



Ekdeep Singh @ ICML
@ekdeepl.bsky.social
Postdoc at CBS, Harvard University
(New around here)
(New around here)
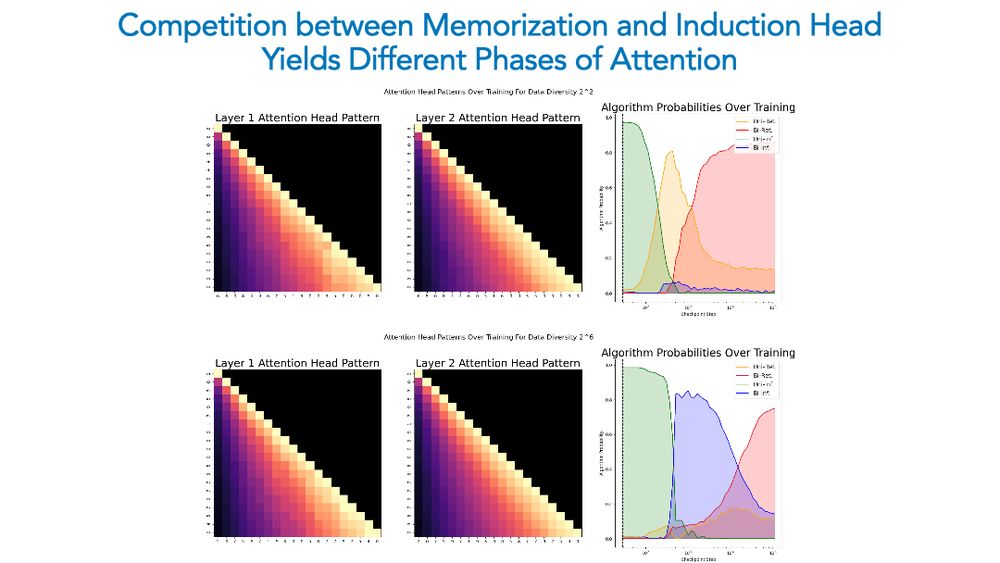
Dynamics of attention maps is particularly striking in this competition: e.g., with high diversity, we see a bigram counter forming, but memorization eventually occurs and the pattern becomes uniform! This means models can remove learned components if they are not useful anymore!
February 16, 2025 at 6:57 PM
Dynamics of attention maps is particularly striking in this competition: e.g., with high diversity, we see a bigram counter forming, but memorization eventually occurs and the pattern becomes uniform! This means models can remove learned components if they are not useful anymore!
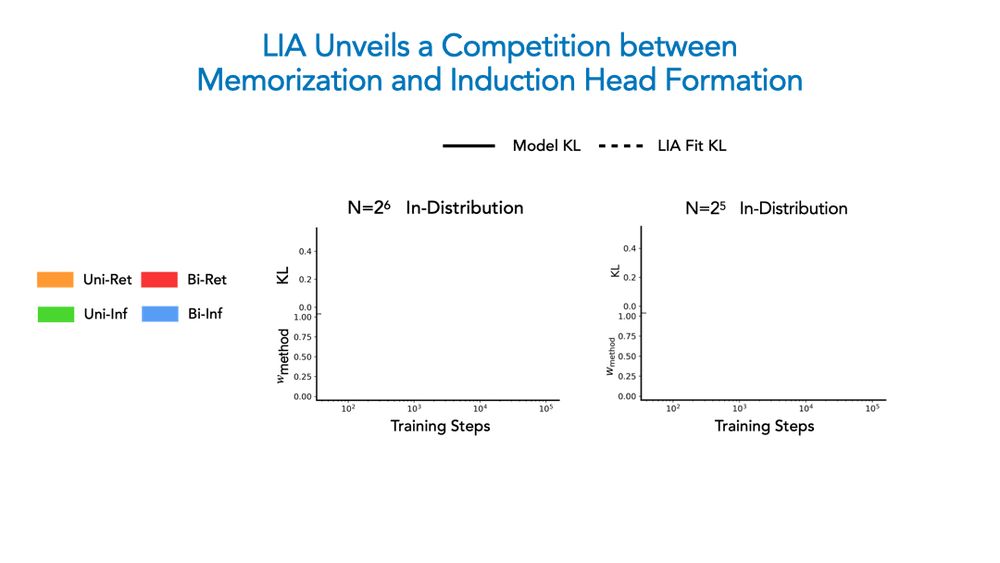
Beyond corroborating our phase diagram, LIA confirms a persistent competition underlies ICL: once the induction head forms, with enough diversity bigram-based inference takes over; under low diversity, memorization occurs faster, yielding a bigram-based retrieval solution!
February 16, 2025 at 6:57 PM
Beyond corroborating our phase diagram, LIA confirms a persistent competition underlies ICL: once the induction head forms, with enough diversity bigram-based inference takes over; under low diversity, memorization occurs faster, yielding a bigram-based retrieval solution!
Given optimization and data diversity are independent axes, we then ask if these forces race against each other to yield our observed algorithmic phases. We propose a tool called LIA (linear interpolation of algorithms) for this analysis.

