


Jon Barron
@jonbarron.bsky.social
Principal research scientist at Google DeepMind. Synthesized views are my own.
📍SF Bay Area 🔗 http://jonbarron.info
This feed is a mostly-incomplete mirror of https://x.com/jon_barron, I recommend you just follow me there.
📍SF Bay Area 🔗 http://jonbarron.info
This feed is a mostly-incomplete mirror of https://x.com/jon_barron, I recommend you just follow me there.
This, combined with most fields outside of computer science being overly concerned with maintaining cultural and social solidarity (especially against encroaching technology brothers) seems like the most likely explanation.
November 1, 2025 at 8:47 PM
This, combined with most fields outside of computer science being overly concerned with maintaining cultural and social solidarity (especially against encroaching technology brothers) seems like the most likely explanation.
Ah cool, then why is that last bit true?
July 3, 2025 at 11:59 PM
Ah cool, then why is that last bit true?
I don't see how the last sentence follows logically from the two prior sentences.
July 3, 2025 at 10:52 PM
I don't see how the last sentence follows logically from the two prior sentences.
Be sure to do a dedication where you thank a ton of people, it's kind plus it feels good.
Besides that I'd just do a staple job of your papers. Doing new stuff in a thesis is usually a mistake, unless you later submit it as a paper or post it online somewhere. Nobody reads past the dedication.
Besides that I'd just do a staple job of your papers. Doing new stuff in a thesis is usually a mistake, unless you later submit it as a paper or post it online somewhere. Nobody reads past the dedication.
July 3, 2025 at 10:50 PM
Be sure to do a dedication where you thank a ton of people, it's kind plus it feels good.
Besides that I'd just do a staple job of your papers. Doing new stuff in a thesis is usually a mistake, unless you later submit it as a paper or post it online somewhere. Nobody reads past the dedication.
Besides that I'd just do a staple job of your papers. Doing new stuff in a thesis is usually a mistake, unless you later submit it as a paper or post it online somewhere. Nobody reads past the dedication.
www.instagram.com/mrtoledano/ for anyone else who wanted to see more of this artist's work, really cool stuff!
