



Eilif B. Muller
@neuralensemble.bsky.social
A leading cause of In Silico #Neuroscience world-wide since 2010
https://neuro.plasticit.ai
https://neuro.plasticit.ai
Reposted by Eilif B. Muller

Excellent funding opportunity: $100k/year for two years for a postdoc position in Montreal. Apply if you're interested in joining Montreal's thriving #NeuroAI ecosystem.

🔷 Launch of the IVADO 2026 Postdoctoral Research Funding Program for outstanding national and international postdoctoral researchers.
More info: ivado.ca/en/scholarsh...
#AI #ArtificialIntelligence #R3AI #Funding #Postdoc
More info: ivado.ca/en/scholarsh...
#AI #ArtificialIntelligence #R3AI #Funding #Postdoc

October 16, 2025 at 3:34 PM
Excellent funding opportunity: $100k/year for two years for a postdoc position in Montreal. Apply if you're interested in joining Montreal's thriving #NeuroAI ecosystem.
Reposted by Eilif B. Muller

JUPITER, the European Union's new exascale supercomputer, is 100% powered by renewable energy.
What will researchers use it for?
go.nature.com/4gjekiO
What will researchers use it for?
go.nature.com/4gjekiO

Meet Europe's first exascale supercomputer — can it compete in the global AI race?
JUPITER, the European Union's new exascale supercomputer, is 100% powered by renewable energy. What will researchers use it for?
go.nature.com
September 12, 2025 at 2:47 PM
JUPITER, the European Union's new exascale supercomputer, is 100% powered by renewable energy.
What will researchers use it for?
go.nature.com/4gjekiO
What will researchers use it for?
go.nature.com/4gjekiO
Reposted by Eilif B. Muller

A glimpse at what #NeuroAI brain models might enable: a topographic vision model predicts stimulation patterns that steer complex object recognition behavior in primates. This could be a key 'software' component for visual prosthetic hardware 🧠🤖🧪

October 8, 2025 at 11:11 AM
A glimpse at what #NeuroAI brain models might enable: a topographic vision model predicts stimulation patterns that steer complex object recognition behavior in primates. This could be a key 'software' component for visual prosthetic hardware 🧠🤖🧪
Reposted by Eilif B. Muller

Five enduring, in-lab VR results (w/ @stanfordvr.bsky.social): (1) presence depends on activity, (2) self-avatars shape behavior, (3) VR better for procedural than abstract learning,(4) body tracking is powerful but privacy-risky, (5) people underestimate VR distance.
www.nature.com/articles/s41...
www.nature.com/articles/s41...
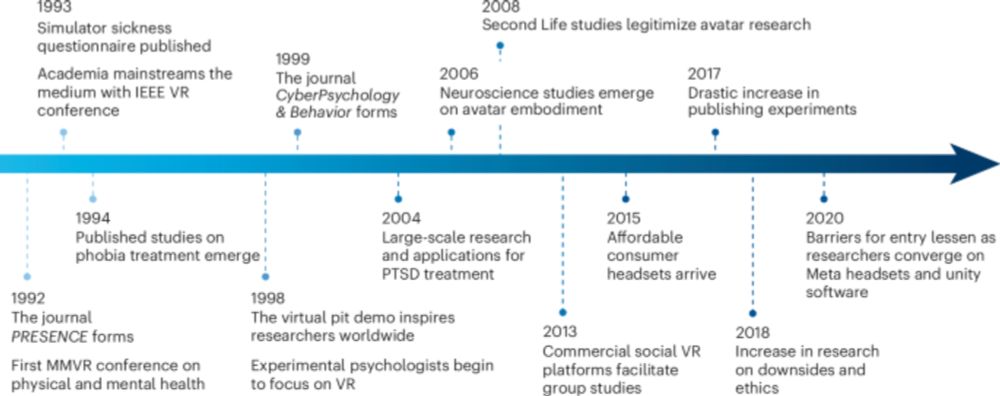
Five canonical findings from 30 years of psychological experimentation in virtual reality - Nature Human Behaviour
This Review presents five canonical psychological research findings in virtual reality (VR) over the past three decades. These findings have been consistently replicated and are useful for both resear...
www.nature.com
May 23, 2025 at 3:46 PM
Five enduring, in-lab VR results (w/ @stanfordvr.bsky.social): (1) presence depends on activity, (2) self-avatars shape behavior, (3) VR better for procedural than abstract learning,(4) body tracking is powerful but privacy-risky, (5) people underestimate VR distance.
www.nature.com/articles/s41...
www.nature.com/articles/s41...
Reposted by Eilif B. Muller

