



Stefan Baumann
@stefanabaumann.bsky.social
PhD Student at @compvis.bsky.social & @ellis.eu working on generative computer vision.
Interested in extracting world understanding from models and more controlled generation. 🌐 https://stefan-baumann.eu/
Interested in extracting world understanding from models and more controlled generation. 🌐 https://stefan-baumann.eu/
Pinned

🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
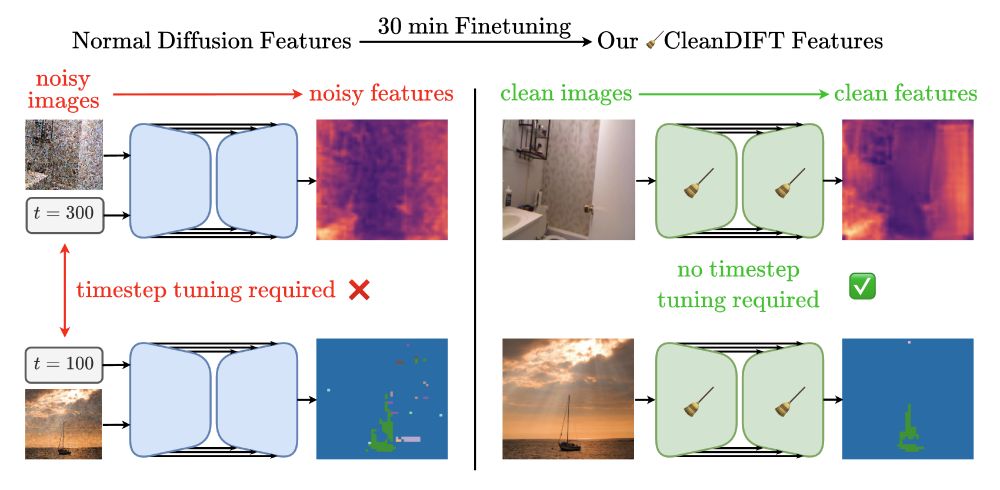
Ever wondered if diffusion features could do better without all the noise? 🤔
Turns out they can! We show how adapting the backbone unlocks clean, powerful features for better results across the board. 🚀🧹
Check it out! ⬇️
Turns out they can! We show how adapting the backbone unlocks clean, powerful features for better results across the board. 🚀🧹
Check it out! ⬇️
Reposted by Stefan Baumann

Excited to share that we'll be presenting four papers at the main conference at ICCV 2025 this week!
Come say hi in Honolulu!
👋 Pingchuan, Ming, Felix, Stefan, Timy, and Björn Ommer will be attending.
Come say hi in Honolulu!
👋 Pingchuan, Ming, Felix, Stefan, Timy, and Björn Ommer will be attending.

October 19, 2025 at 6:06 PM
Excited to share that we'll be presenting four papers at the main conference at ICCV 2025 this week!
Come say hi in Honolulu!
👋 Pingchuan, Ming, Felix, Stefan, Timy, and Björn Ommer will be attending.
Come say hi in Honolulu!
👋 Pingchuan, Ming, Felix, Stefan, Timy, and Björn Ommer will be attending.
Reposted by Stefan Baumann

🤔 What if you could generate an entire image using just one continuous token?
💡 It works if we leverage a self-supervised representation!
Meet RepTok🦎: A generative model that encodes an image into a single continuous latent while keeping realism and semantics. 🧵 👇
💡 It works if we leverage a self-supervised representation!
Meet RepTok🦎: A generative model that encodes an image into a single continuous latent while keeping realism and semantics. 🧵 👇

October 17, 2025 at 10:21 AM
🤔 What if you could generate an entire image using just one continuous token?
💡 It works if we leverage a self-supervised representation!
Meet RepTok🦎: A generative model that encodes an image into a single continuous latent while keeping realism and semantics. 🧵 👇
💡 It works if we leverage a self-supervised representation!
Meet RepTok🦎: A generative model that encodes an image into a single continuous latent while keeping realism and semantics. 🧵 👇
🤔 What happens when you poke a scene — and your model has to predict how the world moves in response?
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇

October 15, 2025 at 1:56 AM
🤔 What happens when you poke a scene — and your model has to predict how the world moves in response?
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇
Reposted by Stefan Baumann