Login • Instagram
Welcome back to Instagram. Sign in to check out what your friends, family & interests have been capturing & sharing around the world.
www.instagram.com
April 24, 2025 at 8:15 PM
www.instagram.com/mrtoledano/ for anyone else who wanted to see more of this artist's work, really cool stuff!
yeah those fisher kernel models were surprisingly gnarly towards the end of their run.
April 9, 2025 at 7:42 PM
yeah those fisher kernel models were surprisingly gnarly towards the end of their run.
yep absolutely. Super hard to do, but absolutely the best approach if it works.
April 8, 2025 at 5:50 PM
yep absolutely. Super hard to do, but absolutely the best approach if it works.
If you want you can see the models that AlexNet beat in the 2012 imagenet competition, they were quite huge, here's one: www.image-net.org/static_files.... But I think the better though experiment is to imagine how large a shallow model would have to be to match AlexNet's capacity (very very huge)
www.image-net.org
April 8, 2025 at 5:48 PM
If you want you can see the models that AlexNet beat in the 2012 imagenet competition, they were quite huge, here's one: www.image-net.org/static_files.... But I think the better though experiment is to imagine how large a shallow model would have to be to match AlexNet's capacity (very very huge)
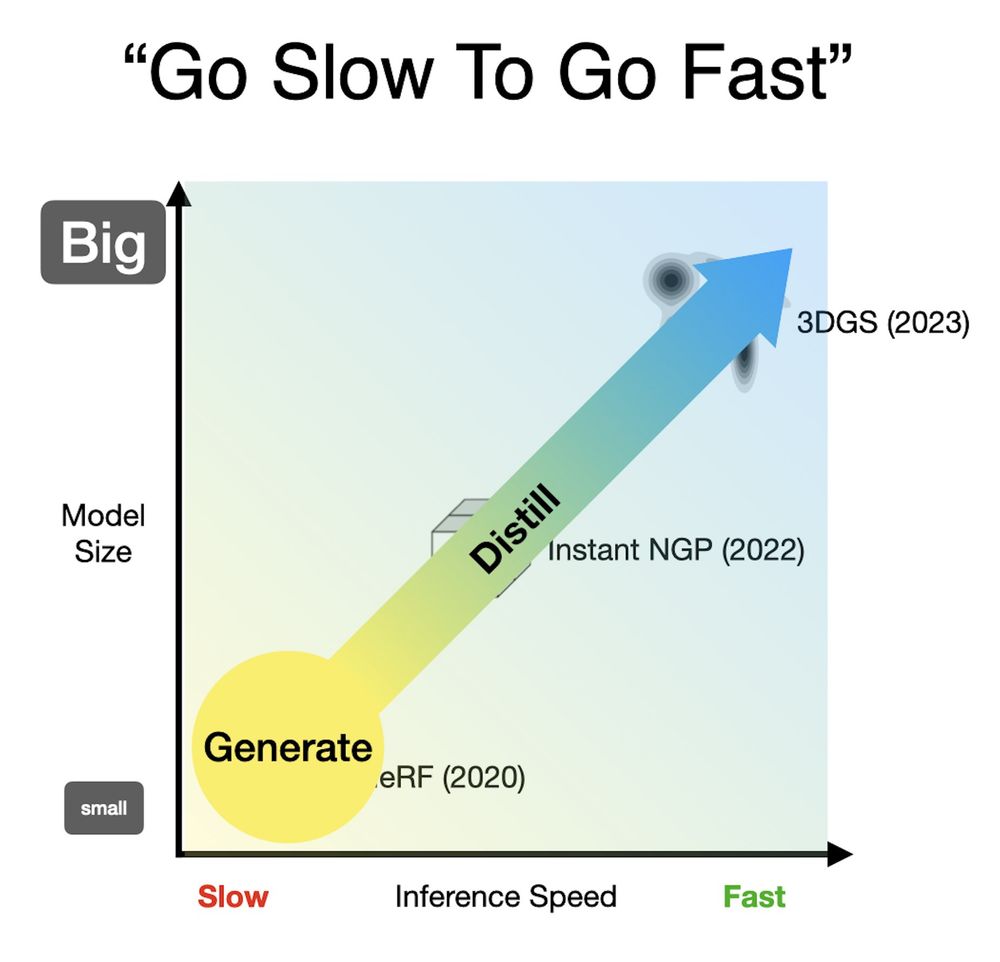
One pattern I like (used in DreamFusion and CAT3D) is to "go slow to go fast" --- generate something small and slow to harness all that AI goodness, and then bake that 3D generation into something that renders fast. Moving along this speed/size continuum is a powerful tool.
April 8, 2025 at 5:25 PM
One pattern I like (used in DreamFusion and CAT3D) is to "go slow to go fast" --- generate something small and slow to harness all that AI goodness, and then bake that 3D generation into something that renders fast. Moving along this speed/size continuum is a powerful tool.
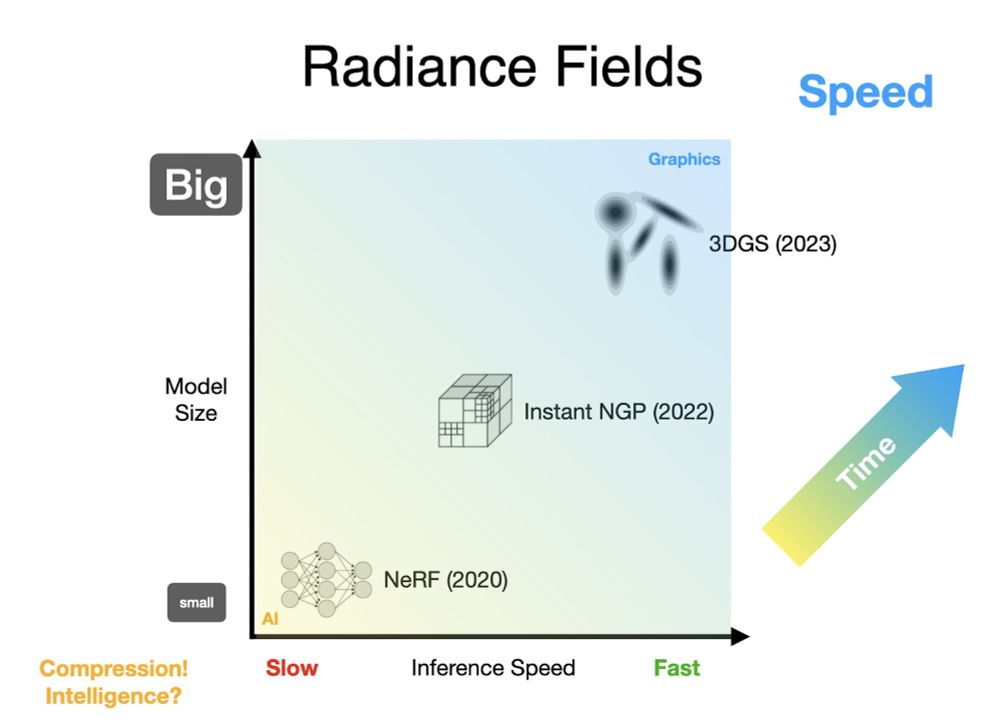
It makes sense that radiance fields trended towards speed --- real-time performance is paramount in 3D graphics. But what we've seen in AI suggests that magical things can happen if you forgo speed and embrace compression. What else is in that lower left corner of this graph?
