



Jon Barron
@jonbarron.bsky.social
Principal research scientist at Google DeepMind. Synthesized views are my own.
📍SF Bay Area 🔗 http://jonbarron.info
This feed is a mostly-incomplete mirror of https://x.com/jon_barron, I recommend you just follow me there.
📍SF Bay Area 🔗 http://jonbarron.info
This feed is a mostly-incomplete mirror of https://x.com/jon_barron, I recommend you just follow me there.
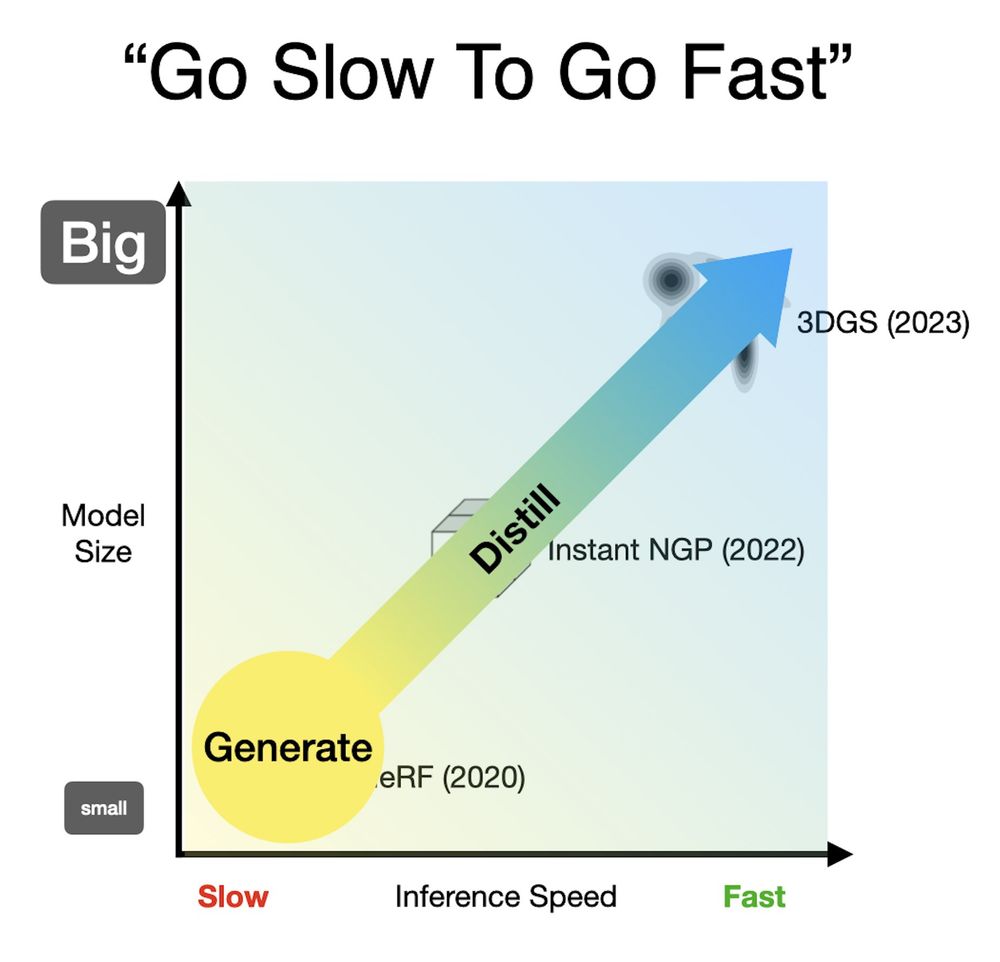
One pattern I like (used in DreamFusion and CAT3D) is to "go slow to go fast" --- generate something small and slow to harness all that AI goodness, and then bake that 3D generation into something that renders fast. Moving along this speed/size continuum is a powerful tool.