“Everyone knows” what an autoencoder is… but there's an important complementary picture missing from most introductory material.
In short: we emphasize how autoencoders are implemented—but not always what they represent (and some of the implications of that representation).🧵
In short: we emphasize how autoencoders are implemented—but not always what they represent (and some of the implications of that representation).🧵

September 6, 2025 at 9:20 PM
“Everyone knows” what an autoencoder is… but there's an important complementary picture missing from most introductory material.
In short: we emphasize how autoencoders are implemented—but not always what they represent (and some of the implications of that representation).🧵
In short: we emphasize how autoencoders are implemented—but not always what they represent (and some of the implications of that representation).🧵
I'm calling it now, GSPO will be the next big hype in LLM RL algos after GRPO.
It makes so much more sense intuitively to work on a sequence rather than on a token level when our rewards are on a sequence level.
It makes so much more sense intuitively to work on a sequence rather than on a token level when our rewards are on a sequence level.

July 26, 2025 at 7:41 PM
I'm calling it now, GSPO will be the next big hype in LLM RL algos after GRPO.
It makes so much more sense intuitively to work on a sequence rather than on a token level when our rewards are on a sequence level.
It makes so much more sense intuitively to work on a sequence rather than on a token level when our rewards are on a sequence level.
Reposted by Stefan Baumann
🎉 Excited to share that our lab has three papers accepted at CVPR 2025!
Come say hi in Nashville!
👋 Johannes, Ming, Kolja, Stefan, and Björn will be attending.
Come say hi in Nashville!
👋 Johannes, Ming, Kolja, Stefan, and Björn will be attending.

June 9, 2025 at 7:28 AM
🎉 Excited to share that our lab has three papers accepted at CVPR 2025!
Come say hi in Nashville!
👋 Johannes, Ming, Kolja, Stefan, and Björn will be attending.
Come say hi in Nashville!
👋 Johannes, Ming, Kolja, Stefan, and Björn will be attending.
Reposted by Stefan Baumann
If you are interested, feel free to check the paper (arxiv.org/abs/2506.02221) or come by at CVPR:
📌 Poster Session 6, Sunday 4:00 to 6:00 PM, Poster #208
📌 Poster Session 6, Sunday 4:00 to 6:00 PM, Poster #208

Diff2Flow: Training Flow Matching Models via Diffusion Model Alignment
Diffusion models have revolutionized generative tasks through high-fidelity outputs, yet flow matching (FM) offers faster inference and empirical performance gains. However, current foundation FM mode...
arxiv.org
June 6, 2025 at 3:48 PM
If you are interested, feel free to check the paper (arxiv.org/abs/2506.02221) or come by at CVPR:
📌 Poster Session 6, Sunday 4:00 to 6:00 PM, Poster #208
📌 Poster Session 6, Sunday 4:00 to 6:00 PM, Poster #208
Reposted by Stefan Baumann

Here's the third and final part of Slater Stich's "History of diffusion" interview series!
The other two interviewees' research played a pivotal role in the rise of diffusion models, whereas I just like to yap about them 😬 this was a wonderful opportunity to do exactly that!
The other two interviewees' research played a pivotal role in the rise of diffusion models, whereas I just like to yap about them 😬 this was a wonderful opportunity to do exactly that!

History of Diffusion - Sander Dieleman
YouTube video by Bain Capital Ventures
www.youtube.com
May 14, 2025 at 4:11 PM
Here's the third and final part of Slater Stich's "History of diffusion" interview series!
The other two interviewees' research played a pivotal role in the rise of diffusion models, whereas I just like to yap about them 😬 this was a wonderful opportunity to do exactly that!
The other two interviewees' research played a pivotal role in the rise of diffusion models, whereas I just like to yap about them 😬 this was a wonderful opportunity to do exactly that!
Reposted by Stefan Baumann

#KostasThoughts: Another major conference review drop is around the corner. In baseball, a .300 average is elite. In research, it’s a familiar reality: submitting to top conferences means rejections happen. Keep swinging!
May 7, 2025 at 6:16 PM
#KostasThoughts: Another major conference review drop is around the corner. In baseball, a .300 average is elite. In research, it’s a familiar reality: submitting to top conferences means rejections happen. Keep swinging!
Reposted by Stefan Baumann