Years later (and many polygons fewer) we finally ported Becoming Homeless to the Meta Quest for free.
www.meta.com/experiences/...
Premiering at the Tribeca Film Festival (2017), VHIL's most studied piece on VR empathy. Samples in the 1000s, behavioral measures, longitudinal outcomes months later.
www.meta.com/experiences/...
Premiering at the Tribeca Film Festival (2017), VHIL's most studied piece on VR empathy. Samples in the 1000s, behavioral measures, longitudinal outcomes months later.

Becoming Homeless on Meta Quest
In this immersive virtual reality experience, spend days in the life of someone who can no longer afford a home. Attempt to save your home and to protect yourself and your belongings as you walk in an...
www.meta.com
August 5, 2025 at 10:15 PM
Years later (and many polygons fewer) we finally ported Becoming Homeless to the Meta Quest for free.
www.meta.com/experiences/...
Premiering at the Tribeca Film Festival (2017), VHIL's most studied piece on VR empathy. Samples in the 1000s, behavioral measures, longitudinal outcomes months later.
www.meta.com/experiences/...
Premiering at the Tribeca Film Festival (2017), VHIL's most studied piece on VR empathy. Samples in the 1000s, behavioral measures, longitudinal outcomes months later.
Congrats to @frooxius.bsky.social and team! Very exciting milestone for my favorite Social VR platform @resonite.com !
I'm def seeing a huge jump in performance! Looking forward to the larger events this enables!
I'm def seeing a huge jump in performance! Looking forward to the larger events this enables!

The Splittening is upon us! We have just merged to the main branch!
Welcome to the next era of Resonite!
Welcome to the next era of Resonite!
August 28, 2025 at 8:27 PM
Congrats to @frooxius.bsky.social and team! Very exciting milestone for my favorite Social VR platform @resonite.com !
I'm def seeing a huge jump in performance! Looking forward to the larger events this enables!
I'm def seeing a huge jump in performance! Looking forward to the larger events this enables!
I'm a big fan of the MICrONs project. It's a huge step forward for understanding cortical structure and function, and a model of open science. This is an amazing artful website that communicates why!
alleninstitute.org/news/learnin...
alleninstitute.org/news/learnin...
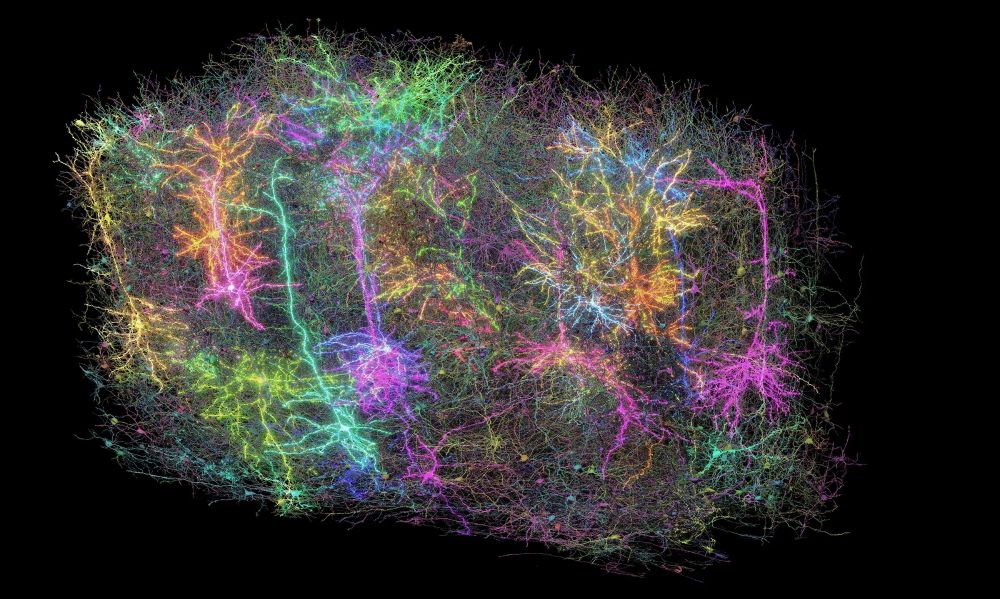
Attempting the impossible: A 20-year journey to learn the language of the brain
In what is considered the most complicated neuroscience experiment ever attempted, scientists from the Allen Institute and global collaborators have created the largest, most complex wiring diagram an...
alleninstitute.org
May 20, 2025 at 9:28 PM
I'm a big fan of the MICrONs project. It's a huge step forward for understanding cortical structure and function, and a model of open science. This is an amazing artful website that communicates why!
alleninstitute.org/news/learnin...
alleninstitute.org/news/learnin...
Reposted by Eilif B. Muller

