



Ekdeep Singh @ ICML
@ekdeepl.bsky.social
Postdoc at CBS, Harvard University
(New around here)
(New around here)
Our recent paper may be relevant (arxiv.org/abs/2506.17859)! We take a rational analysis lens to argue that beyond simplicity bias, we must model how well a hypothesis explains the data to yield a *predictive* account of behavior in neural nets! This helps explain learning of more complex functions.

In-Context Learning Strategies Emerge Rationally
Recent work analyzing in-context learning (ICL) has identified a broad set of strategies that describe model behavior in different experimental conditions. We aim to unify these findings by asking why...
arxiv.org
July 8, 2025 at 3:39 PM
Our recent paper may be relevant (arxiv.org/abs/2506.17859)! We take a rational analysis lens to argue that beyond simplicity bias, we must model how well a hypothesis explains the data to yield a *predictive* account of behavior in neural nets! This helps explain learning of more complex functions.
I am definitely not biased :)
June 28, 2025 at 4:49 AM
I am definitely not biased :)
Oh god, I had no clue this happened. :/
Does bsky not do GIFs?
Does bsky not do GIFs?
February 17, 2025 at 2:35 PM
Oh god, I had no clue this happened. :/
Does bsky not do GIFs?
Does bsky not do GIFs?
Paper co-led with @corefpark, and in collaboration with the ever-awesome @PresItamar and @Hidenori8Tanaka! :)
arXiv link: arxiv.org/abs/2412.01003
arXiv link: arxiv.org/abs/2412.01003

Competition Dynamics Shape Algorithmic Phases of In-Context Learning
In-Context Learning (ICL) has significantly expanded the general-purpose nature of large language models, allowing them to adapt to novel tasks using merely the inputted context. This has motivated a ...
arxiv.org
February 16, 2025 at 6:57 PM
Paper co-led with @corefpark, and in collaboration with the ever-awesome @PresItamar and @Hidenori8Tanaka! :)
arXiv link: arxiv.org/abs/2412.01003
arXiv link: arxiv.org/abs/2412.01003
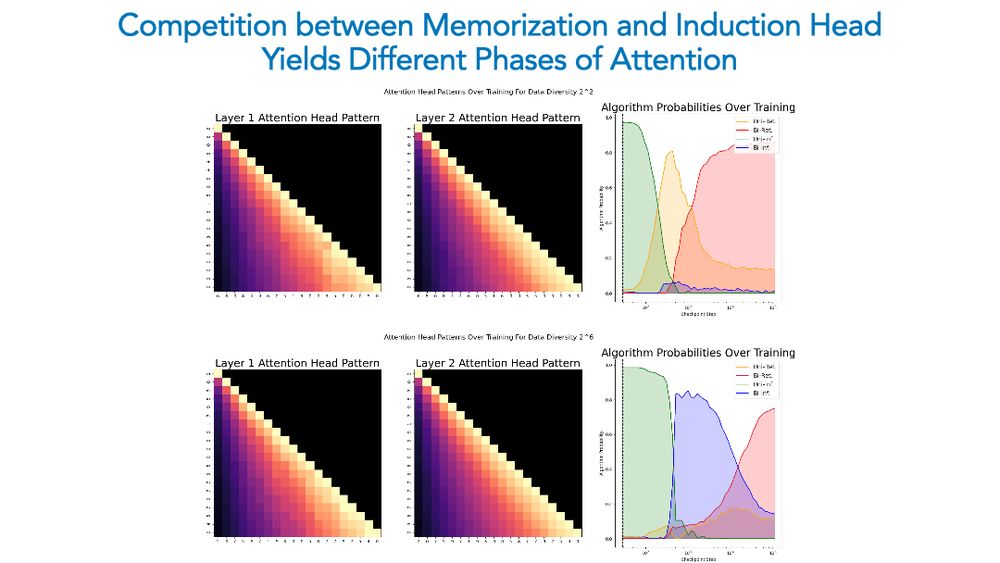
Dynamics of attention maps is particularly striking in this competition: e.g., with high diversity, we see a bigram counter forming, but memorization eventually occurs and the pattern becomes uniform! This means models can remove learned components if they are not useful anymore!
February 16, 2025 at 6:57 PM
Dynamics of attention maps is particularly striking in this competition: e.g., with high diversity, we see a bigram counter forming, but memorization eventually occurs and the pattern becomes uniform! This means models can remove learned components if they are not useful anymore!
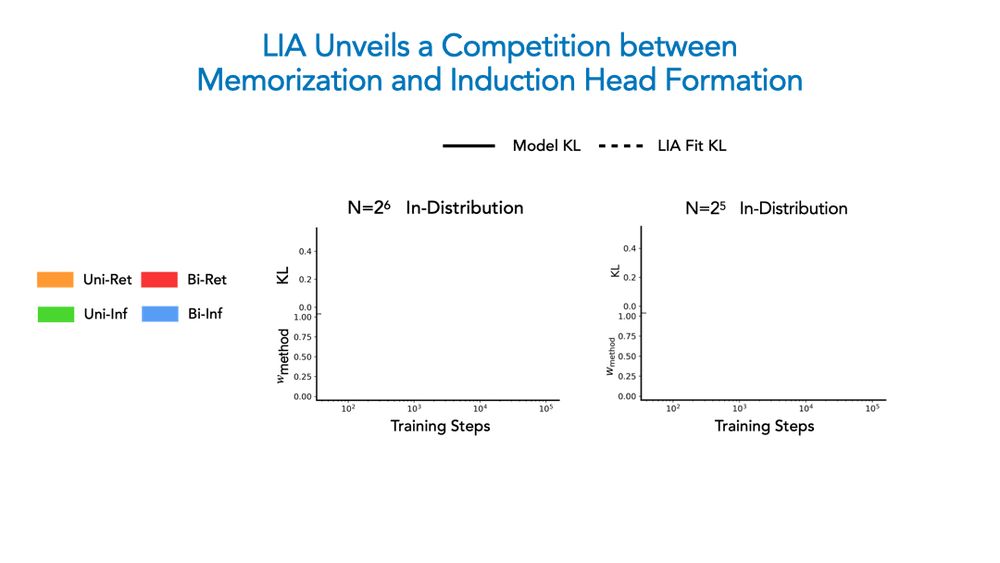
Beyond corroborating our phase diagram, LIA confirms a persistent competition underlies ICL: once the induction head forms, with enough diversity bigram-based inference takes over; under low diversity, memorization occurs faster, yielding a bigram-based retrieval solution!
February 16, 2025 at 6:57 PM
Beyond corroborating our phase diagram, LIA confirms a persistent competition underlies ICL: once the induction head forms, with enough diversity bigram-based inference takes over; under low diversity, memorization occurs faster, yielding a bigram-based retrieval solution!
Given optimization and data diversity are independent axes, we then ask if these forces race against each other to yield our observed algorithmic phases. We propose a tool called LIA (linear interpolation of algorithms) for this analysis.