I am very happy to share our latest work on the information theory of generative diffusion:
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
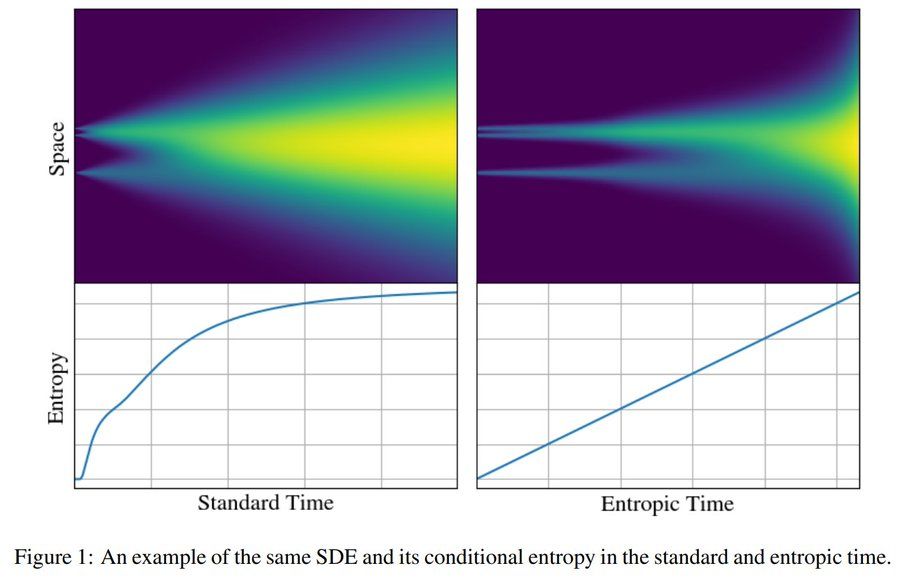
April 29, 2025 at 1:17 PM
I am very happy to share our latest work on the information theory of generative diffusion:
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
"Entropic Time Schedulers for Generative Diffusion Models"
We find that the conditional entropy offers a natural data-dependent notion of time during generation
Link: arxiv.org/abs/2504.13612
Reposted by Stefan Baumann
New blog post: let's talk about latents!
sander.ai/2025/04/15/l...
sander.ai/2025/04/15/l...

Generative modelling in latent space
Latent representations for generative models.
sander.ai
April 15, 2025 at 9:40 AM
New blog post: let's talk about latents!
sander.ai/2025/04/15/l...
sander.ai/2025/04/15/l...
Reposted by Stefan Baumann

And the CVPR oral decisions are out! (on Openreview)
April 4, 2025 at 3:25 PM
And the CVPR oral decisions are out! (on Openreview)
Reposted by Stefan Baumann

Introducing VGGT (CVPR'25), a feedforward Transformer that directly infers all key 3D attributes from one, a few, or hundreds of images, in seconds!
Project Page: vgg-t.github.io
Code & Weights: github.com/facebookrese...
Project Page: vgg-t.github.io
Code & Weights: github.com/facebookrese...
March 17, 2025 at 2:08 AM
Introducing VGGT (CVPR'25), a feedforward Transformer that directly infers all key 3D attributes from one, a few, or hundreds of images, in seconds!
Project Page: vgg-t.github.io
Code & Weights: github.com/facebookrese...
Project Page: vgg-t.github.io
Code & Weights: github.com/facebookrese...
Reposted by Stefan Baumann

Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
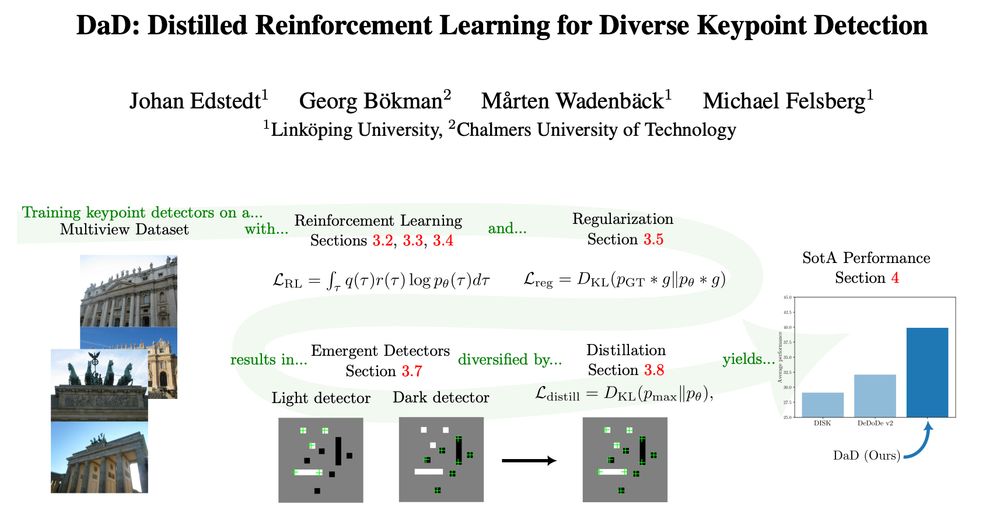
March 11, 2025 at 3:05 AM
Introducing DaD (arxiv.org/abs/2503.07347), a pretty cool keypoint detector.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.
As this will get pretty long, this will be two threads.
The first will go into the RL part, and the second on the emergence and distillation.

