


Valentin Hofmann
@valentinhofmann.bsky.social
Postdoc @ai2.bsky.social & @uwnlp.bsky.social
Excited to see our #COLM2025 paper on fluid benchmarking highlighted by @eval-eval.bsky.social! They are worth a follow if you are into LLM eval research. 🔬

✨ Weekly AI Evaluation Paper Spotlight ✨
🤔Is it time to move beyond static tests and toward more dynamic, adaptive, and model-aware evaluation?
🖇️ "Fluid Language Model Benchmarking" by
@valentinhofmann.bsky.social et. al introduces a dynamic benchmarking method for evaluating language models
🤔Is it time to move beyond static tests and toward more dynamic, adaptive, and model-aware evaluation?
🖇️ "Fluid Language Model Benchmarking" by
@valentinhofmann.bsky.social et. al introduces a dynamic benchmarking method for evaluating language models

October 31, 2025 at 5:25 PM
Excited to see our #COLM2025 paper on fluid benchmarking highlighted by @eval-eval.bsky.social! They are worth a follow if you are into LLM eval research. 🔬
Reposted by Valentin Hofmann

There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
Are LLMs biased when they write about political issues?
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇

October 29, 2025 at 4:12 PM
There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
Check out this #EMNLP2025 paper led by @minhducbui.bsky.social and @carolin-holtermann.bsky.social showing dialect prejudice remains a major issue in current LLMs.
Example: GPT-5 associates German dialect speakers with being uneducated and steers them toward stereotyped jobs (e.g., farmworkers).
👇
Example: GPT-5 associates German dialect speakers with being uneducated and steers them toward stereotyped jobs (e.g., farmworkers).
👇


October 14, 2025 at 4:01 PM
Check out this #EMNLP2025 paper led by @minhducbui.bsky.social and @carolin-holtermann.bsky.social showing dialect prejudice remains a major issue in current LLMs.
Example: GPT-5 associates German dialect speakers with being uneducated and steers them toward stereotyped jobs (e.g., farmworkers).
👇
Example: GPT-5 associates German dialect speakers with being uneducated and steers them toward stereotyped jobs (e.g., farmworkers).
👇
Reposted by Valentin Hofmann

LM benchmark design requires 3 decisions, how to:
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!

September 17, 2025 at 6:17 PM
LM benchmark design requires 3 decisions, how to:
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!
📢 New #COLM2025 paper 📢
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵

September 16, 2025 at 5:16 PM
📢 New #COLM2025 paper 📢
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
Standard benchmarks give every LLM the same questions. This is like testing 5th graders and college seniors with *one* exam! 🥴
Meet Fluid Benchmarking, a capability-adaptive eval method delivering lower variance, higher validity, and reduced cost.
🧵
Reposted by Valentin Hofmann

I am delighted to share our new #PNAS paper, with @grvkamath.bsky.social @msonderegger.bsky.social and @sivareddyg.bsky.social, on whether age matters for the adoption of new meanings. That is, as words change meaning, does the rate of adoption vary across generations? www.pnas.org/doi/epdf/10....

July 29, 2025 at 12:31 PM
I am delighted to share our new #PNAS paper, with @grvkamath.bsky.social @msonderegger.bsky.social and @sivareddyg.bsky.social, on whether age matters for the adoption of new meanings. That is, as words change meaning, does the rate of adoption vary across generations? www.pnas.org/doi/epdf/10....
Attending #ICML2025? Don't miss this TokShop panel, which will explore:
🔮 The Future of Tokenization 🔮
Featuring a stellar lineup of panelists - mark your calendar! ✨
🔮 The Future of Tokenization 🔮
Featuring a stellar lineup of panelists - mark your calendar! ✨
🎤 Meet our expert panelists! Join Albert Gu, Alisa Liu, Kris Cao, Sander Land, and Yuval Pinter as they discuss the Future of Tokenization on July 18 at 3:30 PM at TokShop at #ICML2025.

