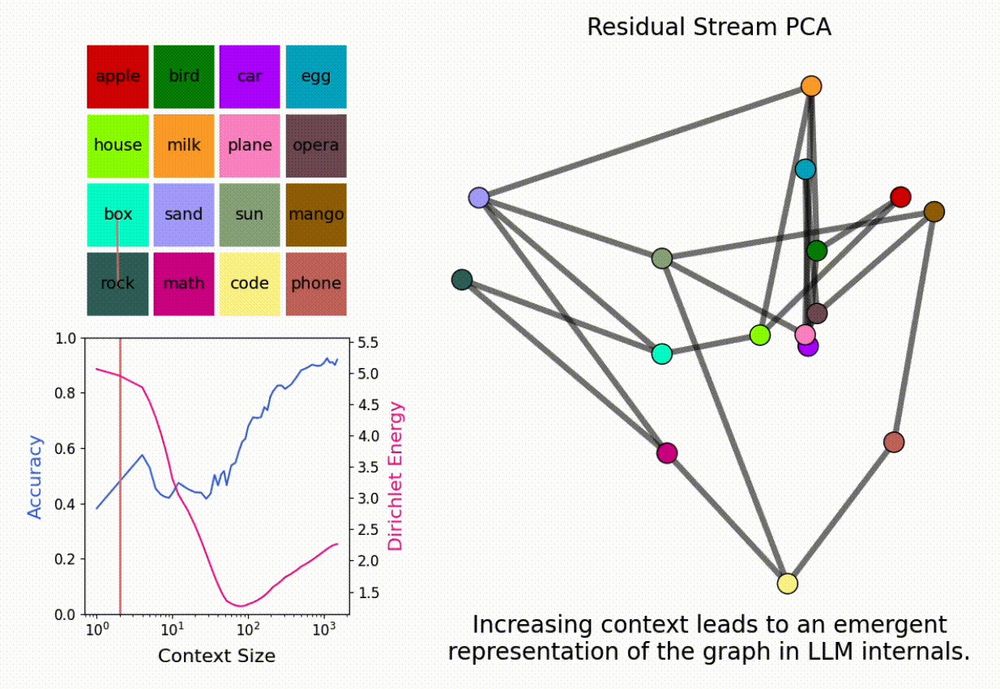
New paper! “In-Context Learning of Representations”
What happens to an LLM’s internal representations in the large context limit?
We find that LLMs form “in-context representations” to match the structure of the task given in context!
What happens to an LLM’s internal representations in the large context limit?
We find that LLMs form “in-context representations” to match the structure of the task given in context!
January 5, 2025 at 4:02 PM
New paper! “In-Context Learning of Representations”
What happens to an LLM’s internal representations in the large context limit?
We find that LLMs form “in-context representations” to match the structure of the task given in context!
What happens to an LLM’s internal representations in the large context limit?
We find that LLMs form “in-context representations” to match the structure of the task given in context!
Reposted by Ekdeep Singh @ ICML

New paper <3
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
January 5, 2025 at 3:49 PM
New paper <3
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
Reposted by Ekdeep Singh @ ICML

Transformer LMs get pretty far by acting like ngram models, so why do they learn syntax? A new paper by sunnytqin.bsky.social, me, and @dmelis.bsky.social illuminates grammar learning in a whirlwind tour of generalization, grokking, training dynamics, memorization, and random variation. #mlsky #nlp

Sometimes I am a Tree: Data Drives Unstable Hierarchical Generalization
Language models (LMs), like other neural networks, often favor shortcut heuristics based on surface-level patterns. Although LMs behave like n-gram models early in training, they must eventually learn...
arxiv.org
December 20, 2024 at 5:56 PM
Transformer LMs get pretty far by acting like ngram models, so why do they learn syntax? A new paper by sunnytqin.bsky.social, me, and @dmelis.bsky.social illuminates grammar learning in a whirlwind tour of generalization, grokking, training dynamics, memorization, and random variation. #mlsky #nlp
Paper alert––*Awarded best paper* at NeurIPS workshop on Foundation Model Interventions! 🧵👇
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
December 18, 2024 at 1:45 PM
Paper alert––*Awarded best paper* at NeurIPS workshop on Foundation Model Interventions! 🧵👇
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
Paper alert—accepted as a *Spotlight* at NeurIPS!🧵
Building on our work relating emergent abilities to task compositionality, we analyze the *learning dynamics* of compositional abilities & find there exist latent interventions that can elicit them much before input prompting works! 🤯
Building on our work relating emergent abilities to task compositionality, we analyze the *learning dynamics* of compositional abilities & find there exist latent interventions that can elicit them much before input prompting works! 🤯

November 10, 2024 at 11:14 PM
Paper alert—accepted as a *Spotlight* at NeurIPS!🧵
Building on our work relating emergent abilities to task compositionality, we analyze the *learning dynamics* of compositional abilities & find there exist latent interventions that can elicit them much before input prompting works! 🤯
Building on our work relating emergent abilities to task compositionality, we analyze the *learning dynamics* of compositional abilities & find there exist latent interventions that can elicit them much before input prompting works! 🤯