February 16, 2025 at 6:57 PM
Given optimization and data diversity are independent axes, we then ask if these forces race against each other to yield our observed algorithmic phases. We propose a tool called LIA (linear interpolation of algorithms) for this analysis.
The tests check out! We see before/after a critical # of train steps are met (where induction head emerges), the model relies on unigram/bigram stats. With few chains (less diversity), there is retrieval behavior: we can literally reconstruct transition matrices from MLP neurons!

February 16, 2025 at 6:57 PM
The tests check out! We see before/after a critical # of train steps are met (where induction head emerges), the model relies on unigram/bigram stats. With few chains (less diversity), there is retrieval behavior: we can literally reconstruct transition matrices from MLP neurons!
To test the above claim, we compute the effect of shuffling a sequence on next-token probs: this breaks bigram stats, but preserves unigrams. We check how “retrieval-like” or memorization-based model behavior is by comparing predicted transitions’ KL to a random set of chains.

February 16, 2025 at 6:57 PM
To test the above claim, we compute the effect of shuffling a sequence on next-token probs: this breaks bigram stats, but preserves unigrams. We check how “retrieval-like” or memorization-based model behavior is by comparing predicted transitions’ KL to a random set of chains.
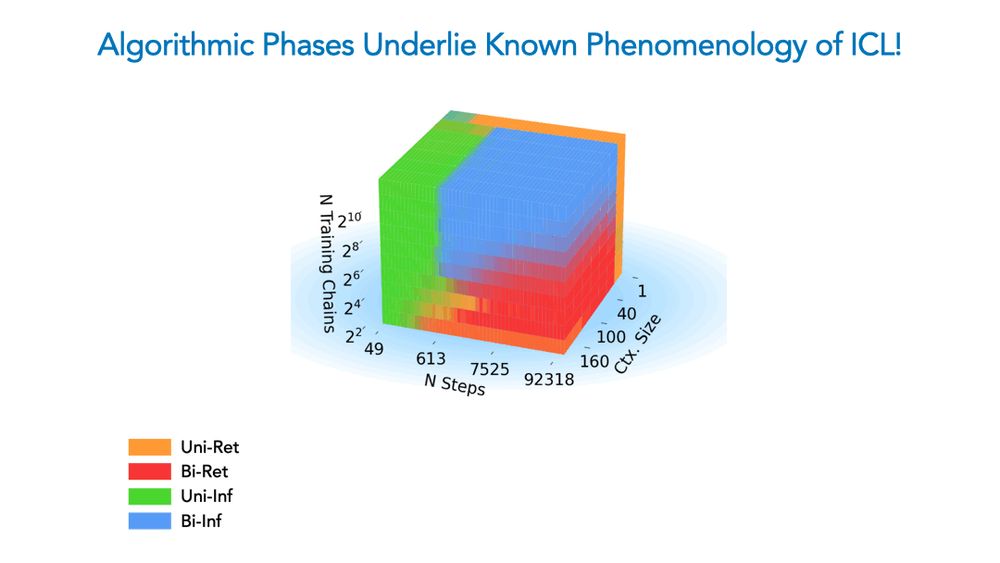
We claim four algorithms explain the model’s behavior in diff. train/test settings. These algos compute uni-/bi- gram frequency statistics of an input to either *retrieve* a memorized chain or to in-context *infer* the chain used to define the input: latter performs better OOD!

February 16, 2025 at 6:57 PM
We claim four algorithms explain the model’s behavior in diff. train/test settings. These algos compute uni-/bi- gram frequency statistics of an input to either *retrieve* a memorized chain or to in-context *infer* the chain used to define the input: latter performs better OOD!
We analyze models trained on a fairly simple task: learning to simulate a *finite mixture* of Markov chains. The sequence modeling nature of this task makes it a better abstraction for studying ICL abilities in LMs, (compared to abstractions of few-shot learning like linear reg.)