We are excited to announce the World premiere of HOMMAGE! Nominated for Best Art World & Best Art Experience at Raindance Immersive 2025 • Tour reservations open on 2nd June,
www.raindanceimmersive.com#/2025-hommage/
#Moebius #Resonite
www.raindanceimmersive.com#/2025-hommage/
#Moebius #Resonite

May 19, 2025 at 3:57 PM
We are excited to announce the World premiere of HOMMAGE! Nominated for Best Art World & Best Art Experience at Raindance Immersive 2025 • Tour reservations open on 2nd June,
www.raindanceimmersive.com#/2025-hommage/
#Moebius #Resonite
www.raindanceimmersive.com#/2025-hommage/
#Moebius #Resonite
Reposted by Eilif B. Muller

Happy to see this study led by Irene Onorato finally out - we show distinct phase locking and spike timing of optotagged PV cells and Sst interneuron subtypes during gamma oscillations in mouse visual cortex, suggesting an update to the classic PING model www.sciencedirect.com/science/arti...
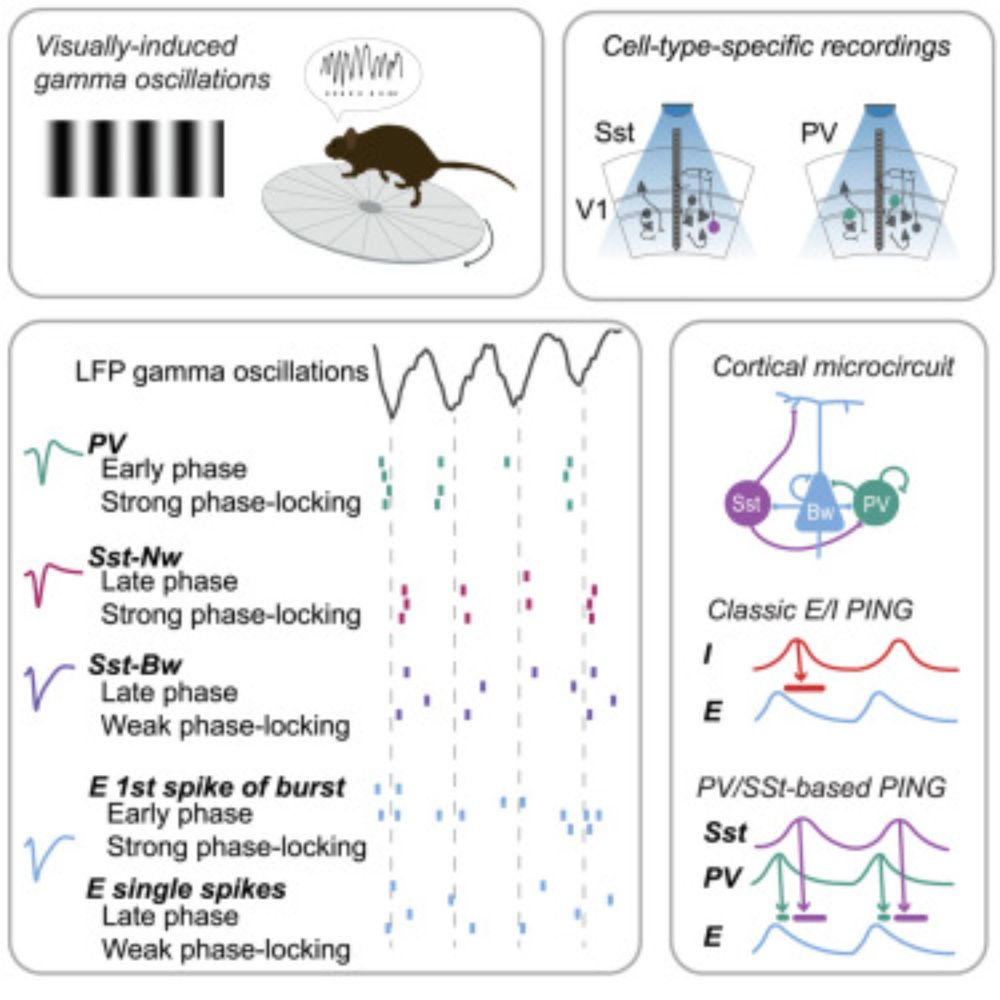
Distinct roles of PV and Sst interneurons in visually induced gamma oscillations
Gamma-frequency oscillations are a hallmark of active information processing and are generated by interactions between excitatory and inhibitory neuro…
www.sciencedirect.com
March 6, 2025 at 10:22 PM
Happy to see this study led by Irene Onorato finally out - we show distinct phase locking and spike timing of optotagged PV cells and Sst interneuron subtypes during gamma oscillations in mouse visual cortex, suggesting an update to the classic PING model www.sciencedirect.com/science/arti...
Reposted by Eilif B. Muller