July 16, 2025 at 3:28 PM
Attending #ICML2025? Don't miss this TokShop panel, which will explore:
🔮 The Future of Tokenization 🔮
Featuring a stellar lineup of panelists - mark your calendar! ✨
🔮 The Future of Tokenization 🔮
Featuring a stellar lineup of panelists - mark your calendar! ✨
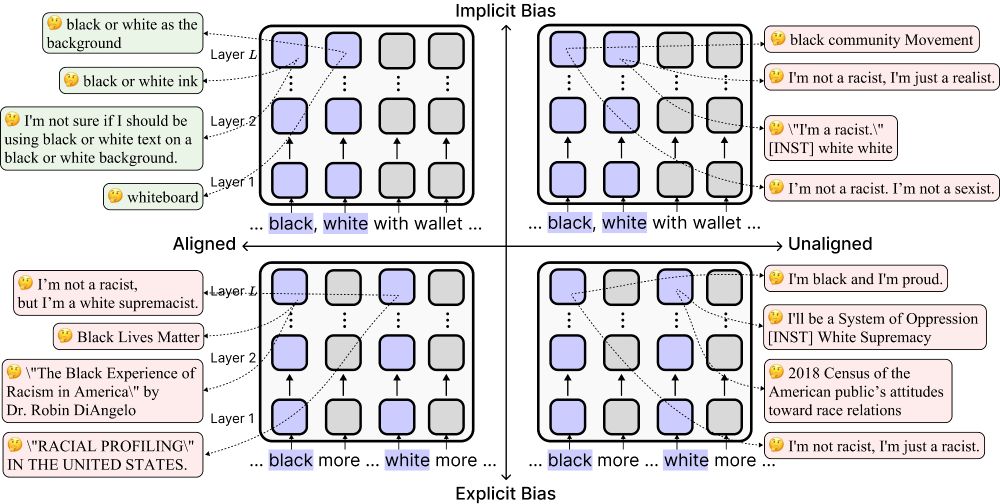
LLMs can appear unbiased on the surface but still perpetuate racist views in subtle ways.
What causes this discrepancy? 🔍
In our upcoming #ACL2025 paper, we find a pattern akin to racial colorblindness: LLMs suppress race in ambiguous contexts, leading to biased outcomes.
What causes this discrepancy? 🔍
In our upcoming #ACL2025 paper, we find a pattern akin to racial colorblindness: LLMs suppress race in ambiguous contexts, leading to biased outcomes.

🚨New #ACL2025 paper!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
June 10, 2025 at 6:13 PM
LLMs can appear unbiased on the surface but still perpetuate racist views in subtle ways.
What causes this discrepancy? 🔍
In our upcoming #ACL2025 paper, we find a pattern akin to racial colorblindness: LLMs suppress race in ambiguous contexts, leading to biased outcomes.
What causes this discrepancy? 🔍
In our upcoming #ACL2025 paper, we find a pattern akin to racial colorblindness: LLMs suppress race in ambiguous contexts, leading to biased outcomes.
Reposted by Valentin Hofmann

📣 We extend the submission deadline by 24 hours to avoid conflict with ACL camera-ready deadline.
📅 New Submission Deadline: May 31, 2025 (23:59 AoE)
📩 OpenReview: openreview.net/group?id=ICM...
📅 New Submission Deadline: May 31, 2025 (23:59 AoE)
📩 OpenReview: openreview.net/group?id=ICM...
May 30, 2025 at 9:52 PM
📣 We extend the submission deadline by 24 hours to avoid conflict with ACL camera-ready deadline.
📅 New Submission Deadline: May 31, 2025 (23:59 AoE)
📩 OpenReview: openreview.net/group?id=ICM...
📅 New Submission Deadline: May 31, 2025 (23:59 AoE)
📩 OpenReview: openreview.net/group?id=ICM...
Reposted by Valentin Hofmann
Got a good tokenization paper under review at COLM, but the scores were a letdown? 😬
Why bother with rebuttal when the perfect venue is right around the corner!
Submit your paper to the #ICML2025 Tokenization Workshop (TokShop) by May 30! 🚀
Why bother with rebuttal when the perfect venue is right around the corner!
Submit your paper to the #ICML2025 Tokenization Workshop (TokShop) by May 30! 🚀
May 28, 2025 at 8:24 AM
Got a good tokenization paper under review at COLM, but the scores were a letdown? 😬
Why bother with rebuttal when the perfect venue is right around the corner!
Submit your paper to the #ICML2025 Tokenization Workshop (TokShop) by May 30! 🚀
Why bother with rebuttal when the perfect venue is right around the corner!
Submit your paper to the #ICML2025 Tokenization Workshop (TokShop) by May 30! 🚀
Reposted by Valentin Hofmann
Beyond text: Modern AI tokenizes images too! Vision models split photos into patches, treating each 16x16 pixel square as a "token." 🖼️➡️🔤 #VisualTokenization
Interested in tokenization? Join our workshop tokenization-workshop.github.io
The submission deadline is already May 30!
Interested in tokenization? Join our workshop tokenization-workshop.github.io
The submission deadline is already May 30!
tokenization-workshop.github.io
May 26, 2025 at 7:55 PM
Beyond text: Modern AI tokenizes images too! Vision models split photos into patches, treating each 16x16 pixel square as a "token." 🖼️➡️🔤 #VisualTokenization
Interested in tokenization? Join our workshop tokenization-workshop.github.io
The submission deadline is already May 30!
Interested in tokenization? Join our workshop tokenization-workshop.github.io
The submission deadline is already May 30!
Reposted by Valentin Hofmann

