



Benjamin Minixhofer
@bminixhofer.bsky.social
Reposted by Benjamin Minixhofer

Instruction tuning unlocks incredible skills in LLMs, but at a cost: they become dangerously overconfident.
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
October 30, 2025 at 5:00 PM
Instruction tuning unlocks incredible skills in LLMs, but at a cost: they become dangerously overconfident.
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
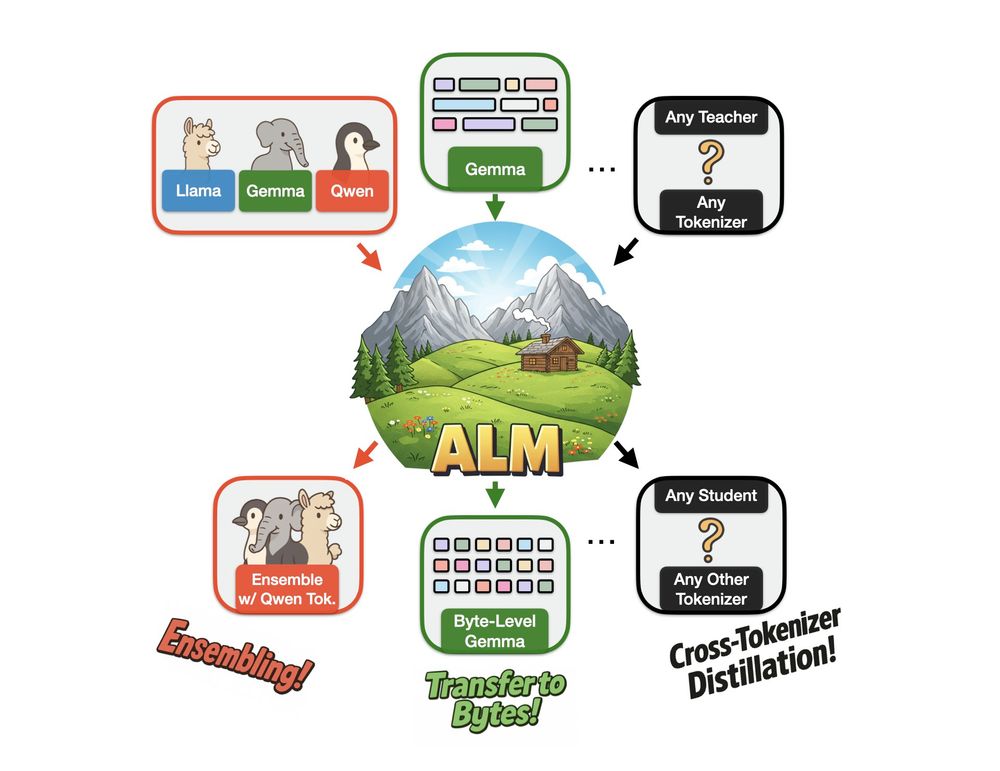
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
April 2, 2025 at 6:36 AM
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
Reposted by Benjamin Minixhofer

Two amazing papers from my students at #NeurIPS today:
⛓️💥 Switch the vocabulary and embeddings of your LLM tokenizer zero-shot on the fly (@bminixhofer.bsky.social)
neurips.cc/virtual/2024...
🌊 Align your LLM gradient-free with spectral editing of activations (Yifu Qiu)
neurips.cc/virtual/2024...
December 12, 2024 at 5:45 PM
Two amazing papers from my students at #NeurIPS today:
⛓️💥 Switch the vocabulary and embeddings of your LLM tokenizer zero-shot on the fly (@bminixhofer.bsky.social)
neurips.cc/virtual/2024...
🌊 Align your LLM gradient-free with spectral editing of activations (Yifu Qiu)
neurips.cc/virtual/2024...