




Ian Magnusson
@ianmagnusson.bsky.social
Science of language models @uwnlp.bsky.social and @ai2.bsky.social with @PangWeiKoh and @nlpnoah.bsky.social. https://ianmagnusson.github.io
Pinned
Ian Magnusson
@ianmagnusson.bsky.social
· Apr 15
Ever wonder how LLM developers choose their pretraining data? It’s not guesswork— all AI labs create small-scale models as experiments, but the models and their data are rarely shared.
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
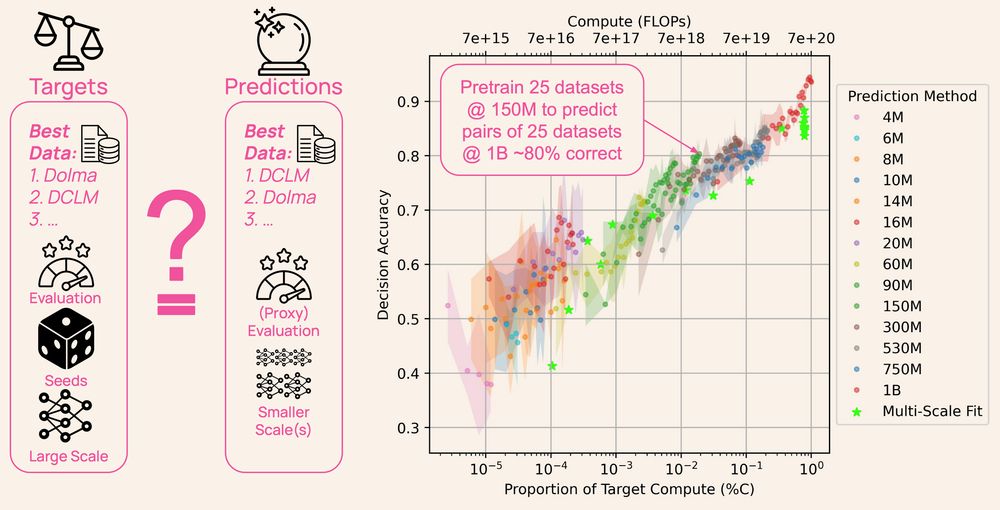
🔭 Science relies on shared artifacts collected for the common good.
🛰 So we asked: what's missing in open language modeling?
🪐 DataDecide 🌌 charts the cosmos of pretraining—across scales and corpora—at a resolution beyond any public suite of models that has come before.
🛰 So we asked: what's missing in open language modeling?
🪐 DataDecide 🌌 charts the cosmos of pretraining—across scales and corpora—at a resolution beyond any public suite of models that has come before.
Reposted by Ian Magnusson

Evaluating language models is tricky, how do we know if our results are real, or due to random chance?
We find an answer with two simple metrics: signal, a benchmark’s ability to separate models, and noise, a benchmark’s random variability between training steps 🧵
We find an answer with two simple metrics: signal, a benchmark’s ability to separate models, and noise, a benchmark’s random variability between training steps 🧵

August 19, 2025 at 4:46 PM
Evaluating language models is tricky, how do we know if our results are real, or due to random chance?
We find an answer with two simple metrics: signal, a benchmark’s ability to separate models, and noise, a benchmark’s random variability between training steps 🧵
We find an answer with two simple metrics: signal, a benchmark’s ability to separate models, and noise, a benchmark’s random variability between training steps 🧵
Reposted by Ian Magnusson

📢 New #COLM2025 paper 📢
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵

September 16, 2025 at 5:16 PM
📢 New #COLM2025 paper 📢
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
Reposted by Ian Magnusson

🚀 Introducing Fluid Benchmarking—an adaptive way to evaluate LLMs. Inspired by psychometrics, it tailors which questions to ask based on each model’s capability, making evals more efficient & reliable. 🧵

September 16, 2025 at 4:08 PM
🚀 Introducing Fluid Benchmarking—an adaptive way to evaluate LLMs. Inspired by psychometrics, it tailors which questions to ask based on each model’s capability, making evals more efficient & reliable. 🧵
🔭 Science relies on shared artifacts collected for the common good.
🛰 So we asked: what's missing in open language modeling?
🪐 DataDecide 🌌 charts the cosmos of pretraining—across scales and corpora—at a resolution beyond any public suite of models that has come before.
🛰 So we asked: what's missing in open language modeling?
🪐 DataDecide 🌌 charts the cosmos of pretraining—across scales and corpora—at a resolution beyond any public suite of models that has come before.
Ever wonder how LLM developers choose their pretraining data? It’s not guesswork— all AI labs create small-scale models as experiments, but the models and their data are rarely shared.
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
April 15, 2025 at 1:08 PM
🔭 Science relies on shared artifacts collected for the common good.
🛰 So we asked: what's missing in open language modeling?
🪐 DataDecide 🌌 charts the cosmos of pretraining—across scales and corpora—at a resolution beyond any public suite of models that has come before.
🛰 So we asked: what's missing in open language modeling?
🪐 DataDecide 🌌 charts the cosmos of pretraining—across scales and corpora—at a resolution beyond any public suite of models that has come before.
Reposted by Ian Magnusson

Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting?
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
April 9, 2025 at 1:37 PM
Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
Reposted by Ian Magnusson

🚨I too am on the job market‼️🤯
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me

December 6, 2024 at 1:44 AM
🚨I too am on the job market‼️🤯
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me
I'm searching for faculty positions/postdocs in multilingual/multicultural NLP, vision+language models, and eval for genAI!
I'll be at #NeurIPS2024 presenting our work on meta-evaluation for text-to-image faithfulness! Let's chat there!
Papers in🧵, see more: saxon.me
Reposted by Ian Magnusson

the science of LMs should be fully open✨
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
NeurIPS Tutorial Opening the Language Model Pipeline: A Tutorial on Data Preparation, Model Training, and AdaptationNeurIPS 2024
neurips.cc
December 10, 2024 at 3:31 PM
the science of LMs should be fully open✨
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
Reposted by Ian Magnusson


Reposted by Ian Magnusson
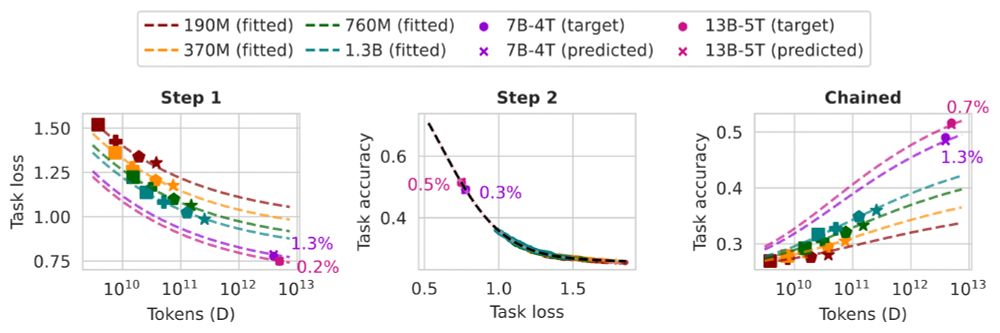
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
December 9, 2024 at 5:07 PM
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
Reposted by Ian Magnusson

Excited to be at #NeurIPS next week in 🇨🇦! Please reach out if you want to chat about LM post-training (Tülu!), data curation, or anything else :)
I'll be around all week, with two papers you should go check out (see image or next tweet):
I'll be around all week, with two papers you should go check out (see image or next tweet):

December 2, 2024 at 6:53 PM
Excited to be at #NeurIPS next week in 🇨🇦! Please reach out if you want to chat about LM post-training (Tülu!), data curation, or anything else :)
I'll be around all week, with two papers you should go check out (see image or next tweet):
I'll be around all week, with two papers you should go check out (see image or next tweet):
Reposted by Ian Magnusson

Touching down in Vancouver 🛬 for #NeurIPS2024!
I'll be presenting our "Consent in Crisis" work on the 11th: arxiv.org/abs/2407.14933
Reach out to catch up or chat about:
- Training data / methods
- AI uses & impacts
- Multilingual scaling
I'll be presenting our "Consent in Crisis" work on the 11th: arxiv.org/abs/2407.14933
Reach out to catch up or chat about:
- Training data / methods
- AI uses & impacts
- Multilingual scaling

Consent in Crisis: The Rapid Decline of the AI Data Commons
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, ...
arxiv.org
December 7, 2024 at 7:27 PM
Touching down in Vancouver 🛬 for #NeurIPS2024!
I'll be presenting our "Consent in Crisis" work on the 11th: arxiv.org/abs/2407.14933
Reach out to catch up or chat about:
- Training data / methods
- AI uses & impacts
- Multilingual scaling
I'll be presenting our "Consent in Crisis" work on the 11th: arxiv.org/abs/2407.14933
Reach out to catch up or chat about:
- Training data / methods
- AI uses & impacts
- Multilingual scaling
Come chat with me at #NeurIPS2024 and learn about how to use Paloma to evaluate perplexity over hundreds of domains! ✨We have stickers too✨

December 10, 2024 at 3:54 AM
Come chat with me at #NeurIPS2024 and learn about how to use Paloma to evaluate perplexity over hundreds of domains! ✨We have stickers too✨
Reposted by Ian Magnusson