April 8, 2025 at 5:25 PM
One pattern I like (used in DreamFusion and CAT3D) is to "go slow to go fast" --- generate something small and slow to harness all that AI goodness, and then bake that 3D generation into something that renders fast. Moving along this speed/size continuum is a powerful tool.
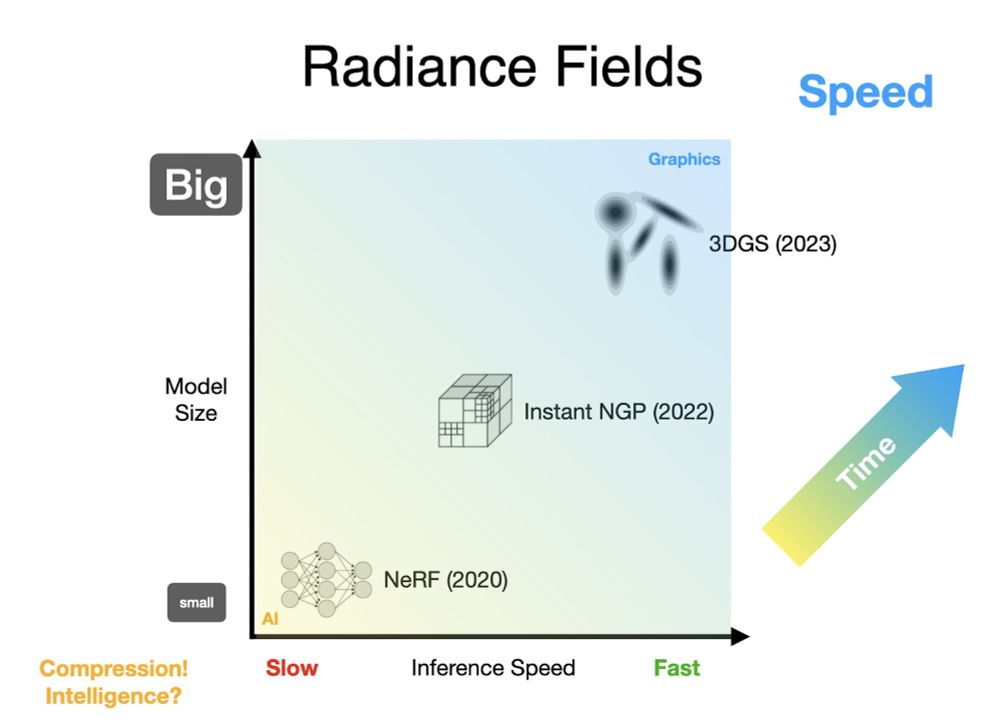
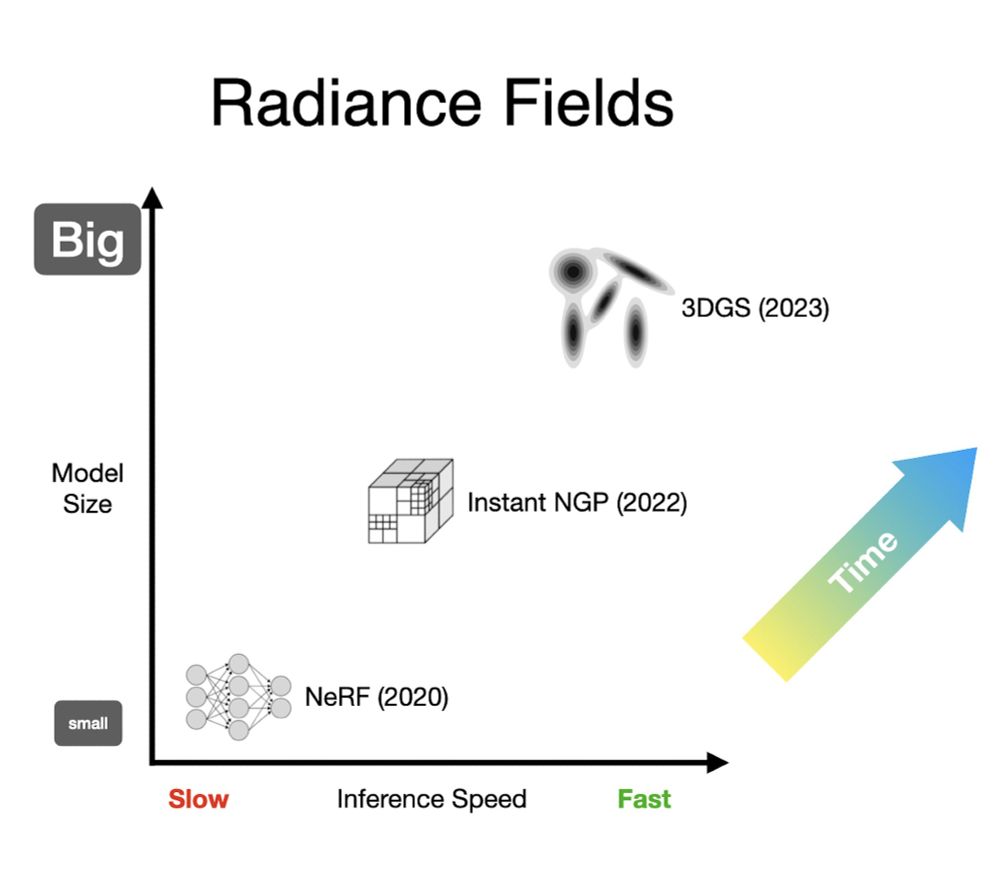
It makes sense that radiance fields trended towards speed --- real-time performance is paramount in 3D graphics. But what we've seen in AI suggests that magical things can happen if you forgo speed and embrace compression. What else is in that lower left corner of this graph?
