



Jon Barron
@jonbarron.bsky.social
Principal research scientist at Google DeepMind. Synthesized views are my own.
📍SF Bay Area 🔗 http://jonbarron.info
This feed is a mostly-incomplete mirror of https://x.com/jon_barron, I recommend you just follow me there.
📍SF Bay Area 🔗 http://jonbarron.info
This feed is a mostly-incomplete mirror of https://x.com/jon_barron, I recommend you just follow me there.
Pinned
Jon Barron
@jonbarron.bsky.social
· Apr 28

Radiance Fields and the Future of Generative Media
YouTube video by Jon Barron
www.youtube.com
Here's a recording of my 3DV keynote from a couple weeks ago. If you're already familiar with my research, I recommend skipping to ~22 minutes in where I get to the fun stuff (whether or not 3D has been bitter-lesson'ed by video generation models)
www.youtube.com/watch?v=hFlF...
www.youtube.com/watch?v=hFlF...
Reposted by Jon Barron

Radiance Meshes for Volumetric Reconstruction
Alexander Mai, Trevor Hedstrom, @grgkopanas.bsky.social, Janne Kontkanen, Falko Kuester, @jonbarron.bsky.social
tl;dr: Delaunay tetrahedralization->constant density and linear color radian->radiance mesh->radiance field
arxiv.org/abs/2512.04076
Alexander Mai, Trevor Hedstrom, @grgkopanas.bsky.social, Janne Kontkanen, Falko Kuester, @jonbarron.bsky.social
tl;dr: Delaunay tetrahedralization->constant density and linear color radian->radiance mesh->radiance field
arxiv.org/abs/2512.04076




December 4, 2025 at 12:02 PM
Radiance Meshes for Volumetric Reconstruction
Alexander Mai, Trevor Hedstrom, @grgkopanas.bsky.social, Janne Kontkanen, Falko Kuester, @jonbarron.bsky.social
tl;dr: Delaunay tetrahedralization->constant density and linear color radian->radiance mesh->radiance field
arxiv.org/abs/2512.04076
Alexander Mai, Trevor Hedstrom, @grgkopanas.bsky.social, Janne Kontkanen, Falko Kuester, @jonbarron.bsky.social
tl;dr: Delaunay tetrahedralization->constant density and linear color radian->radiance mesh->radiance field
arxiv.org/abs/2512.04076
Reposted by Jon Barron

Is basic image understanding solved in today’s SOTA VLMs? Not quite.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.

September 8, 2025 at 3:28 PM
Is basic image understanding solved in today’s SOTA VLMs? Not quite.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.
Reposted by Jon Barron

Here’s what I’ve been working on for the past year. This is SkyTour, a 3D exterior tour utilizing Gaussian Splat. The UX is in the modeling of the “flight path.” I led the prototyping team that built the first POC. I was the sole designer and researcher on the project, one of the 1st inventors.
July 16, 2025 at 3:43 AM
Here’s what I’ve been working on for the past year. This is SkyTour, a 3D exterior tour utilizing Gaussian Splat. The UX is in the modeling of the “flight path.” I led the prototyping team that built the first POC. I was the sole designer and researcher on the project, one of the 1st inventors.
Reposted by Jon Barron

🚀🚀🚀Announcing our $13M funding round to build the next generation of AI: 𝐒𝐩𝐚𝐭𝐢𝐚𝐥 𝐅𝐨𝐮𝐧𝐝𝐚𝐭𝐢𝐨𝐧 𝐌𝐨𝐝𝐞𝐥𝐬 that can generate entire 3D environments anchored in space & time. 🚀🚀🚀
Interested? Join our world-class team:
🌍 spaitial.ai
youtu.be/FiGX82RUz8U
Interested? Join our world-class team:
🌍 spaitial.ai
youtu.be/FiGX82RUz8U