February 16, 2025 at 6:57 PM
We analyze models trained on a fairly simple task: learning to simulate a *finite mixture* of Markov chains. The sequence modeling nature of this task makes it a better abstraction for studying ICL abilities in LMs, (compared to abstractions of few-shot learning like linear reg.)
New paper–accepted as *spotlight* at #ICLR2025! 🧵👇
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
February 16, 2025 at 6:57 PM
New paper–accepted as *spotlight* at #ICLR2025! 🧵👇
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
We show a competition dynamic between several algorithms splits a toy model’s ICL abilities into four broad phases of train/test settings! This means ICL is akin to a mixture of different algorithms, not a monolithic ability.
There's never been a more exciting time to explore the science of intelligence! 🧠
What can ideas and approaches from science tell us about how AI works?
What might superhuman AI reveal about human cognition?
Join us for an internship at Harvard to explore together!
1/
What can ideas and approaches from science tell us about how AI works?
What might superhuman AI reveal about human cognition?
Join us for an internship at Harvard to explore together!
1/

February 12, 2025 at 4:30 PM
There's never been a more exciting time to explore the science of intelligence! 🧠
What can ideas and approaches from science tell us about how AI works?
What might superhuman AI reveal about human cognition?
Join us for an internship at Harvard to explore together!
1/
What can ideas and approaches from science tell us about how AI works?
What might superhuman AI reveal about human cognition?
Join us for an internship at Harvard to explore together!
1/
Overall, there's a long way to go, but I'm hopeful for the next year of SAE research and am looking forward to contributing to it!
Paper link again: arxiv.org/abs/2410.11767
And note again that paper co-lead Abhinav Menon is awesome and looking for PhD positions! Recruit him!
Paper link again: arxiv.org/abs/2410.11767
And note again that paper co-lead Abhinav Menon is awesome and looking for PhD positions! Recruit him!

December 18, 2024 at 1:45 PM
Overall, there's a long way to go, but I'm hopeful for the next year of SAE research and am looking forward to contributing to it!
Paper link again: arxiv.org/abs/2410.11767
And note again that paper co-lead Abhinav Menon is awesome and looking for PhD positions! Recruit him!
Paper link again: arxiv.org/abs/2410.11767
And note again that paper co-lead Abhinav Menon is awesome and looking for PhD positions! Recruit him!
2. We should build on ideas from disentanglement research to avoid reinventing the wheel! For ex., the community came up with really ingenious approaches to exploit "weak supervision" (kinda like self-supervision) to enable disentanglement! See paper linked in pic and our paper for a jab at this!

December 18, 2024 at 1:45 PM
2. We should build on ideas from disentanglement research to avoid reinventing the wheel! For ex., the community came up with really ingenious approaches to exploit "weak supervision" (kinda like self-supervision) to enable disentanglement! See paper linked in pic and our paper for a jab at this!
Result 3: None of the latents turn out to be causally relevant to the model's computation! E.g., intervening on a specific part-of-speech feature induces no effects of distribution of other parts in model's generations! Again, we expect this based on results from disentanglement!

December 18, 2024 at 1:45 PM
Result 3: None of the latents turn out to be causally relevant to the model's computation! E.g., intervening on a specific part-of-speech feature induces no effects of distribution of other parts in model's generations! Again, we expect this based on results from disentanglement!
Result 2: The results above are however quite brittle. Small architectural changes yield huge deviations in fraction of variance explained of the original representations! This inability / limitation of SAEs is exactly what the disentanglement community's results suggested!

December 18, 2024 at 1:45 PM
Result 2: The results above are however quite brittle. Small architectural changes yield huge deviations in fraction of variance explained of the original representations! This inability / limitation of SAEs is exactly what the disentanglement community's results suggested!
Result 1: We can find highly interpretable features in SAEs! We follow standard protocols to arrive at these results, yielding, e.g., features for parts-of-speech, counters, and depth trackers in different languages!

December 18, 2024 at 1:45 PM
Result 1: We can find highly interpretable features in SAEs! We follow standard protocols to arrive at these results, yielding, e.g., features for parts-of-speech, counters, and depth trackers in different languages!
Taking inspiration from the disentanglement literature, we first define toy settings where we know what ground-truth latents to expect: specifically, we use formal grammars like Dyck-2, Expr, and English. We pretrain models on these grammars and then train SAEs on their features!

December 18, 2024 at 1:45 PM
Taking inspiration from the disentanglement literature, we first define toy settings where we know what ground-truth latents to expect: specifically, we use formal grammars like Dyck-2, Expr, and English. We pretrain models on these grammars and then train SAEs on their features!
Interestingly, the ICML best paper winner in 2019 established an impossibility theorem for disentanglement: if the DGP is nonlinear, there are infinite solutions to the problem. Hence, identified latents will depend on what AE pipeline is used, and may not be causally relevant!

December 18, 2024 at 1:45 PM
Interestingly, the ICML best paper winner in 2019 established an impossibility theorem for disentanglement: if the DGP is nonlinear, there are infinite solutions to the problem. Hence, identified latents will depend on what AE pipeline is used, and may not be causally relevant!
In Disentanglement, one trains Autoencoders (possibly with some regularization like sparsity) to identify latents underlying the data-generating process (DGP); with SAEs, one is essentially trying to solve the same problem, but the data source is now model representations!