April 8, 2025 at 5:25 PM
It makes sense that radiance fields trended towards speed --- real-time performance is paramount in 3D graphics. But what we've seen in AI suggests that magical things can happen if you forgo speed and embrace compression. What else is in that lower left corner of this graph?
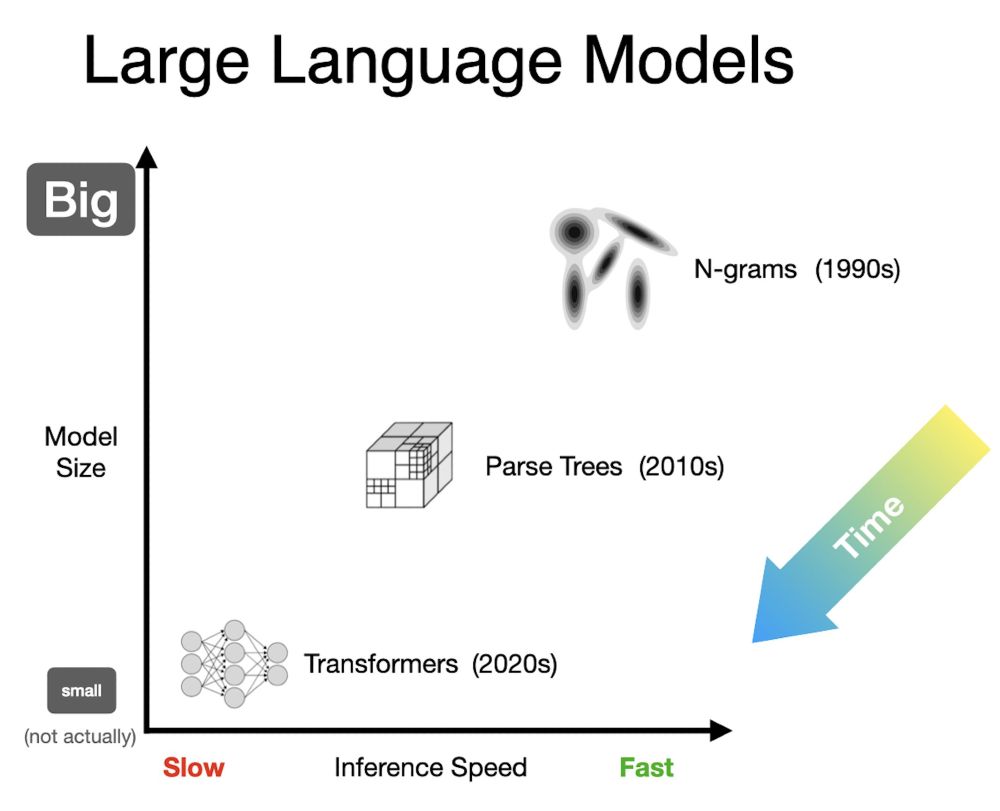
And this gets a bit hand-wavy, but NLP also started with shallow+fast+big n-gram models, then moved to parse trees etc, and then on to transformers. And yes, I know, transformers aren't actually small, but they are insanely compressed! "Compression is intelligence", as they say.