Building/customizing your own LLM? You'll want to curate training data for it, but how do you know what makes the data good?
You can try out recipes👩🍳 iterate on ✨vibes✨ but we can't actually test all possible combos of tweaks,,, right?? 🙅♂️WRONG! arxiv.org/abs/2410.15661 (1/n) 🧵
You can try out recipes👩🍳 iterate on ✨vibes✨ but we can't actually test all possible combos of tweaks,,, right?? 🙅♂️WRONG! arxiv.org/abs/2410.15661 (1/n) 🧵

November 5, 2024 at 10:37 PM
Building/customizing your own LLM? You'll want to curate training data for it, but how do you know what makes the data good?
You can try out recipes👩🍳 iterate on ✨vibes✨ but we can't actually test all possible combos of tweaks,,, right?? 🙅♂️WRONG! arxiv.org/abs/2410.15661 (1/n) 🧵
You can try out recipes👩🍳 iterate on ✨vibes✨ but we can't actually test all possible combos of tweaks,,, right?? 🙅♂️WRONG! arxiv.org/abs/2410.15661 (1/n) 🧵
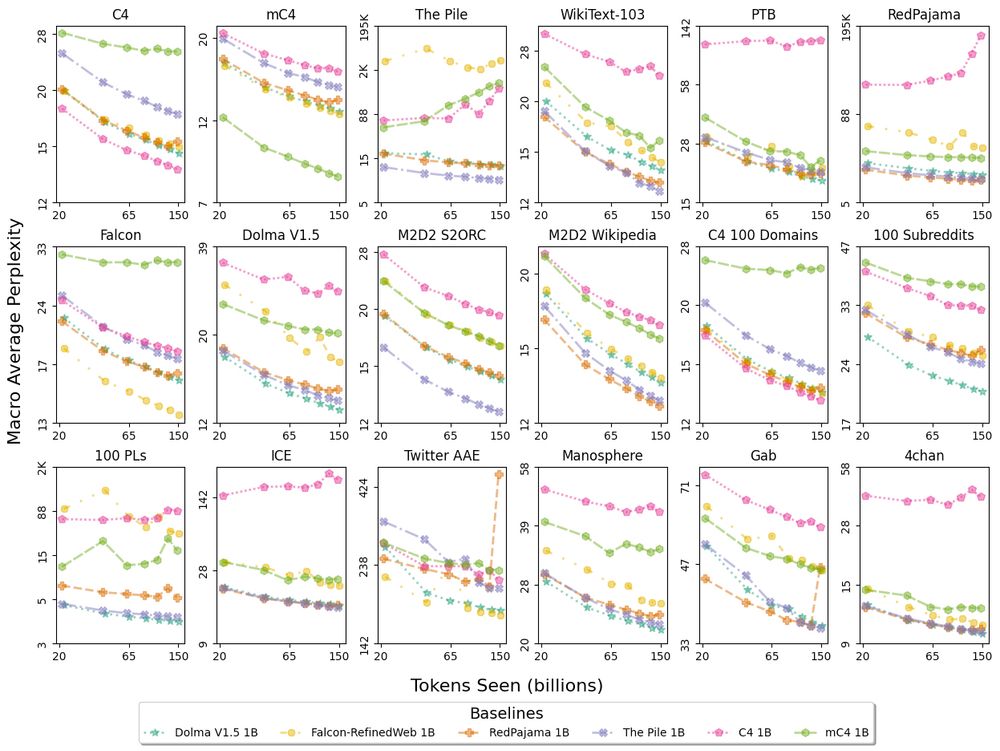
LMs are used to process text from many topics, styles, dialects, etc., but how well do they do?
📈 Evaluating perplexity on just one corpus like C4 doesn't tell the whole story 📉
✨📃✨
We introduce Paloma, a benchmark of 585 domains from NY Times to r/depression on Reddit.
📈 Evaluating perplexity on just one corpus like C4 doesn't tell the whole story 📉
✨📃✨
We introduce Paloma, a benchmark of 585 domains from NY Times to r/depression on Reddit.
December 20, 2023 at 8:28 PM
LMs are used to process text from many topics, styles, dialects, etc., but how well do they do?
📈 Evaluating perplexity on just one corpus like C4 doesn't tell the whole story 📉
✨📃✨
We introduce Paloma, a benchmark of 585 domains from NY Times to r/depression on Reddit.
📈 Evaluating perplexity on just one corpus like C4 doesn't tell the whole story 📉
✨📃✨
We introduce Paloma, a benchmark of 585 domains from NY Times to r/depression on Reddit.