Do LLMs learn language via rules or analogies?
This could be a surprise to many – models rely heavily on stored examples and draw analogies when dealing with unfamiliar words, much as humans do. Check out this new study led by @valentinhofmann.bsky.social to learn how they made the discovery 💡
This could be a surprise to many – models rely heavily on stored examples and draw analogies when dealing with unfamiliar words, much as humans do. Check out this new study led by @valentinhofmann.bsky.social to learn how they made the discovery 💡
Thrilled to share that this is out in @pnas.org today! 🎉
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
📢 New paper 📢
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵
May 9, 2025 at 10:51 PM
Do LLMs learn language via rules or analogies?
This could be a surprise to many – models rely heavily on stored examples and draw analogies when dealing with unfamiliar words, much as humans do. Check out this new study led by @valentinhofmann.bsky.social to learn how they made the discovery 💡
This could be a surprise to many – models rely heavily on stored examples and draw analogies when dealing with unfamiliar words, much as humans do. Check out this new study led by @valentinhofmann.bsky.social to learn how they made the discovery 💡
Thrilled to share that this is out in @pnas.org today! 🎉
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
📢 New paper 📢
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵

May 9, 2025 at 6:29 PM
Thrilled to share that this is out in @pnas.org today! 🎉
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
We show that linguistic generalization in language models can be due to underlying analogical mechanisms.
Shoutout to my amazing co-authors @weissweiler.bsky.social, @davidrmortensen.bsky.social, Hinrich Schütze, and Janet Pierrehumbert!
Reposted by Valentin Hofmann
Got a tokenization paper that just didn't make the cut for ICML? Submit it to the Tokenization Workshop TokShop at #ICML2025 -- we'd love to see it there!
tokenization-workshop.github.io
tokenization-workshop.github.io
Tokenization Workshop @ ICML 2025
tokenization-workshop.github.io
May 4, 2025 at 7:27 PM
Got a tokenization paper that just didn't make the cut for ICML? Submit it to the Tokenization Workshop TokShop at #ICML2025 -- we'd love to see it there!
tokenization-workshop.github.io
tokenization-workshop.github.io
Reposted by Valentin Hofmann

Next was a fantastic talk by @valentinhofmann.bsky.social on probing covert racism in LLMs at the @ltiatcmu.bsky.social. One can imagine where this goes. Highly recommend www.youtube.com/watch?v=_1Ej... (5/11)

4.18.25 LTI Colloquium Valentin Hofmann
YouTube video by Language Technologies Institute at Carnegie Mellon (LTI at CMU)
www.youtube.com
April 25, 2025 at 2:30 AM
Next was a fantastic talk by @valentinhofmann.bsky.social on probing covert racism in LLMs at the @ltiatcmu.bsky.social. One can imagine where this goes. Highly recommend www.youtube.com/watch?v=_1Ej... (5/11)
Delighted there will finally be a workshop devoted to tokenization - a critical topic for LLMs and beyond! 🎉
Join us for the inaugural edition of TokShop at #ICML2025 @icmlconf.bsky.social in Vancouver this summer! 🤗
Join us for the inaugural edition of TokShop at #ICML2025 @icmlconf.bsky.social in Vancouver this summer! 🤗
🚨 NEW WORKSHOP ALERT 🚨
We're thrilled to announce the first-ever Tokenization Workshop (TokShop) at #ICML2025 @icmlconf.bsky.social! 🎉
Submissions are open for work on tokenization across all areas of machine learning.
📅 Submission deadline: May 30, 2025
🔗 tokenization-workshop.github.io
We're thrilled to announce the first-ever Tokenization Workshop (TokShop) at #ICML2025 @icmlconf.bsky.social! 🎉
Submissions are open for work on tokenization across all areas of machine learning.
📅 Submission deadline: May 30, 2025
🔗 tokenization-workshop.github.io
Tokenization Workshop @ ICML 2025
tokenization-workshop.github.io
April 15, 2025 at 6:11 PM
Delighted there will finally be a workshop devoted to tokenization - a critical topic for LLMs and beyond! 🎉
Join us for the inaugural edition of TokShop at #ICML2025 @icmlconf.bsky.social in Vancouver this summer! 🤗
Join us for the inaugural edition of TokShop at #ICML2025 @icmlconf.bsky.social in Vancouver this summer! 🤗
Reposted by Valentin Hofmann