April 8, 2025 at 5:25 PM
And this gets a bit hand-wavy, but NLP also started with shallow+fast+big n-gram models, then moved to parse trees etc, and then on to transformers. And yes, I know, transformers aren't actually small, but they are insanely compressed! "Compression is intelligence", as they say.
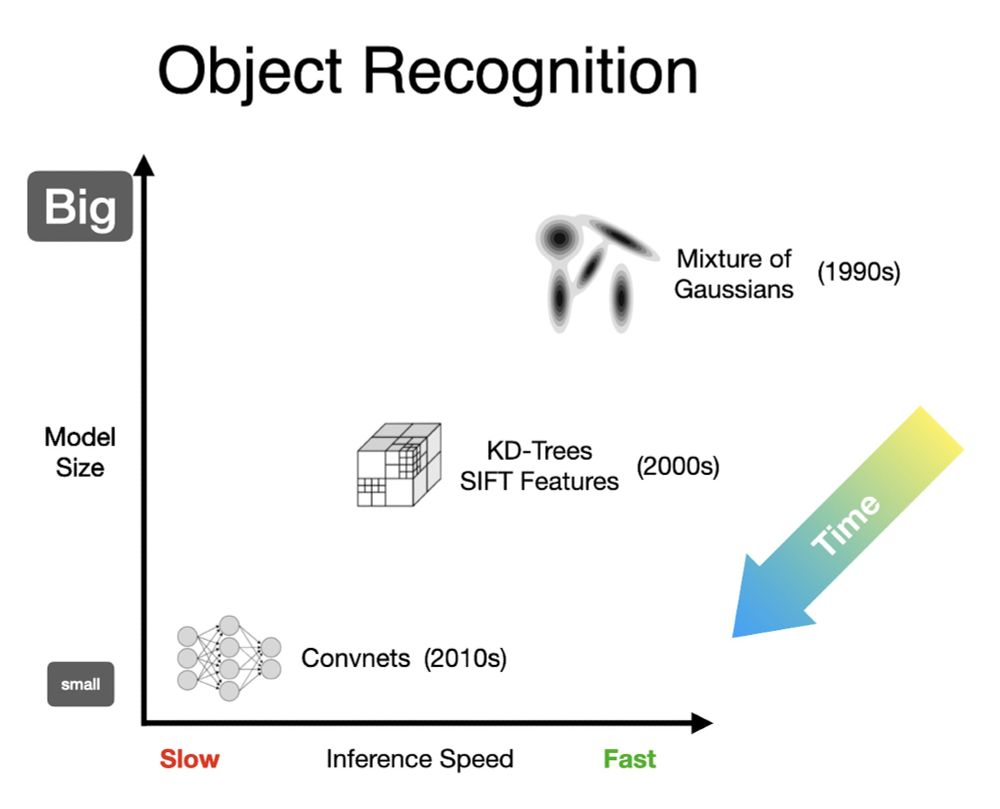
In fact, it's the *opposite* of what we saw in object recognition. There we started with shallow+fast+big models like mixtures of Gaussians on color, then moved to more compact and hierarchical models using trees and features, and finally to highly compressed CNNs and VITs.