SpAItial AI: Building Spatial Foundation Models
YouTube video by SpAItial AI
youtu.be
May 27, 2025 at 9:26 AM
🚀🚀🚀Announcing our $13M funding round to build the next generation of AI: 𝐒𝐩𝐚𝐭𝐢𝐚𝐥 𝐅𝐨𝐮𝐧𝐝𝐚𝐭𝐢𝐨𝐧 𝐌𝐨𝐝𝐞𝐥𝐬 that can generate entire 3D environments anchored in space & time. 🚀🚀🚀
Interested? Join our world-class team:
🌍 spaitial.ai
youtu.be/FiGX82RUz8U
Interested? Join our world-class team:
🌍 spaitial.ai
youtu.be/FiGX82RUz8U
Reposted by Jon Barron

📺 Now available: Watch the recording of Aaron Hertzmann's talk, "Can Computers Create Art?" www.youtube.com/watch?v=40CB...
@uoftartsci.bsky.social
@uoftartsci.bsky.social
April 30, 2025 at 8:23 PM
📺 Now available: Watch the recording of Aaron Hertzmann's talk, "Can Computers Create Art?" www.youtube.com/watch?v=40CB...
@uoftartsci.bsky.social
@uoftartsci.bsky.social
Here's a recording of my 3DV keynote from a couple weeks ago. If you're already familiar with my research, I recommend skipping to ~22 minutes in where I get to the fun stuff (whether or not 3D has been bitter-lesson'ed by video generation models)
www.youtube.com/watch?v=hFlF...
www.youtube.com/watch?v=hFlF...
Radiance Fields and the Future of Generative Media
YouTube video by Jon Barron
www.youtube.com
April 28, 2025 at 8:52 PM
Here's a recording of my 3DV keynote from a couple weeks ago. If you're already familiar with my research, I recommend skipping to ~22 minutes in where I get to the fun stuff (whether or not 3D has been bitter-lesson'ed by video generation models)
www.youtube.com/watch?v=hFlF...
www.youtube.com/watch?v=hFlF...
A thread of thoughts on radiance fields, from my keynote at 3DV:
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.

April 8, 2025 at 5:25 PM
A thread of thoughts on radiance fields, from my keynote at 3DV:
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.
Here's Bolt3D: fast feed-forward 3D generation from one or many input images. Diffusion means that generated scenes contain lots of interesting structure in unobserved regions. ~6 seconds to generate, renders in real time.
Project page: szymanowiczs.github.io/bolt3d
Arxiv: arxiv.org/abs/2503.14445
Project page: szymanowiczs.github.io/bolt3d
Arxiv: arxiv.org/abs/2503.14445
March 19, 2025 at 6:37 PM
Here's Bolt3D: fast feed-forward 3D generation from one or many input images. Diffusion means that generated scenes contain lots of interesting structure in unobserved regions. ~6 seconds to generate, renders in real time.
Project page: szymanowiczs.github.io/bolt3d
Arxiv: arxiv.org/abs/2503.14445
Project page: szymanowiczs.github.io/bolt3d
Arxiv: arxiv.org/abs/2503.14445
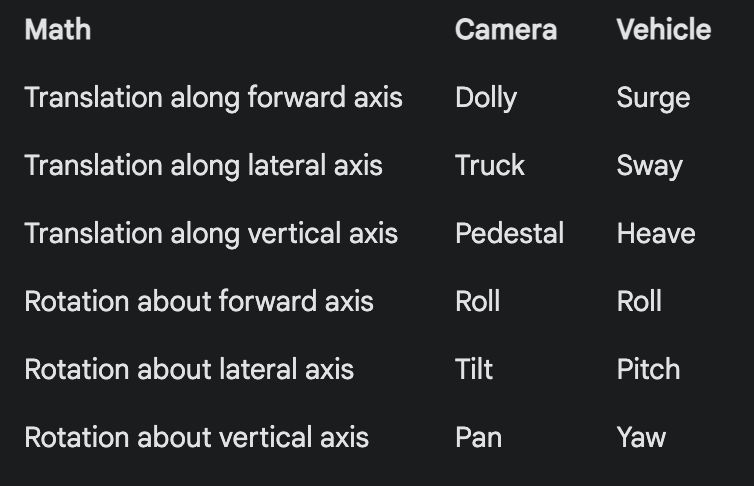
I made this handy cheat sheet for the jargon that 6DOF math maps to for cameras and vehicles. Worth learning if you, like me, are worried about embarrassing yourself in front of a cinematographer or naval admiral.
March 19, 2025 at 4:50 PM
I made this handy cheat sheet for the jargon that 6DOF math maps to for cameras and vehicles. Worth learning if you, like me, are worried about embarrassing yourself in front of a cinematographer or naval admiral.
Can someone point me to a video of renderings of some 3DGS-like algorithm *as it is being optimized*? I want to see all those little Gaussians wobbling around.
February 24, 2025 at 11:07 PM
Can someone point me to a video of renderings of some 3DGS-like algorithm *as it is being optimized*? I want to see all those little Gaussians wobbling around.
Next week is the one year anniversary of this paper showing that videos generated from Sora are nearly 3D-consistent. I'm surprised we never saw any follow-up papers in this line evaluating other videos models this way, it would be helpful to track these metrics over time. arxiv.org/abs/2402.17403