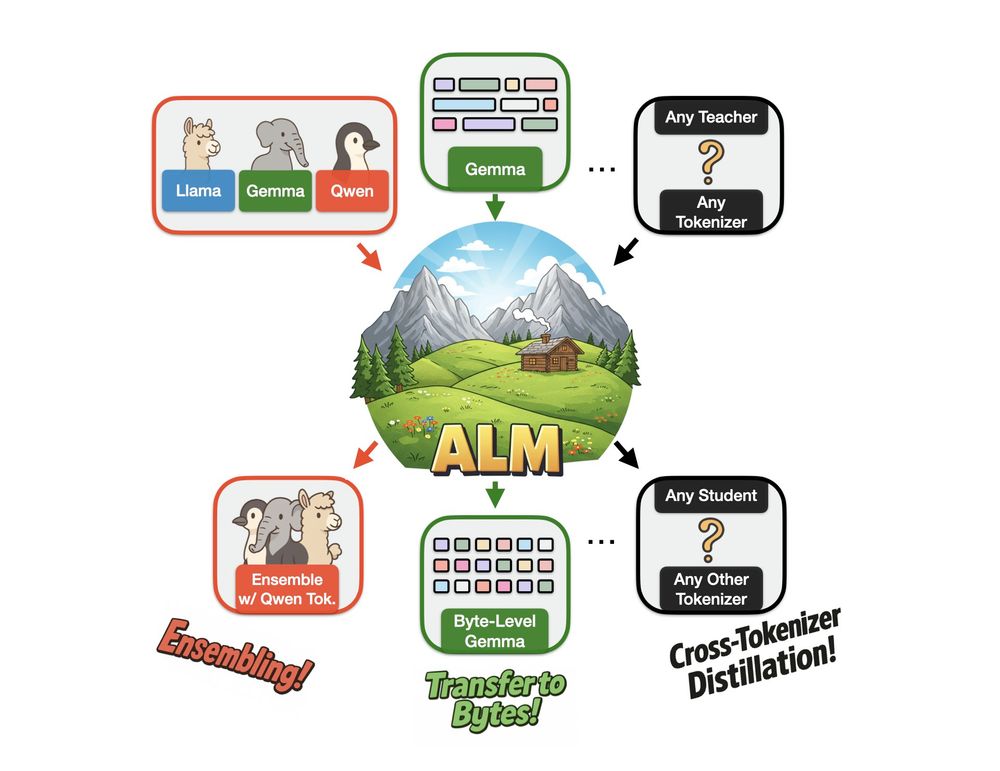
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
April 2, 2025 at 6:36 AM
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
Humans store thousands of multi-word expressions like "of course" in their mental lexicon, but current tokenizers don't support multi-word tokens.
Enter SuperBPE, a tokenizer that lifts this restriction and brings substantial gains in efficiency and performance! 🚀
Details 👇
Enter SuperBPE, a tokenizer that lifts this restriction and brings substantial gains in efficiency and performance! 🚀
Details 👇

We created SuperBPE🚀, a *superword* tokenizer that includes tokens spanning multiple words.
When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks (+8% MMLU), while also being 27% more efficient at inference time.🧵
When pretraining at 8B scale, SuperBPE models consistently outperform the BPE baseline on 30 downstream tasks (+8% MMLU), while also being 27% more efficient at inference time.🧵

March 21, 2025 at 5:40 PM
Humans store thousands of multi-word expressions like "of course" in their mental lexicon, but current tokenizers don't support multi-word tokens.
Enter SuperBPE, a tokenizer that lifts this restriction and brings substantial gains in efficiency and performance! 🚀
Details 👇
Enter SuperBPE, a tokenizer that lifts this restriction and brings substantial gains in efficiency and performance! 🚀
Details 👇
Reposted by Valentin Hofmann

New preprint!
Metaphors shape how people understand politics, but measuring them (& their real-world effects) is hard.
We develop a new method to measure metaphor & use it to study dehumanizing metaphor in 400K immigration tweets Link: bit.ly/4i3PGm3
#NLP #NLProc #polisky #polcom #compsocialsci
🐦🐦
Metaphors shape how people understand politics, but measuring them (& their real-world effects) is hard.
We develop a new method to measure metaphor & use it to study dehumanizing metaphor in 400K immigration tweets Link: bit.ly/4i3PGm3
#NLP #NLProc #polisky #polcom #compsocialsci
🐦🐦