Reposted by Stefan Baumann

🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
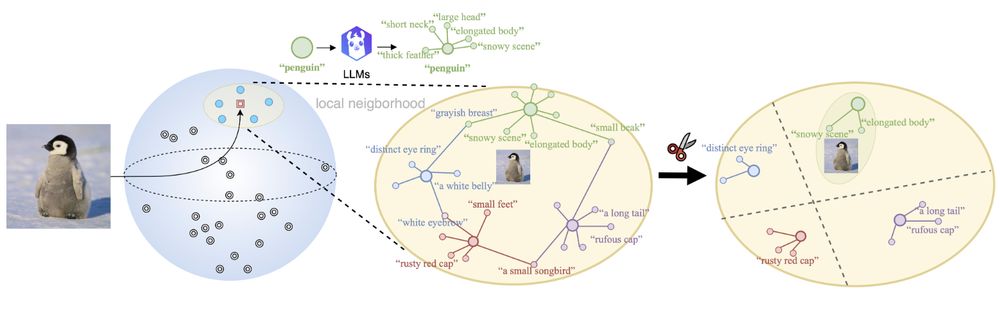
January 8, 2025 at 3:54 PM
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
Reposted by Stefan Baumann

What I like to do when considering a new dataset is to train a simple classifier and look at 'the most confident errors'.
Recently with NICO: Apart from a class, the images have a context, one of them is 'autumn'. There is also a pumpkin class. Surprise surprise, many autumn images contain pumpkins.
Recently with NICO: Apart from a class, the images have a context, one of them is 'autumn'. There is also a pumpkin class. Surprise surprise, many autumn images contain pumpkins.

December 10, 2024 at 7:02 PM
What I like to do when considering a new dataset is to train a simple classifier and look at 'the most confident errors'.
Recently with NICO: Apart from a class, the images have a context, one of them is 'autumn'. There is also a pumpkin class. Surprise surprise, many autumn images contain pumpkins.
Recently with NICO: Apart from a class, the images have a context, one of them is 'autumn'. There is also a pumpkin class. Surprise surprise, many autumn images contain pumpkins.
Reposted by Stefan Baumann


Reposted by Stefan Baumann

How to schedule a meeting?
When you ask for a meeting with others, you are asking for their time. You are asking for their most valuable, finite resource to benefit yourself (e.g., for advice, networking, questions, and opportunities).
Here are some tips that I found useful.
When you ask for a meeting with others, you are asking for their time. You are asking for their most valuable, finite resource to benefit yourself (e.g., for advice, networking, questions, and opportunities).
Here are some tips that I found useful.
December 10, 2024 at 12:02 AM
How to schedule a meeting?
When you ask for a meeting with others, you are asking for their time. You are asking for their most valuable, finite resource to benefit yourself (e.g., for advice, networking, questions, and opportunities).
Here are some tips that I found useful.
When you ask for a meeting with others, you are asking for their time. You are asking for their most valuable, finite resource to benefit yourself (e.g., for advice, networking, questions, and opportunities).
Here are some tips that I found useful.
Do you like the power of diffusion features for semantic correspondence but dread running an expensive ~1B model to get them?
What if you could have even better features at a fraction of the cost? If this sounds enticing, take a look at this paper! ⬇️
What if you could have even better features at a fraction of the cost? If this sounds enticing, take a look at this paper! ⬇️