December 18, 2024 at 1:45 PM
In Disentanglement, one trains Autoencoders (possibly with some regularization like sparsity) to identify latents underlying the data-generating process (DGP); with SAEs, one is essentially trying to solve the same problem, but the data source is now model representations!
Paper co-led with Abhinav Menon (bsky.app/profile/bani...), who is awesome and is looking for PhD positions---recruit him!
arXiv link: arxiv.org/abs/2410.11767
arXiv link: arxiv.org/abs/2410.11767

December 18, 2024 at 1:45 PM
Paper co-led with Abhinav Menon (bsky.app/profile/bani...), who is awesome and is looking for PhD positions---recruit him!
arXiv link: arxiv.org/abs/2410.11767
arXiv link: arxiv.org/abs/2410.11767
Paper alert––*Awarded best paper* at NeurIPS workshop on Foundation Model Interventions! 🧵👇
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
December 18, 2024 at 1:45 PM
Paper alert––*Awarded best paper* at NeurIPS workshop on Foundation Model Interventions! 🧵👇
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
We analyze the (in)abilities of SAEs by relating them to the field of disentangled rep. learning, where limitations of AE based interpretability protocols have been well established!🤯
Also highlighting our previous paper in this concept learning series that this work builds on top of, and a theoretical follow up with @YongyiYang7 & @weihu_ where we find we can prove the bulk of empirical results shown above!
Previous: arxiv.org/abs/2310.09336
Follow-up: arxiv.org/abs/2410.08309
Previous: arxiv.org/abs/2310.09336
Follow-up: arxiv.org/abs/2410.08309


November 10, 2024 at 11:14 PM
Also highlighting our previous paper in this concept learning series that this work builds on top of, and a theoretical follow up with @YongyiYang7 & @weihu_ where we find we can prove the bulk of empirical results shown above!
Previous: arxiv.org/abs/2310.09336
Follow-up: arxiv.org/abs/2410.08309
Previous: arxiv.org/abs/2310.09336
Follow-up: arxiv.org/abs/2410.08309
Finally, shoutout to my amazing collaborators @corefpark, @MayaOkawa, @a_jy_l, and @Hidenori8Tanaka! This was a really fun collaboration where everybody played a very different, extremely synergistic role. :)

November 10, 2024 at 11:14 PM
Finally, shoutout to my amazing collaborators @corefpark, @MayaOkawa, @a_jy_l, and @Hidenori8Tanaka! This was a really fun collaboration where everybody played a very different, extremely synergistic role. :)
The paper contains several more results! E.g., theoretical models that capture the learning dynamics, impact of underspecification (i.e., correlated concepts), and further musings on concept signal. Check out the link below!
Link: arxiv.org/abs/2406.19370
Link: arxiv.org/abs/2406.19370


November 10, 2024 at 11:14 PM
The paper contains several more results! E.g., theoretical models that capture the learning dynamics, impact of underspecification (i.e., correlated concepts), and further musings on concept signal. Check out the link below!
Link: arxiv.org/abs/2406.19370
Link: arxiv.org/abs/2406.19370
To further corroborate this claim, we (i) train models on CelebA & (ii) experiment with pretrained StableDiffusion models. We again find latent interventions can elicit arbitrary compositions that are not present in the training data (or are unlikely to be present for SD models)!

November 10, 2024 at 11:14 PM
To further corroborate this claim, we (i) train models on CelebA & (ii) experiment with pretrained StableDiffusion models. We again find latent interventions can elicit arbitrary compositions that are not present in the training data (or are unlikely to be present for SD models)!
Despite being a toy setting, we hypothesize this result will likely hold at scale with modern generative models: there exist latent capabilities that one, via mere input prompting, is unable to elicit! This can be concerning, for such capabilities may slip through during evals!

November 10, 2024 at 11:14 PM
Despite being a toy setting, we hypothesize this result will likely hold at scale with modern generative models: there exist latent capabilities that one, via mere input prompting, is unable to elicit! This can be concerning, for such capabilities may slip through during evals!
We hypothesize the sudden turns mark *disentanglement*: the model can arbitrarily compose all concepts after this turn. But learning dynamics shows otherwise–what’s going on?!
Turns out capabilities are *latent* at this point, but can be elicited via mere linear interventions!
Turns out capabilities are *latent* at this point, but can be elicited via mere linear interventions!

November 10, 2024 at 11:14 PM
We hypothesize the sudden turns mark *disentanglement*: the model can arbitrarily compose all concepts after this turn. But learning dynamics shows otherwise–what’s going on?!
Turns out capabilities are *latent* at this point, but can be elicited via mere linear interventions!
Turns out capabilities are *latent* at this point, but can be elicited via mere linear interventions!