April 8, 2025 at 5:25 PM
It makes sense that radiance fields trended towards speed --- real-time performance is paramount in 3D graphics. But what we've seen in AI suggests that magical things can happen if you forgo speed and embrace compression. What else is in that lower left corner of this graph?
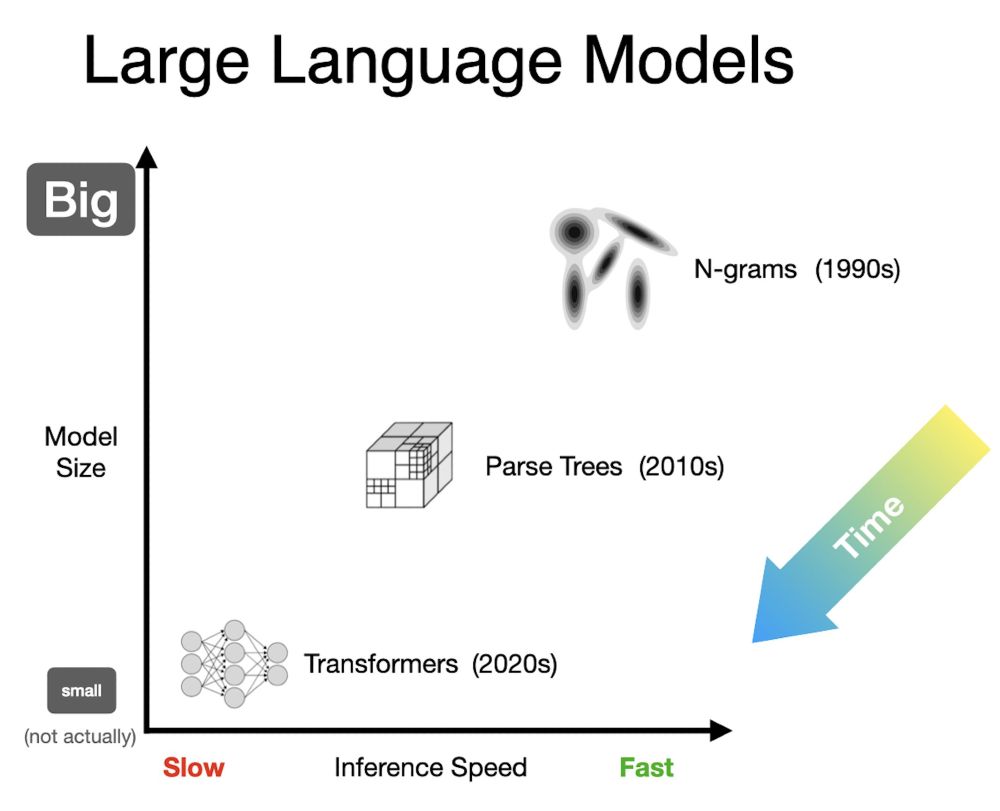
And this gets a bit hand-wavy, but NLP also started with shallow+fast+big n-gram models, then moved to parse trees etc, and then on to transformers. And yes, I know, transformers aren't actually small, but they are insanely compressed! "Compression is intelligence", as they say.