Did you know you can distill the capabilities of a large diffusion model into a small ViT? ⚗️
We showed exactly that for a fundamental task:
semantic correspondence📍
A thread 🧵👇
We showed exactly that for a fundamental task:
semantic correspondence📍
A thread 🧵👇
December 6, 2024 at 4:36 PM
Do you like the power of diffusion features for semantic correspondence but dread running an expensive ~1B model to get them?
What if you could have even better features at a fraction of the cost? If this sounds enticing, take a look at this paper! ⬇️
What if you could have even better features at a fraction of the cost? If this sounds enticing, take a look at this paper! ⬇️
Ever wondered if diffusion features could do better without all the noise? 🤔
Turns out they can! We show how adapting the backbone unlocks clean, powerful features for better results across the board. 🚀🧹
Check it out! ⬇️
Turns out they can! We show how adapting the backbone unlocks clean, powerful features for better results across the board. 🚀🧹
Check it out! ⬇️
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
December 4, 2024 at 11:47 PM
Ever wondered if diffusion features could do better without all the noise? 🤔
Turns out they can! We show how adapting the backbone unlocks clean, powerful features for better results across the board. 🚀🧹
Check it out! ⬇️
Turns out they can! We show how adapting the backbone unlocks clean, powerful features for better results across the board. 🚀🧹
Check it out! ⬇️
Reposted by Stefan Baumann

Blog post link: diffusionflow.github.io/
Despite seeming similar, there is some confusion in the community about the exact connection between the two frameworks. We aim to clear up the confusion by showing how to convert one framework to another, for both training and sampling.
Despite seeming similar, there is some confusion in the community about the exact connection between the two frameworks. We aim to clear up the confusion by showing how to convert one framework to another, for both training and sampling.
Diffusion Meets Flow Matching
Flow matching and diffusion models are two popular frameworks in generative modeling. Despite seeming similar, there is some confusion in the community about their exact connection. In this post, we a...
diffusionflow.github.io
December 2, 2024 at 6:45 PM
Blog post link: diffusionflow.github.io/
Despite seeming similar, there is some confusion in the community about the exact connection between the two frameworks. We aim to clear up the confusion by showing how to convert one framework to another, for both training and sampling.
Despite seeming similar, there is some confusion in the community about the exact connection between the two frameworks. We aim to clear up the confusion by showing how to convert one framework to another, for both training and sampling.
Reposted by Stefan Baumann