April 8, 2025 at 5:25 PM
In fact, it's the *opposite* of what we saw in object recognition. There we started with shallow+fast+big models like mixtures of Gaussians on color, then moved to more compact and hierarchical models using trees and features, and finally to highly compressed CNNs and VITs.
Let's plot the trajectory of these three generations, with speed on the x-axis and model size on the y-axis. Over time, we've been steadily moving to bigger and faster models, up and to the right. This is sensible, but it's not the trend that other AI fields have been on...
April 8, 2025 at 5:25 PM
Let's plot the trajectory of these three generations, with speed on the x-axis and model size on the y-axis. Over time, we've been steadily moving to bigger and faster models, up and to the right. This is sensible, but it's not the trend that other AI fields have been on...
Generation three swapped out those voxel grids for a bag of particles, with 3DGS getting the most adoption (shout out to 2021's pulsar though). These models are larger than grids, and can be tricky to optimize, but the upside for rendering speed is so huge that it's worth it.

April 8, 2025 at 5:25 PM
Generation three swapped out those voxel grids for a bag of particles, with 3DGS getting the most adoption (shout out to 2021's pulsar though). These models are larger than grids, and can be tricky to optimize, but the upside for rendering speed is so huge that it's worth it.
The second generation was all about swapping out MLPs for a giant voxel grid of some kind, usually with some hierarchy/aliasing (NGP) or low-rank (TensoRF) trick for dealing with OOMs. These grids are much bigger than MLPs, but they're easy to train and fast to render.

April 8, 2025 at 5:25 PM
The second generation was all about swapping out MLPs for a giant voxel grid of some kind, usually with some hierarchy/aliasing (NGP) or low-rank (TensoRF) trick for dealing with OOMs. These grids are much bigger than MLPs, but they're easy to train and fast to render.
A thread of thoughts on radiance fields, from my keynote at 3DV:
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.

April 8, 2025 at 5:25 PM
A thread of thoughts on radiance fields, from my keynote at 3DV:
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.
Radiance fields have had 3 distinct generations. First was NeRF: just posenc and a tiny MLP. This was slow to train but worked really well, and it was unusually compressed --- The NeRF was smaller than the images.
Here's Bolt3D: fast feed-forward 3D generation from one or many input images. Diffusion means that generated scenes contain lots of interesting structure in unobserved regions. ~6 seconds to generate, renders in real time.
Project page: szymanowiczs.github.io/bolt3d
Arxiv: arxiv.org/abs/2503.14445
Project page: szymanowiczs.github.io/bolt3d
Arxiv: arxiv.org/abs/2503.14445
March 19, 2025 at 6:37 PM
Here's Bolt3D: fast feed-forward 3D generation from one or many input images. Diffusion means that generated scenes contain lots of interesting structure in unobserved regions. ~6 seconds to generate, renders in real time.
Project page: szymanowiczs.github.io/bolt3d
Arxiv: arxiv.org/abs/2503.14445
Project page: szymanowiczs.github.io/bolt3d
Arxiv: arxiv.org/abs/2503.14445
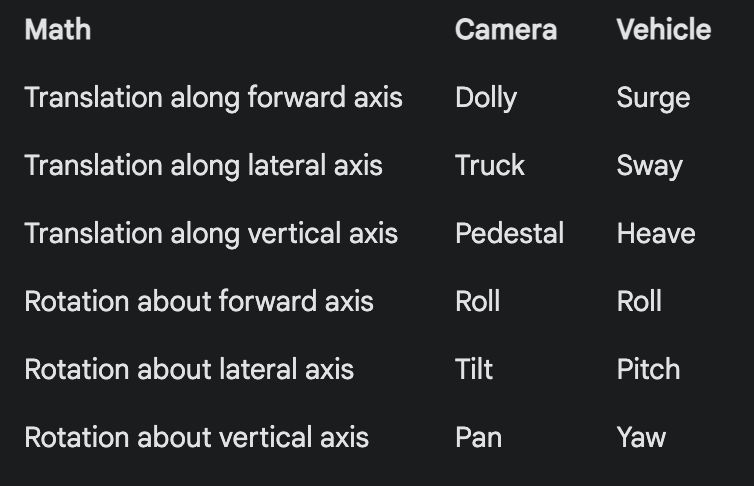
I made this handy cheat sheet for the jargon that 6DOF math maps to for cameras and vehicles. Worth learning if you, like me, are worried about embarrassing yourself in front of a cinematographer or naval admiral.