February 16, 2025 at 6:57 PM
Given optimization and data diversity are independent axes, we then ask if these forces race against each other to yield our observed algorithmic phases. We propose a tool called LIA (linear interpolation of algorithms) for this analysis.
The tests check out! We see before/after a critical # of train steps are met (where induction head emerges), the model relies on unigram/bigram stats. With few chains (less diversity), there is retrieval behavior: we can literally reconstruct transition matrices from MLP neurons!

February 16, 2025 at 6:57 PM
The tests check out! We see before/after a critical # of train steps are met (where induction head emerges), the model relies on unigram/bigram stats. With few chains (less diversity), there is retrieval behavior: we can literally reconstruct transition matrices from MLP neurons!
To test the above claim, we compute the effect of shuffling a sequence on next-token probs: this breaks bigram stats, but preserves unigrams. We check how “retrieval-like” or memorization-based model behavior is by comparing predicted transitions’ KL to a random set of chains.

February 16, 2025 at 6:57 PM
To test the above claim, we compute the effect of shuffling a sequence on next-token probs: this breaks bigram stats, but preserves unigrams. We check how “retrieval-like” or memorization-based model behavior is by comparing predicted transitions’ KL to a random set of chains.
We claim four algorithms explain the model’s behavior in diff. train/test settings. These algos compute uni-/bi- gram frequency statistics of an input to either *retrieve* a memorized chain or to in-context *infer* the chain used to define the input: latter performs better OOD!

February 16, 2025 at 6:57 PM
We claim four algorithms explain the model’s behavior in diff. train/test settings. These algos compute uni-/bi- gram frequency statistics of an input to either *retrieve* a memorized chain or to in-context *infer* the chain used to define the input: latter performs better OOD!
We analyze models trained on a fairly simple task: learning to simulate a *finite mixture* of Markov chains. The sequence modeling nature of this task makes it a better abstraction for studying ICL abilities in LMs, (compared to abstractions of few-shot learning like linear reg.)