April 8, 2025 at 5:25 PM
And this gets a bit hand-wavy, but NLP also started with shallow+fast+big n-gram models, then moved to parse trees etc, and then on to transformers. And yes, I know, transformers aren't actually small, but they are insanely compressed! "Compression is intelligence", as they say.
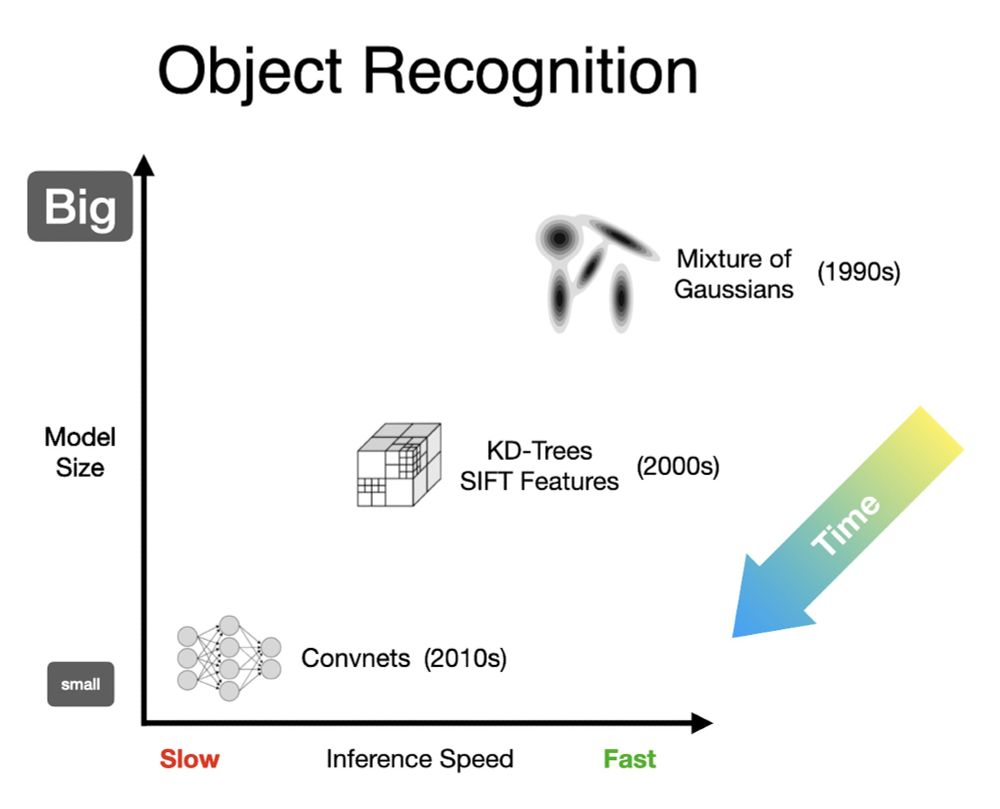
In fact, it's the *opposite* of what we saw in object recognition. There we started with shallow+fast+big models like mixtures of Gaussians on color, then moved to more compact and hierarchical models using trees and features, and finally to highly compressed CNNs and VITs.
April 8, 2025 at 5:25 PM
In fact, it's the *opposite* of what we saw in object recognition. There we started with shallow+fast+big models like mixtures of Gaussians on color, then moved to more compact and hierarchical models using trees and features, and finally to highly compressed CNNs and VITs.
Let's plot the trajectory of these three generations, with speed on the x-axis and model size on the y-axis. Over time, we've been steadily moving to bigger and faster models, up and to the right. This is sensible, but it's not the trend that other AI fields have been on...