A new Science study finds that different dendritic segments of a single neuron follow distinct rules.
The results challenge the idea that neurons follow a single learning strategy and offer a new perspective on how the brain learns and adapts behavior. scim.ag/3YQdUZK #SciencePerspective
The results challenge the idea that neurons follow a single learning strategy and offer a new perspective on how the brain learns and adapts behavior. scim.ag/3YQdUZK #SciencePerspective
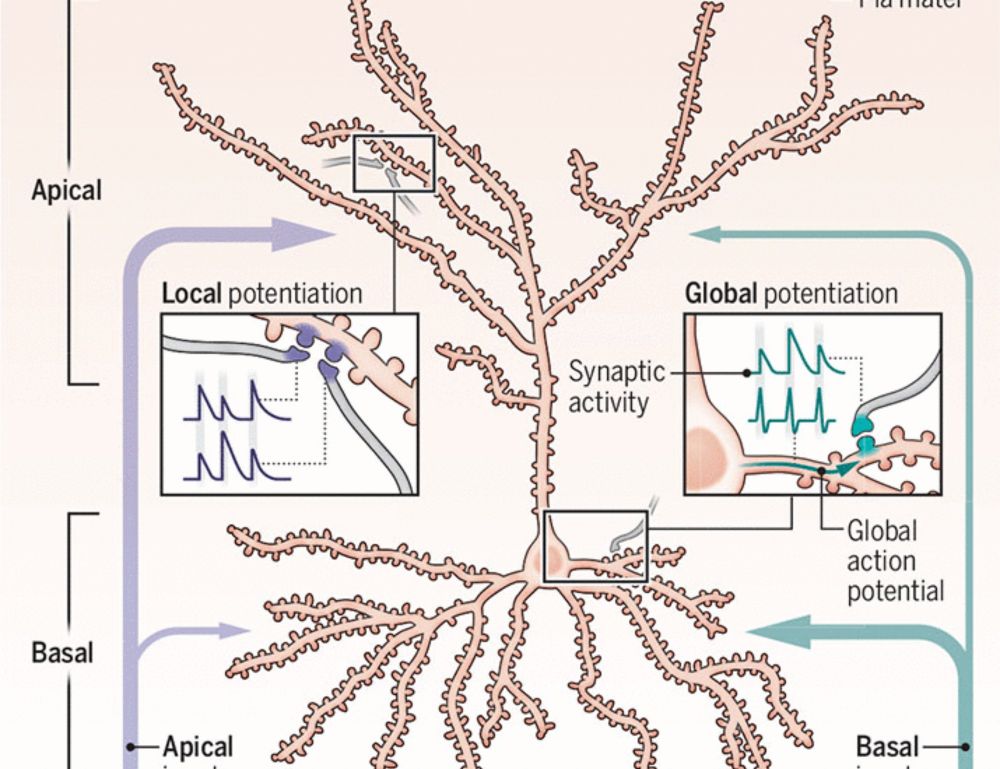
Dendritic arbors structure memories
Synapses on different dendritic domains store distinct types of information
scim.ag
April 28, 2025 at 5:55 PM
A new Science study finds that different dendritic segments of a single neuron follow distinct rules.
The results challenge the idea that neurons follow a single learning strategy and offer a new perspective on how the brain learns and adapts behavior. scim.ag/3YQdUZK #SciencePerspective
The results challenge the idea that neurons follow a single learning strategy and offer a new perspective on how the brain learns and adapts behavior. scim.ag/3YQdUZK #SciencePerspective
Reposted by Eilif B. Muller