March 19, 2025 at 4:50 PM
I made this handy cheat sheet for the jargon that 6DOF math maps to for cameras and vehicles. Worth learning if you, like me, are worried about embarrassing yourself in front of a cinematographer or naval admiral.
Next week is the one year anniversary of this paper showing that videos generated from Sora are nearly 3D-consistent. I'm surprised we never saw any follow-up papers in this line evaluating other videos models this way, it would be helpful to track these metrics over time. arxiv.org/abs/2402.17403

February 23, 2025 at 6:37 PM
Next week is the one year anniversary of this paper showing that videos generated from Sora are nearly 3D-consistent. I'm surprised we never saw any follow-up papers in this line evaluating other videos models this way, it would be helpful to track these metrics over time. arxiv.org/abs/2402.17403
Veo 2 now has a public price point: $0.50 per second. Very important number to keep in mind when considering the future of generative and non-generative media. Taken from cloud.google.com/vertex-ai/ge...

February 22, 2025 at 6:52 PM
Veo 2 now has a public price point: $0.50 per second. Very important number to keep in mind when considering the future of generative and non-generative media. Taken from cloud.google.com/vertex-ai/ge...
Oops, there was a bug in one of the animations, here's a fixed version.
February 19, 2025 at 10:19 PM
Oops, there was a bug in one of the animations, here's a fixed version.
The paper has JAX/numpy code (should translate to pytorch easily, hassle me and I'll do it myself) that reproduces everything in this thread. This is easy because every loss, kernel, activation, etc is just a wrapper around f(). Oh, and f() is its own inverse, very handy.

February 18, 2025 at 6:43 PM
The paper has JAX/numpy code (should translate to pytorch easily, hassle me and I'll do it myself) that reproduces everything in this thread. This is easy because every loss, kernel, activation, etc is just a wrapper around f(). Oh, and f() is its own inverse, very handy.
Implementing f() well is tricky --- the naive way is numerically unstable and expensive. But I found a nice way to decompose the math such that it's super stable and cheap to evaluate. The trick is just phrasing everything in terms of expm1 and log1p while avoiding branching.

February 18, 2025 at 6:43 PM
Implementing f() well is tricky --- the naive way is numerically unstable and expensive. But I found a nice way to decompose the math such that it's super stable and cheap to evaluate. The trick is just phrasing everything in terms of expm1 and log1p while avoiding branching.
More activations: composing f(x, λ) exactly reproduces softplus, sigmoid, tanh, relu, and linear activations, and smoothly interpolate between them. This suggests f() could be useful for network architectures, but I haven't explored this. Someone should! (again, happy to help)
February 18, 2025 at 6:43 PM
More activations: composing f(x, λ) exactly reproduces softplus, sigmoid, tanh, relu, and linear activations, and smoothly interpolate between them. This suggests f() could be useful for network architectures, but I haven't explored this. Someone should! (again, happy to help)
Now the cool stuff. f(x, λ) is defined for x>=0, but you can generalize it x<0 inputs by giving them their own λ. Changing (λ-, λ+) values lets you interpolate between sigmoid-/logit-/exp-/log-shaped functions. This family also *exactly* reproduces the ELU activation function!
February 18, 2025 at 6:43 PM
Now the cool stuff. f(x, λ) is defined for x>=0, but you can generalize it x<0 inputs by giving them their own λ. Changing (λ-, λ+) values lets you interpolate between sigmoid-/logit-/exp-/log-shaped functions. This family also *exactly* reproduces the ELU activation function!
f'(0.5 * x^2) yields a long list of kernel functions from the literature: rational quadratic kernels, the inverse kernel, the Gaussian/RBF kernel, the quadratic kernel, the multiquadric kernel, the inverse multiquadric kernel, and a non-normalized Student's T-distribution.