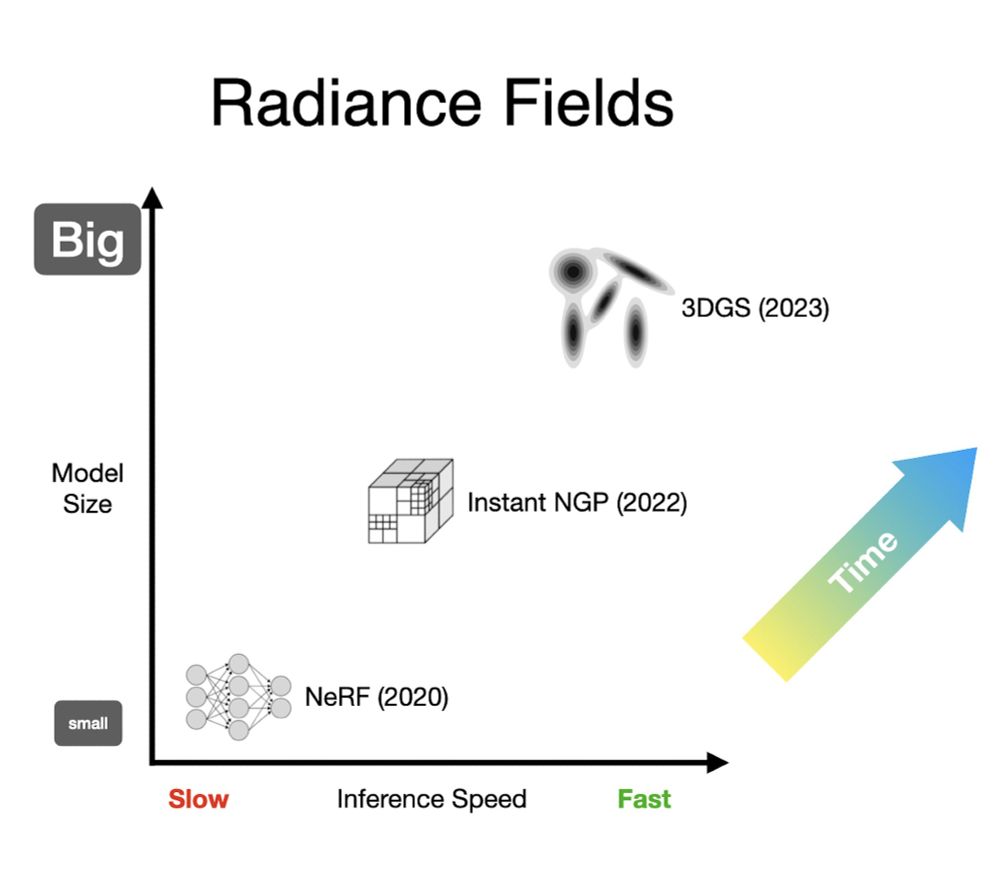
April 8, 2025 at 5:25 PM
Let's plot the trajectory of these three generations, with speed on the x-axis and model size on the y-axis. Over time, we've been steadily moving to bigger and faster models, up and to the right. This is sensible, but it's not the trend that other AI fields have been on...
Generation three swapped out those voxel grids for a bag of particles, with 3DGS getting the most adoption (shout out to 2021's pulsar though). These models are larger than grids, and can be tricky to optimize, but the upside for rendering speed is so huge that it's worth it.

April 8, 2025 at 5:25 PM
Generation three swapped out those voxel grids for a bag of particles, with 3DGS getting the most adoption (shout out to 2021's pulsar though). These models are larger than grids, and can be tricky to optimize, but the upside for rendering speed is so huge that it's worth it.
The second generation was all about swapping out MLPs for a giant voxel grid of some kind, usually with some hierarchy/aliasing (NGP) or low-rank (TensoRF) trick for dealing with OOMs. These grids are much bigger than MLPs, but they're easy to train and fast to render.

April 8, 2025 at 5:25 PM
The second generation was all about swapping out MLPs for a giant voxel grid of some kind, usually with some hierarchy/aliasing (NGP) or low-rank (TensoRF) trick for dealing with OOMs. These grids are much bigger than MLPs, but they're easy to train and fast to render.
It's certainly a shocking result, but I think concluding that "Sora learned 3D consistency" isn't a totally well-founded claim. We have no real idea what any models learn under the hood, and it should be possible for models to produce plausible videos without actually doing anything "in 3D".
March 11, 2025 at 4:41 PM
It's certainly a shocking result, but I think concluding that "Sora learned 3D consistency" isn't a totally well-founded claim. We have no real idea what any models learn under the hood, and it should be possible for models to produce plausible videos without actually doing anything "in 3D".