February 23, 2025 at 6:37 PM
Next week is the one year anniversary of this paper showing that videos generated from Sora are nearly 3D-consistent. I'm surprised we never saw any follow-up papers in this line evaluating other videos models this way, it would be helpful to track these metrics over time. arxiv.org/abs/2402.17403
Veo 2 now has a public price point: $0.50 per second. Very important number to keep in mind when considering the future of generative and non-generative media. Taken from cloud.google.com/vertex-ai/ge...

February 22, 2025 at 6:52 PM
Veo 2 now has a public price point: $0.50 per second. Very important number to keep in mind when considering the future of generative and non-generative media. Taken from cloud.google.com/vertex-ai/ge...
Reposted by Jon Barron


I just pushed a new paper to arXiv. I realized that a lot of my previous work on robust losses and nerf-y things was dancing around something simpler: a slight tweak to the classic Box-Cox power transform that makes it much more useful and stable. It's this f(x, λ) here:
February 18, 2025 at 6:43 PM
I just pushed a new paper to arXiv. I realized that a lot of my previous work on robust losses and nerf-y things was dancing around something simpler: a slight tweak to the classic Box-Cox power transform that makes it much more useful and stable. It's this f(x, λ) here:
My pitch for an "LLM-native" alternative to citation count/h-index etc:
1) Train an LLM on a new paper and record the average loss during training.
2) Evaluate the retrained LLM on benchmarks.
Your Google Scholar records avg_train_loss * benchmark_delta, and you go write your next paper.
1) Train an LLM on a new paper and record the average loss during training.
2) Evaluate the retrained LLM on benchmarks.
Your Google Scholar records avg_train_loss * benchmark_delta, and you go write your next paper.
February 12, 2025 at 6:55 PM
My pitch for an "LLM-native" alternative to citation count/h-index etc:
1) Train an LLM on a new paper and record the average loss during training.
2) Evaluate the retrained LLM on benchmarks.
Your Google Scholar records avg_train_loss * benchmark_delta, and you go write your next paper.
1) Train an LLM on a new paper and record the average loss during training.
2) Evaluate the retrained LLM on benchmarks.
Your Google Scholar records avg_train_loss * benchmark_delta, and you go write your next paper.
Reposted by Jon Barron

Great interview with @jascha.sohldickstein.com about diffusion models! This is the first in a series: similar interviews with Yang Song and yours truly will follow soon.
(One of these is not like the others -- both of them basically invented the field, and I occasionally write a blog post 🥲)
(One of these is not like the others -- both of them basically invented the field, and I occasionally write a blog post 🥲)

History of Diffusion - Jascha Sohl-Dickstein
YouTube video by Bain Capital Ventures
www.youtube.com
February 10, 2025 at 10:28 PM
Great interview with @jascha.sohldickstein.com about diffusion models! This is the first in a series: similar interviews with Yang Song and yours truly will follow soon.
(One of these is not like the others -- both of them basically invented the field, and I occasionally write a blog post 🥲)
(One of these is not like the others -- both of them basically invented the field, and I occasionally write a blog post 🥲)
Reposted by Jon Barron

With the CVPR 2025 rebuttal deadline over, it’s the perfect time to submit a demo application for CVPR 2025. Demos can be any application of computer vision in the real world and are a great way to show off your work to other #computervision enthusiasts. Submit here docs.google.com/forms/d/e/1F...