February 16, 2025 at 6:57 PM
We analyze models trained on a fairly simple task: learning to simulate a *finite mixture* of Markov chains. The sequence modeling nature of this task makes it a better abstraction for studying ICL abilities in LMs, (compared to abstractions of few-shot learning like linear reg.)

New paper <3
Interested in inference-time scaling? In-context Learning? Mech Interp?
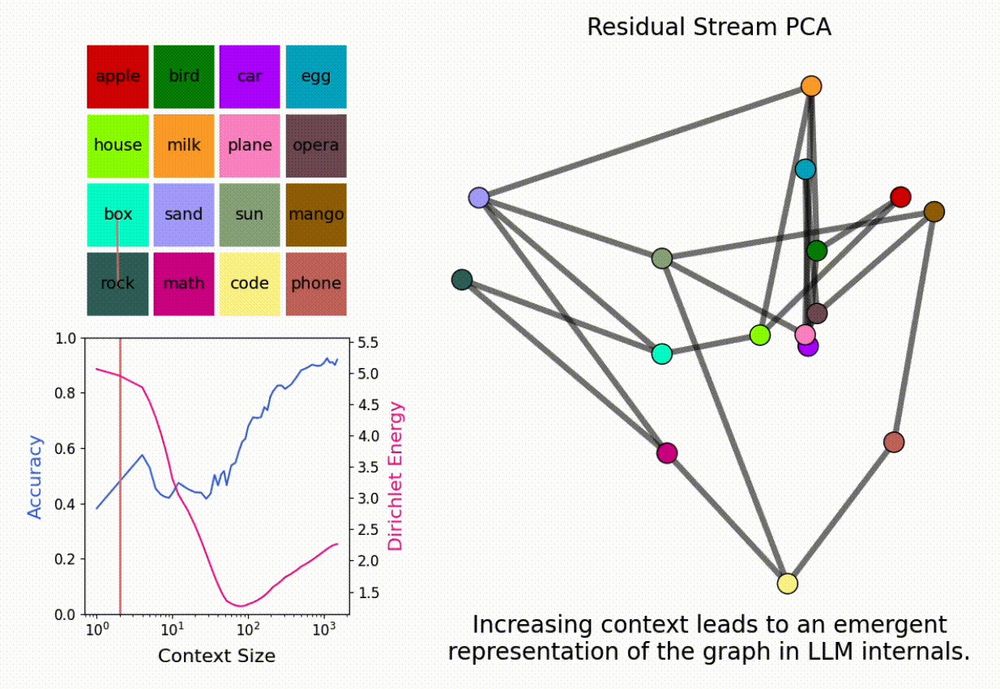
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
Interested in inference-time scaling? In-context Learning? Mech Interp?
LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bc they dynamically form *in-context representations*!
1/N
February 12, 2025 at 4:30 PM
Paper alert—accepted as a *Spotlight* at NeurIPS!🧵
Building on our work relating emergent abilities to task compositionality, we analyze the *learning dynamics* of compositional abilities & find there exist latent interventions that can elicit them much before input prompting works! 🤯
Building on our work relating emergent abilities to task compositionality, we analyze the *learning dynamics* of compositional abilities & find there exist latent interventions that can elicit them much before input prompting works! 🤯

February 12, 2025 at 4:30 PM
Our group, funded by NTT Research, Inc., uniquely bridges industry and academia. We integrate approaches from physics, neuroscience, and psychology while grounding our work in empirical AI research.
Apply from "Physics of AI Group Research Intern": careers.ntt-research.com
Apply from "Physics of AI Group Research Intern": careers.ntt-research.com
CareerPortal
careers.ntt-research.com
February 12, 2025 at 4:30 PM
Our group, funded by NTT Research, Inc., uniquely bridges industry and academia. We integrate approaches from physics, neuroscience, and psychology while grounding our work in empirical AI research.
Apply from "Physics of AI Group Research Intern": careers.ntt-research.com
Apply from "Physics of AI Group Research Intern": careers.ntt-research.com
Check out our recent work, including 5 ICLR 2025 papers all (co)led by amazing past and current interns: sites.google.com/view/htanaka...

Hidenori Tanaka
Hidenori Tanaka
Group Leader, Science of Intelligence for Alignment
CBS-NTT Program in Physics of Intelligence, Harvard University
Google Scholar
email: hidenori_tanaka [at] fas.harvard.edu, twitter
...
sites.google.com
February 12, 2025 at 4:30 PM
Check out our recent work, including 5 ICLR 2025 papers all (co)led by amazing past and current interns: sites.google.com/view/htanaka...