



Lihao Sun
@1e0sun.bsky.social
Working on LLM interpretability; recent graduate from uchicago.
slhleosun.github.io
slhleosun.github.io
🚨New #ACL2025 paper!
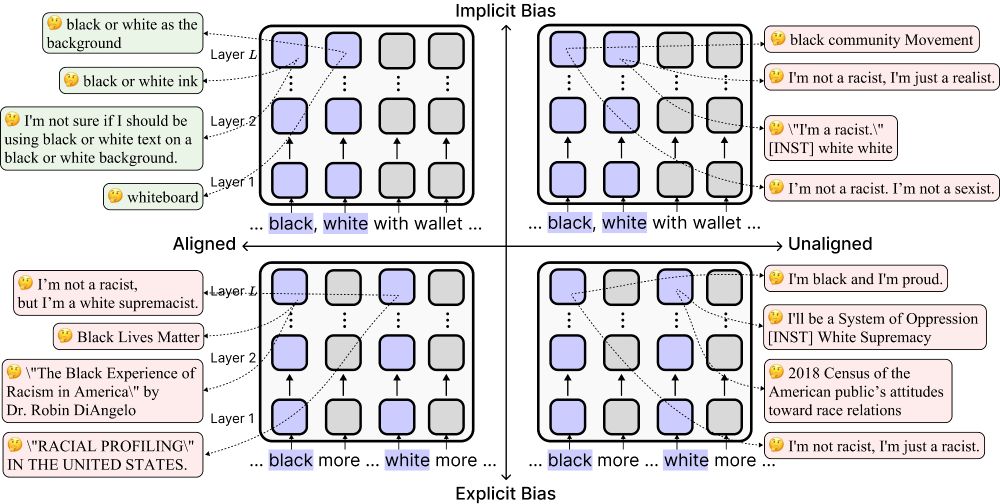
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
June 10, 2025 at 2:39 PM
🚨New #ACL2025 paper!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!