CVPR 2025 Demo Submission
Submission page for the Demo Track at CVPR 2025. Read the call for demos on the CVPR Website.
docs.google.com
February 9, 2025 at 2:54 AM
With the CVPR 2025 rebuttal deadline over, it’s the perfect time to submit a demo application for CVPR 2025. Demos can be any application of computer vision in the real world and are a great way to show off your work to other #computervision enthusiasts. Submit here docs.google.com/forms/d/e/1F...
fun test for image and video generation systems: add "the camera is upside down" to the prompt (especially for shots of people) and then vertically mirror the output. Even the best models struggle, with upside-down teeth and blinks, and gravity tugging everything up. Here's Veo 2.
February 7, 2025 at 4:56 PM
fun test for image and video generation systems: add "the camera is upside down" to the prompt (especially for shots of people) and then vertically mirror the output. Even the best models struggle, with upside-down teeth and blinks, and gravity tugging everything up. Here's Veo 2.
I fed the "spinning dancer" illusion (a silhouette of a spinning figure that can be seen as rotating clockwise or counter-clockwise, left) into Runway Gen-3 (right). It resolved the ambiguity by having the dancer face the camera and oscillate, which is kinda clever.
January 25, 2025 at 10:55 PM
I fed the "spinning dancer" illusion (a silhouette of a spinning figure that can be seen as rotating clockwise or counter-clockwise, left) into Runway Gen-3 (right). It resolved the ambiguity by having the dancer face the camera and oscillate, which is kinda clever.
`A 1960s NASA scientist with a white button down shirt and black heavy rimmed glasses, with a giant thick alien umbilical cord coming out of the back of his body. The cord is holding him up in space, and he is levitating around his office. Wide angle, full body shot.` #Veo2
January 10, 2025 at 6:52 PM
`A 1960s NASA scientist with a white button down shirt and black heavy rimmed glasses, with a giant thick alien umbilical cord coming out of the back of his body. The cord is holding him up in space, and he is levitating around his office. Wide angle, full body shot.` #Veo2
"A fun children's educational program where Mr. See-thru teaches kids about how the gastrointestinal system works using his semitransparent abdomen." #Veo2
I'm surprised by how well Veo 2 understands human anatomy, and amused by the things that it doesn't yet understand.
I'm surprised by how well Veo 2 understands human anatomy, and amused by the things that it doesn't yet understand.
January 10, 2025 at 6:21 PM
"A fun children's educational program where Mr. See-thru teaches kids about how the gastrointestinal system works using his semitransparent abdomen." #Veo2
I'm surprised by how well Veo 2 understands human anatomy, and amused by the things that it doesn't yet understand.
I'm surprised by how well Veo 2 understands human anatomy, and amused by the things that it doesn't yet understand.
Reposted by Jon Barron

I have been having fun turning the Mario Brothers into a 1940s industrial film using Veo 2.
January 3, 2025 at 8:58 PM
I have been having fun turning the Mario Brothers into a 1940s industrial film using Veo 2.
In case it's helpful to others writing papers or doing comparisons, I'm hosting raw mp4s for the #Veo2 results I've been posting, with no Bluesky-induced compression: drive.google.com/drive/folder....
Here's `A kraken emerging from the ocean at the beach on coney island`, which I forgot to post.
Here's `A kraken emerging from the ocean at the beach on coney island`, which I forgot to post.
January 3, 2025 at 6:40 PM
In case it's helpful to others writing papers or doing comparisons, I'm hosting raw mp4s for the #Veo2 results I've been posting, with no Bluesky-induced compression: drive.google.com/drive/folder....
Here's `A kraken emerging from the ocean at the beach on coney island`, which I forgot to post.
Here's `A kraken emerging from the ocean at the beach on coney island`, which I forgot to post.
Reposted by Jon Barron

Going to put "Towards" in my title, you can't stop me.
January 2, 2025 at 12:43 AM
Going to put "Towards" in my title, you can't stop me.