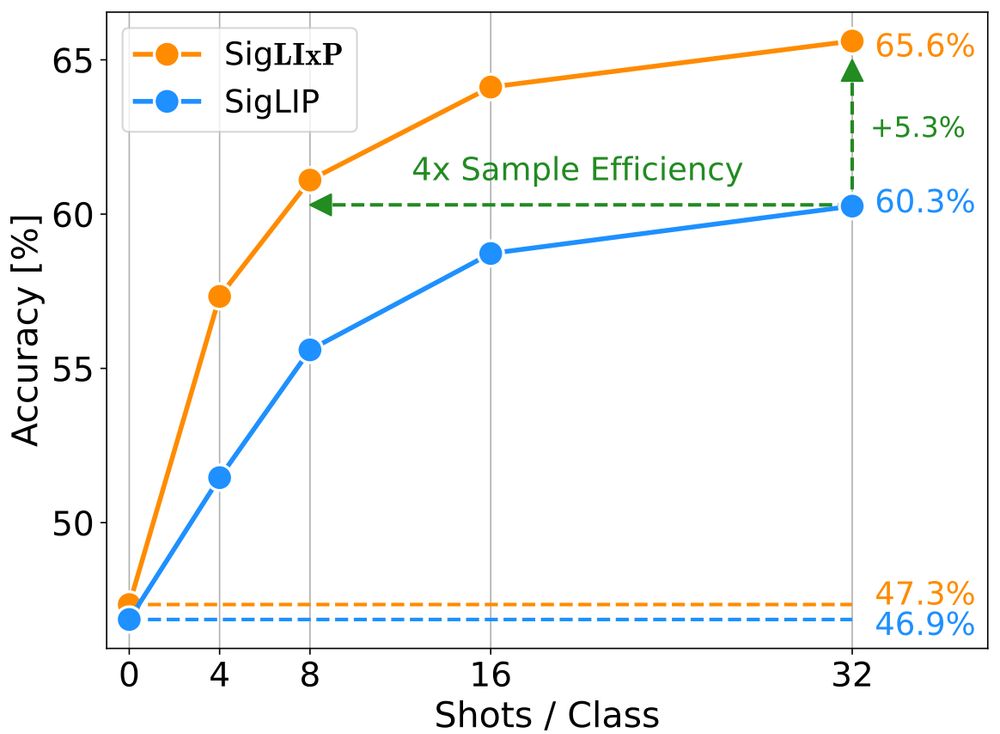
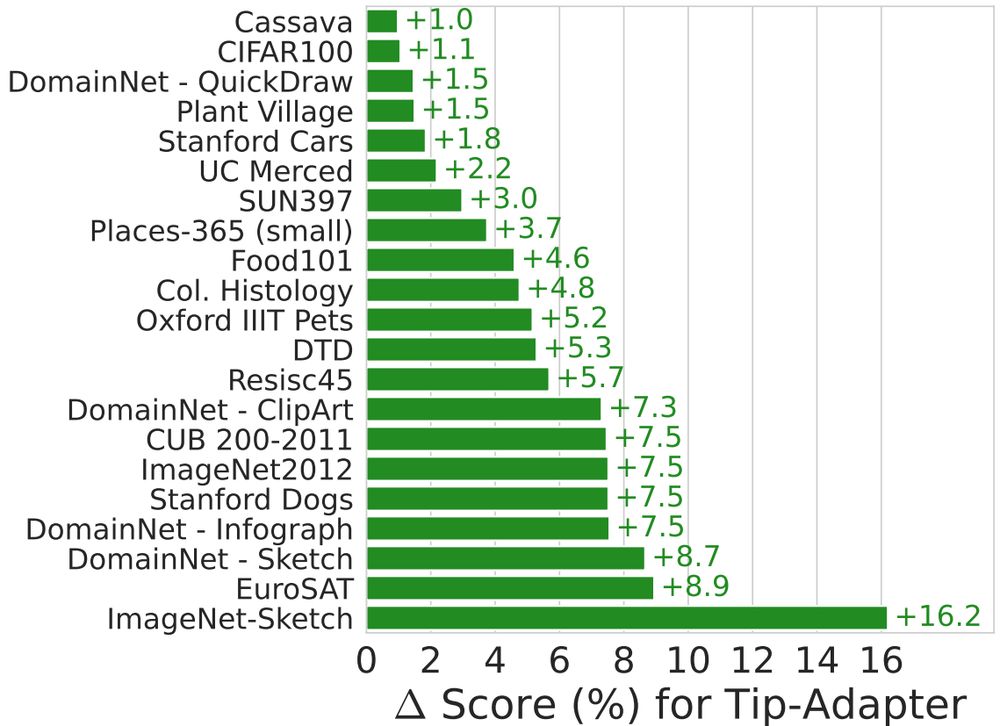
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:

November 28, 2024 at 2:33 PM
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Reposted by Stefan Baumann

Our group at Google DeepMind is now accepting intern applications for summer 2025. Attached is the official "call for interns" email; the links and email aliases that got lost in the screenshot are below.

November 25, 2024 at 9:55 PM
Our group at Google DeepMind is now accepting intern applications for summer 2025. Attached is the official "call for interns" email; the links and email aliases that got lost in the screenshot are below.
Reposted by Stefan Baumann

The ✨ML Internship Feed✨ is here!
@serge.belongie.com and I created this feed to compile internship opportunities in AI, ML, CV, NLP, and related areas.
The feed is rule-based. Please help us improve the rules by sharing feedback 🧡
🔗 Link to the feed: bsky.app/profile/did:...
@serge.belongie.com and I created this feed to compile internship opportunities in AI, ML, CV, NLP, and related areas.
The feed is rule-based. Please help us improve the rules by sharing feedback 🧡
🔗 Link to the feed: bsky.app/profile/did:...
November 22, 2024 at 9:46 PM
The ✨ML Internship Feed✨ is here!
@serge.belongie.com and I created this feed to compile internship opportunities in AI, ML, CV, NLP, and related areas.
The feed is rule-based. Please help us improve the rules by sharing feedback 🧡
🔗 Link to the feed: bsky.app/profile/did:...
@serge.belongie.com and I created this feed to compile internship opportunities in AI, ML, CV, NLP, and related areas.
The feed is rule-based. Please help us improve the rules by sharing feedback 🧡
🔗 Link to the feed: bsky.app/profile/did:...