




Shayne Longpre
@shaynelongpre.bsky.social
PhD @ MIT. Prev: Google Deepmind, Apple, Stanford. 🇨🇦 Interests: AI/ML/NLP, Data-centric AI, transparency & societal impact
Reposted by Shayne Longpre

This is some legit really impressive work!!
📢Thrilled to introduce ATLAS 🗺️: the largest multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer:
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵


October 30, 2025 at 12:24 PM
This is some legit really impressive work!!
📢Thrilled to introduce ATLAS 🗺️: the largest multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer:
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵
October 28, 2025 at 2:03 PM
📢Thrilled to introduce ATLAS 🗺️: the largest multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer:
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵
Reposted by Shayne Longpre

Which, whose, and how much knowledge do LLMs represent?
I'm excited to share our preprint answering these questions:
"Epistemic Diversity and Knowledge Collapse in Large Language Models"
📄Paper: arxiv.org/pdf/2510.04226
💻Code: github.com/dwright37/ll...
1/10
I'm excited to share our preprint answering these questions:
"Epistemic Diversity and Knowledge Collapse in Large Language Models"
📄Paper: arxiv.org/pdf/2510.04226
💻Code: github.com/dwright37/ll...
1/10

October 13, 2025 at 11:25 AM
Which, whose, and how much knowledge do LLMs represent?
I'm excited to share our preprint answering these questions:
"Epistemic Diversity and Knowledge Collapse in Large Language Models"
📄Paper: arxiv.org/pdf/2510.04226
💻Code: github.com/dwright37/ll...
1/10
I'm excited to share our preprint answering these questions:
"Epistemic Diversity and Knowledge Collapse in Large Language Models"
📄Paper: arxiv.org/pdf/2510.04226
💻Code: github.com/dwright37/ll...
1/10
Delighted to see BigGen Bench paper receive the 🏆best paper award 🏆at NAACL 2025!
BigGen Bench introduces fine-grained, scalable, & human-aligned evaluations:
📈 77 hard, diverse tasks
🛠️ 765 exs w/ ex-specific rubrics
📋 More human-aligned than previous rubrics
🌍 10 languages, by native speakers
1/
BigGen Bench introduces fine-grained, scalable, & human-aligned evaluations:
📈 77 hard, diverse tasks
🛠️ 765 exs w/ ex-specific rubrics
📋 More human-aligned than previous rubrics
🌍 10 languages, by native speakers
1/

May 6, 2025 at 1:50 PM
Delighted to see BigGen Bench paper receive the 🏆best paper award 🏆at NAACL 2025!
BigGen Bench introduces fine-grained, scalable, & human-aligned evaluations:
📈 77 hard, diverse tasks
🛠️ 765 exs w/ ex-specific rubrics
📋 More human-aligned than previous rubrics
🌍 10 languages, by native speakers
1/
BigGen Bench introduces fine-grained, scalable, & human-aligned evaluations:
📈 77 hard, diverse tasks
🛠️ 765 exs w/ ex-specific rubrics
📋 More human-aligned than previous rubrics
🌍 10 languages, by native speakers
1/
Reposted by Shayne Longpre

It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.

April 30, 2025 at 2:55 PM
It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
Reposted by Shayne Longpre

How should regulatory proposals adapt to the prevalence of general-purpose AI when the global geopolitical order is being reconfigured? @atoosakz.bsky.social, Deirdre K. Mulligan, @randomwalker.bsky.social, @alondra.bsky.social, & @shaynelongpre.bsky.social weigh in:
youtu.be/cRsbjGFPJaM?...
youtu.be/cRsbjGFPJaM?...