🔎 In sum: Hippocampal ripples trigger a transition from compressed hippocampal codes to expanded cortical states that reconstruct past experiences.
Great collaboration with @s-michelmann.bsky.social and @doellerlab.bsky.social!
Read the full paper here:
www.biorxiv.org/content/10.1...
Great collaboration with @s-michelmann.bsky.social and @doellerlab.bsky.social!
Read the full paper here:
www.biorxiv.org/content/10.1...

Hippocampal ripples initiate cortical dimensionality expansion for memory retrieval
How are past experiences reconstructed from memory? Learning is thought to compress external inputs into low-dimensional hippocampal representations, later expanded into high-dimensional cortical acti...
www.biorxiv.org
April 29, 2025 at 6:00 AM
🔎 In sum: Hippocampal ripples trigger a transition from compressed hippocampal codes to expanded cortical states that reconstruct past experiences.
Great collaboration with @s-michelmann.bsky.social and @doellerlab.bsky.social!
Read the full paper here:
www.biorxiv.org/content/10.1...
Great collaboration with @s-michelmann.bsky.social and @doellerlab.bsky.social!
Read the full paper here:
www.biorxiv.org/content/10.1...
Reposted by Eilif B. Muller
Check out our new paper!
Vision models often struggle with learning both transformation-invariant and -equivariant representations at the same time.
@hafezghm.bsky.social shows that self-supervised prediction with proper inductive biases achieves both simultaneously. (1/4)
#MLSky #NeuroAI
Vision models often struggle with learning both transformation-invariant and -equivariant representations at the same time.
@hafezghm.bsky.social shows that self-supervised prediction with proper inductive biases achieves both simultaneously. (1/4)
#MLSky #NeuroAI

Preprint Alert 🚀
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)

May 14, 2025 at 12:57 PM
Check out our new paper!
Vision models often struggle with learning both transformation-invariant and -equivariant representations at the same time.
@hafezghm.bsky.social shows that self-supervised prediction with proper inductive biases achieves both simultaneously. (1/4)
#MLSky #NeuroAI
Vision models often struggle with learning both transformation-invariant and -equivariant representations at the same time.
@hafezghm.bsky.social shows that self-supervised prediction with proper inductive biases achieves both simultaneously. (1/4)
#MLSky #NeuroAI
Reposted by Eilif B. Muller


For understanding learning in neocortex 🧠, self-supervised learning 🤖 is interesting, but has several shortcomings.
Seq-JEPA is a step in the right direction. It learns by predicting sensory outcomes from series of interactions. Cool things emerged! 👇with @shahabbakht.bsky.social
#MLSky #NeuroAI
Seq-JEPA is a step in the right direction. It learns by predicting sensory outcomes from series of interactions. Cool things emerged! 👇with @shahabbakht.bsky.social
#MLSky #NeuroAI
Preprint Alert 🚀
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
May 14, 2025 at 3:11 PM
For understanding learning in neocortex 🧠, self-supervised learning 🤖 is interesting, but has several shortcomings.
Seq-JEPA is a step in the right direction. It learns by predicting sensory outcomes from series of interactions. Cool things emerged! 👇with @shahabbakht.bsky.social
#MLSky #NeuroAI
Seq-JEPA is a step in the right direction. It learns by predicting sensory outcomes from series of interactions. Cool things emerged! 👇with @shahabbakht.bsky.social
#MLSky #NeuroAI
Reposted by Eilif B. Muller