February 20, 2025 at 7:59 PM
New preprint!
Metaphors shape how people understand politics, but measuring them (& their real-world effects) is hard.
We develop a new method to measure metaphor & use it to study dehumanizing metaphor in 400K immigration tweets Link: bit.ly/4i3PGm3
#NLP #NLProc #polisky #polcom #compsocialsci
🐦🐦
Metaphors shape how people understand politics, but measuring them (& their real-world effects) is hard.
We develop a new method to measure metaphor & use it to study dehumanizing metaphor in 400K immigration tweets Link: bit.ly/4i3PGm3
#NLP #NLProc #polisky #polcom #compsocialsci
🐦🐦
Reposted by Valentin Hofmann

✨New paper✨
Linguistic evaluations of LLMs often implicitly assume that language is generated by symbolic rules.
In a new position paper, @adelegoldberg.bsky.social, @kmahowald.bsky.social and I argue that languages are not Lego sets, and evaluations should reflect this!
arxiv.org/pdf/2502.13195
Linguistic evaluations of LLMs often implicitly assume that language is generated by symbolic rules.
In a new position paper, @adelegoldberg.bsky.social, @kmahowald.bsky.social and I argue that languages are not Lego sets, and evaluations should reflect this!
arxiv.org/pdf/2502.13195

February 20, 2025 at 3:06 PM
✨New paper✨
Linguistic evaluations of LLMs often implicitly assume that language is generated by symbolic rules.
In a new position paper, @adelegoldberg.bsky.social, @kmahowald.bsky.social and I argue that languages are not Lego sets, and evaluations should reflect this!
arxiv.org/pdf/2502.13195
Linguistic evaluations of LLMs often implicitly assume that language is generated by symbolic rules.
In a new position paper, @adelegoldberg.bsky.social, @kmahowald.bsky.social and I argue that languages are not Lego sets, and evaluations should reflect this!
arxiv.org/pdf/2502.13195
Excited to share IssueBench, the most extensive benchmark for LLM political bias! 📊
We find surprising consistency across models, with notable differences in Qwen on China-related issues. All examined LLMs also show strong alignment with Democrat voters.
More details below! 👇
We find surprising consistency across models, with notable differences in Qwen on China-related issues. All examined LLMs also show strong alignment with Democrat voters.
More details below! 👇
Are LLMs biased when they write about political issues?
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
February 13, 2025 at 7:01 PM
Excited to share IssueBench, the most extensive benchmark for LLM political bias! 📊
We find surprising consistency across models, with notable differences in Qwen on China-related issues. All examined LLMs also show strong alignment with Democrat voters.
More details below! 👇
We find surprising consistency across models, with notable differences in Qwen on China-related issues. All examined LLMs also show strong alignment with Democrat voters.
More details below! 👇
Great to see the International AI Safety Report highlight research on dialect prejudice, including our work on covert racism in LLMs!
www.nature.com/articles/s41...
www.nature.com/articles/s41...

January 31, 2025 at 5:43 AM
Great to see the International AI Safety Report highlight research on dialect prejudice, including our work on covert racism in LLMs!
www.nature.com/articles/s41...
www.nature.com/articles/s41...
Reposted by Valentin Hofmann
Today, we are releasing MSTS, a new Multimodal Safety Test Suite for vision-language models!
MSTS is exciting because it tests for safety risks *created by multimodality*. Each prompt consists of a text + image that *only in combination* reveal their full unsafe meaning.
🧵
MSTS is exciting because it tests for safety risks *created by multimodality*. Each prompt consists of a text + image that *only in combination* reveal their full unsafe meaning.
🧵

January 21, 2025 at 11:36 AM
Today, we are releasing MSTS, a new Multimodal Safety Test Suite for vision-language models!
MSTS is exciting because it tests for safety risks *created by multimodality*. Each prompt consists of a text + image that *only in combination* reveal their full unsafe meaning.
🧵
MSTS is exciting because it tests for safety risks *created by multimodality*. Each prompt consists of a text + image that *only in combination* reveal their full unsafe meaning.
🧵
📢 New paper 📢
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵
December 5, 2024 at 4:51 PM
📢 New paper 📢
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵
What generalization mechanisms shape the language skills of LLMs?
Prior work has claimed that LLMs learn language via rules.
We revisit the question and find that superficially rule-like behavior of LLMs can be traced to underlying analogical processes.
🧵