February 18, 2025 at 6:43 PM
f'(0.5 * x^2) yields a long list of kernel functions from the literature: rational quadratic kernels, the inverse kernel, the Gaussian/RBF kernel, the quadratic kernel, the multiquadric kernel, the inverse multiquadric kernel, and a non-normalized Student's T-distribution.
3DGSers: I think this PDF might be useful for radiance fields, like in arxiv.org/abs/2501.18630 and arxiv.org/abs/2405.15425. I'm not planning on pursuing this further myself, so if you wanna try this distribution in this setting, go for it! (I'm happy to help out)


February 18, 2025 at 6:43 PM
3DGSers: I think this PDF might be useful for radiance fields, like in arxiv.org/abs/2501.18630 and arxiv.org/abs/2405.15425. I'm not planning on pursuing this further myself, so if you wanna try this distribution in this setting, go for it! (I'm happy to help out)
If you use those losses as negative log-likelihoods you get a family of PDFs that interpolates between Cauchy, Gaussian, and Epanechnikov distributions. This is again a superset of my CVPR2019 paper, where the new distributions (λ>1) have a finite domain that narrows as λ grows.
February 18, 2025 at 6:43 PM
If you use those losses as negative log-likelihoods you get a family of PDFs that interpolates between Cauchy, Gaussian, and Epanechnikov distributions. This is again a superset of my CVPR2019 paper, where the new distributions (λ>1) have a finite domain that narrows as λ grows.
Applying f to x^2 yields a nice family of losses that interpolates between Welsch loss, Geman-McClure loss, Cauchy loss, Charbonnier loss, and L2 loss. This is a mild superset of my CVPR2019 paper/loss (the new losses are for λ>1, not sure if they're useful but they look nice).
February 18, 2025 at 6:43 PM
Applying f to x^2 yields a nice family of losses that interpolates between Welsch loss, Geman-McClure loss, Cauchy loss, Charbonnier loss, and L2 loss. This is a mild superset of my CVPR2019 paper/loss (the new losses are for λ>1, not sure if they're useful but they look nice).
Here's a comparison of the venerable Box-Cox transform (left) and f (right). Box-Cox is asymmetric across y=x and collapses to the axes as |λ| grows, so I just kinda normalized it. There exists a bijection between the two, so it's a small tweak.


February 18, 2025 at 6:43 PM
Here's a comparison of the venerable Box-Cox transform (left) and f (right). Box-Cox is asymmetric across y=x and collapses to the axes as |λ| grows, so I just kinda normalized it. There exists a bijection between the two, so it's a small tweak.
I just pushed a new paper to arXiv. I realized that a lot of my previous work on robust losses and nerf-y things was dancing around something simpler: a slight tweak to the classic Box-Cox power transform that makes it much more useful and stable. It's this f(x, λ) here:
February 18, 2025 at 6:43 PM
I just pushed a new paper to arXiv. I realized that a lot of my previous work on robust losses and nerf-y things was dancing around something simpler: a slight tweak to the classic Box-Cox power transform that makes it much more useful and stable. It's this f(x, λ) here:
this thread I saw on Twitter the other day captures my current sentiment towards this platform. x.com/AliceFromQue...

February 8, 2025 at 9:40 PM
this thread I saw on Twitter the other day captures my current sentiment towards this platform. x.com/AliceFromQue...
Here's "A cute dog catching a frisbee in the air, the camera is upside down", mirrored vertically. You get a fun zero-G dog with floppy backwards-bending feet, and a frisbee that keeps trying to fly up into the sky like a helium balloon.
February 7, 2025 at 4:56 PM
Here's "A cute dog catching a frisbee in the air, the camera is upside down", mirrored vertically. You get a fun zero-G dog with floppy backwards-bending feet, and a frisbee that keeps trying to fly up into the sky like a helium balloon.