Top-down feedback is ubiquitous in the brain and computationally distinct, but rarely modeled in deep neural networks. What happens when a DNN has biologically-inspired top-down feedback? 🧠📈
Our new paper explores this: elifesciences.org/reviewed-pre...
Our new paper explores this: elifesciences.org/reviewed-pre...
Top-down feedback matters: Functional impact of brainlike connectivity motifs on audiovisual integration
elifesciences.org
April 15, 2025 at 8:11 PM
Top-down feedback is ubiquitous in the brain and computationally distinct, but rarely modeled in deep neural networks. What happens when a DNN has biologically-inspired top-down feedback? 🧠📈
Our new paper explores this: elifesciences.org/reviewed-pre...
Our new paper explores this: elifesciences.org/reviewed-pre...
Reposted by Eilif B. Muller

After a great conference in Boston, CCN is going to take place in Amsterdam in 2025! To help the exchange of ideas between #neuroscience, cognitive science, and #AI, CCN will for the first time have full length paper submissions (alongside the established 2 pagers)! Info below👇
#NeuroAI #CompNeuro
#NeuroAI #CompNeuro

November 12, 2024 at 9:27 AM
After a great conference in Boston, CCN is going to take place in Amsterdam in 2025! To help the exchange of ideas between #neuroscience, cognitive science, and #AI, CCN will for the first time have full length paper submissions (alongside the established 2 pagers)! Info below👇
#NeuroAI #CompNeuro
#NeuroAI #CompNeuro
1/2 Migrating to Bsky, and following @elife.bsky.social I notice our 2 big papers on simulation of neocortical circuits are at the top of the feed!

Multi-part study presenting modelling and simulation of neocortical micro- and mesocircuitry.
https://buff.ly/4fO2ps5
https://buff.ly/3CBRint
https://buff.ly/4fO2ps5
https://buff.ly/3CBRint

November 15, 2024 at 7:12 AM
1/2 Migrating to Bsky, and following @elife.bsky.social I notice our 2 big papers on simulation of neocortical circuits are at the top of the feed!
Have been off twitter for over a year, tried mastadon ... Bsky looks more like its in the goldilocks zone. Migrated my network using "Sky Follower Bridge"
www.zdnet.com/article/how-...
or is there a better approach? I recall a "NeuroMigration" movement for mastadon ...
www.zdnet.com/article/how-...
or is there a better approach? I recall a "NeuroMigration" movement for mastadon ...

How to migrate from X to Bluesky without losing your followers
This extension lets you easily migrate your follows and block list from X (formerly Twitter) to Bluesky, but you need to act fast because its functionality may be short-lived. Here's why.
www.zdnet.com
November 15, 2024 at 7:00 AM
Have been off twitter for over a year, tried mastadon ... Bsky looks more like its in the goldilocks zone. Migrated my network using "Sky Follower Bridge"
www.zdnet.com/article/how-...
or is there a better approach? I recall a "NeuroMigration" movement for mastadon ...
www.zdnet.com/article/how-...
or is there a better approach? I recall a "NeuroMigration" movement for mastadon ...
Reposted by Eilif B. Muller

A little late on the 🦋🚂, but happy to share a new(ish) preprint - the culmination of three years of postdoc with @tyrellturing.bsky.social and @apeyrache.bsky.social, and my first real foray into #NeuroAI as a tool to study the sleeping brain 🧠🟦:
biorxiv.org/content/10.1...
(1/🧵) c’est parti!
biorxiv.org/content/10.1...
(1/🧵) c’est parti!

Sequential predictive learning is a unifying theory for hippocampal representation and replay
bioRxiv - the preprint server for biology, operated by Cold Spring Harbor Laboratory, a research and educational institution
biorxiv.org
August 15, 2024 at 2:37 PM
A little late on the 🦋🚂, but happy to share a new(ish) preprint - the culmination of three years of postdoc with @tyrellturing.bsky.social and @apeyrache.bsky.social, and my first real foray into #NeuroAI as a tool to study the sleeping brain 🧠🟦:
biorxiv.org/content/10.1...
(1/🧵) c’est parti!
biorxiv.org/content/10.1...
(1/🧵) c’est parti!