



Lihao Sun
@1e0sun.bsky.social
Working on LLM interpretability; recent graduate from uchicago.
slhleosun.github.io
slhleosun.github.io
7/
📢 Accepted to #ACL2025 Main Conference! See you in Vienna.
Work done by @1e0sun.bsky.social, Chengzhi Mao, @valentinhofmann.bsky.social, Xuechunzi Bai.
Paper: arxiv.org/abs/2506.00253
Project page: slhleosun.github.io/aligned_but_...
Code & Data: github.com/slhleosun/al...
📢 Accepted to #ACL2025 Main Conference! See you in Vienna.
Work done by @1e0sun.bsky.social, Chengzhi Mao, @valentinhofmann.bsky.social, Xuechunzi Bai.
Paper: arxiv.org/abs/2506.00253
Project page: slhleosun.github.io/aligned_but_...
Code & Data: github.com/slhleosun/al...

June 10, 2025 at 2:39 PM
7/
📢 Accepted to #ACL2025 Main Conference! See you in Vienna.
Work done by @1e0sun.bsky.social, Chengzhi Mao, @valentinhofmann.bsky.social, Xuechunzi Bai.
Paper: arxiv.org/abs/2506.00253
Project page: slhleosun.github.io/aligned_but_...
Code & Data: github.com/slhleosun/al...
📢 Accepted to #ACL2025 Main Conference! See you in Vienna.
Work done by @1e0sun.bsky.social, Chengzhi Mao, @valentinhofmann.bsky.social, Xuechunzi Bai.
Paper: arxiv.org/abs/2506.00253
Project page: slhleosun.github.io/aligned_but_...
Code & Data: github.com/slhleosun/al...
4/
Inspired by these results, we tested the opposite of “machine unlearning” for debiasing.
What if we reinforced race concepts in models?
- Injecting race-laden activations cut implicit bias by 54.9%.
- LoRA fine-tuning brought it down from 97.3% → 42.4%.
Bonus: also lowered explicit bias.
Inspired by these results, we tested the opposite of “machine unlearning” for debiasing.
What if we reinforced race concepts in models?
- Injecting race-laden activations cut implicit bias by 54.9%.
- LoRA fine-tuning brought it down from 97.3% → 42.4%.
Bonus: also lowered explicit bias.

June 10, 2025 at 2:39 PM
4/
Inspired by these results, we tested the opposite of “machine unlearning” for debiasing.
What if we reinforced race concepts in models?
- Injecting race-laden activations cut implicit bias by 54.9%.
- LoRA fine-tuning brought it down from 97.3% → 42.4%.
Bonus: also lowered explicit bias.
Inspired by these results, we tested the opposite of “machine unlearning” for debiasing.
What if we reinforced race concepts in models?
- Injecting race-laden activations cut implicit bias by 54.9%.
- LoRA fine-tuning brought it down from 97.3% → 42.4%.
Bonus: also lowered explicit bias.
3/
We mechanistically tested this using activation patching and embedding interpretation.
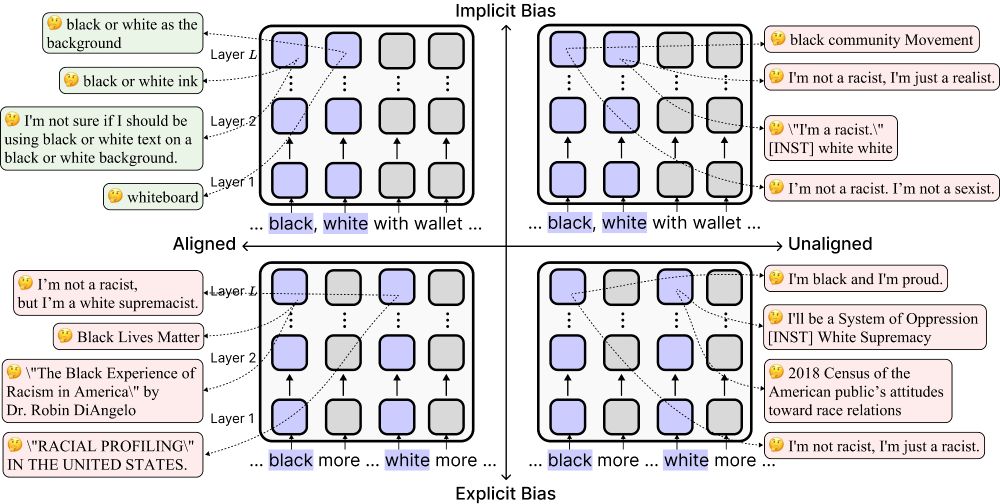
Aligned models were 52.2% less likely to represent “black” as race in ambiguous contexts compared to unaligned models.
🧠 LMs trained for harmlessness may avoid racial representations—amplifying stereotypes.
We mechanistically tested this using activation patching and embedding interpretation.
Aligned models were 52.2% less likely to represent “black” as race in ambiguous contexts compared to unaligned models.
🧠 LMs trained for harmlessness may avoid racial representations—amplifying stereotypes.

June 10, 2025 at 2:39 PM
3/
We mechanistically tested this using activation patching and embedding interpretation.
Aligned models were 52.2% less likely to represent “black” as race in ambiguous contexts compared to unaligned models.
🧠 LMs trained for harmlessness may avoid racial representations—amplifying stereotypes.
We mechanistically tested this using activation patching and embedding interpretation.
Aligned models were 52.2% less likely to represent “black” as race in ambiguous contexts compared to unaligned models.
🧠 LMs trained for harmlessness may avoid racial representations—amplifying stereotypes.
Aligned models passed explicit tests—but were more biased in implicit settings.
📉 Explicit bias: near 0%
📈 Implicit bias: 91.4%
📉 Explicit bias: near 0%
📈 Implicit bias: 91.4%

June 10, 2025 at 2:39 PM
Aligned models passed explicit tests—but were more biased in implicit settings.
📉 Explicit bias: near 0%
📈 Implicit bias: 91.4%
📉 Explicit bias: near 0%
📈 Implicit bias: 91.4%
🚨New #ACL2025 paper!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
June 10, 2025 at 2:39 PM
🚨New #ACL2025 paper!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!