Day 1 Opening Remarks and Panel 1: Regulating AI in Democratic Upheaval (AI & Democratic Freedoms)
YouTube video by Knight First Amendment Institute
youtu.be
April 30, 2025 at 2:05 PM
How should regulatory proposals adapt to the prevalence of general-purpose AI when the global geopolitical order is being reconfigured? @atoosakz.bsky.social, Deirdre K. Mulligan, @randomwalker.bsky.social, @alondra.bsky.social, & @shaynelongpre.bsky.social weigh in:
youtu.be/cRsbjGFPJaM?...
youtu.be/cRsbjGFPJaM?...
April 22, 2025 at 8:44 PM
Thrilled our global data ecosystem audit was accepted to #ICLR2025!
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
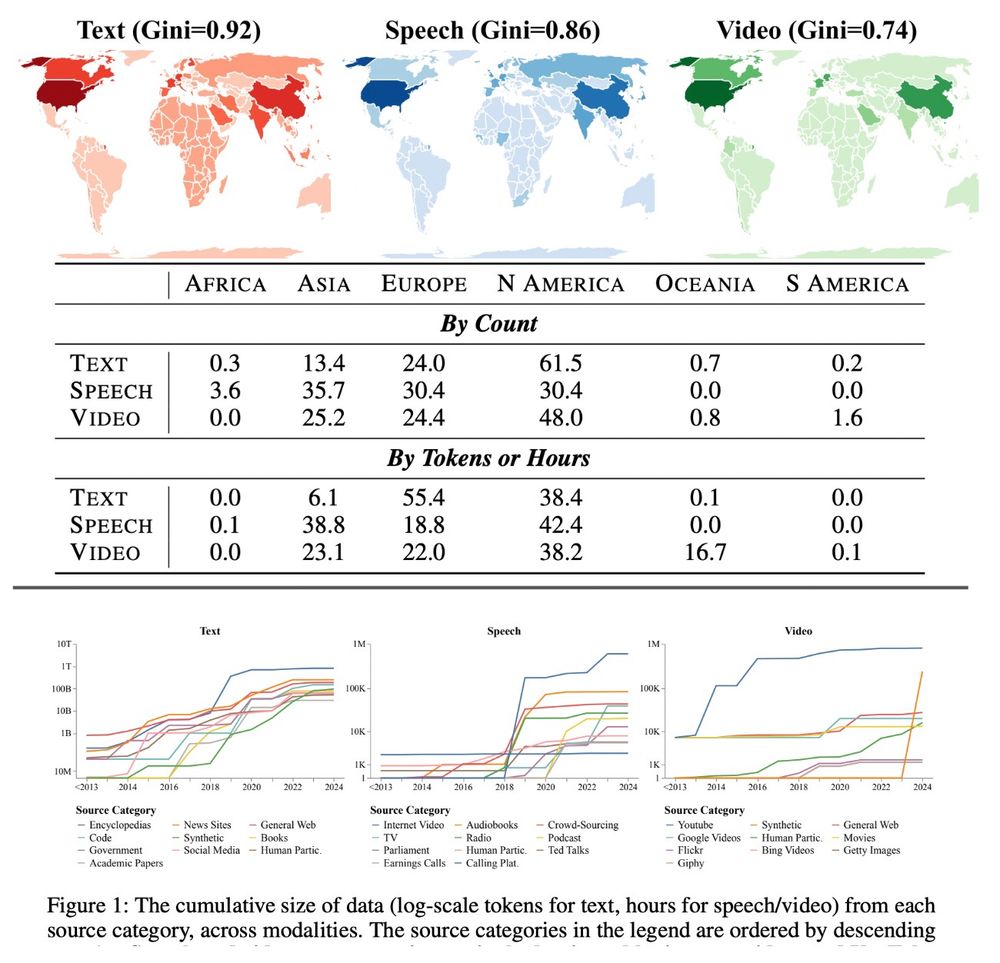
April 14, 2025 at 3:28 PM
Thrilled our global data ecosystem audit was accepted to #ICLR2025!
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
Reposted by Shayne Longpre
📍EVENT: Day 2 of our “AI and Democracy” symposium will be kicking off shortly. Programming will begin with welcome remarks from George Deodatis @columbiaseas.bsky.social at 9:30am ET. #AIDemocraticFreedoms
Watch the full event on our livestream here:
www.youtube.com/watch?v=X1gj...
Watch the full event on our livestream here:
www.youtube.com/watch?v=X1gj...

Artificial Intelligence and Democratic Freedoms (Day 2)
YouTube video by Knight First Amendment Institute
www.youtube.com
April 11, 2025 at 12:57 PM
📍EVENT: Day 2 of our “AI and Democracy” symposium will be kicking off shortly. Programming will begin with welcome remarks from George Deodatis @columbiaseas.bsky.social at 9:30am ET. #AIDemocraticFreedoms
Watch the full event on our livestream here:
www.youtube.com/watch?v=X1gj...
Watch the full event on our livestream here:
www.youtube.com/watch?v=X1gj...
Reposted by Shayne Longpre

Very excited to release Kaleidoscope—a multilingual, multimodal evaluation set for VLMs, built as part of our open-science initiative!
🌍 18 languages (high-, mid-, low-)
📚 21k questions (55% require image understanding)
🧪 STEM, social science, reasoning, and practical skills
🌍 18 languages (high-, mid-, low-)
📚 21k questions (55% require image understanding)
🧪 STEM, social science, reasoning, and practical skills

April 10, 2025 at 7:52 PM
Very excited to release Kaleidoscope—a multilingual, multimodal evaluation set for VLMs, built as part of our open-science initiative!
🌍 18 languages (high-, mid-, low-)
📚 21k questions (55% require image understanding)
🧪 STEM, social science, reasoning, and practical skills
🌍 18 languages (high-, mid-, low-)
📚 21k questions (55% require image understanding)
🧪 STEM, social science, reasoning, and practical skills
Reposted by Shayne Longpre
Panel 1: Regulating AI in a Time of Democratic Upheaval starts in approximately 5 minutes.
Panelists: @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, and Deirdre K. Mulligan.
Moderator: @shaynelongpre.bsky.social.
#AIDemocraticFreedoms
Panelists: @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, and Deirdre K. Mulligan.
Moderator: @shaynelongpre.bsky.social.
#AIDemocraticFreedoms

April 10, 2025 at 1:44 PM
Panel 1: Regulating AI in a Time of Democratic Upheaval starts in approximately 5 minutes.
Panelists: @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, and Deirdre K. Mulligan.
Moderator: @shaynelongpre.bsky.social.
#AIDemocraticFreedoms
Panelists: @atoosakz.bsky.social, @randomwalker.bsky.social, @alondra.bsky.social, and Deirdre K. Mulligan.
Moderator: @shaynelongpre.bsky.social.
#AIDemocraticFreedoms
This week, @stanfordhai.bsky.social released the 2025 AI Index. It’s well worth reading to understand the evolving ecosystem of AI. Some highlights that stood out to me:
1/
1/


April 9, 2025 at 3:25 PM
This week, @stanfordhai.bsky.social released the 2025 AI Index. It’s well worth reading to understand the evolving ecosystem of AI. Some highlights that stood out to me:
1/
1/

📣We’re thrilled to announce the first workshop on Technical AI Governance (TAIG) at #ICML2025 this July in Vancouver! Join us (& this stellar list of speakers) in bringing together technical & policy experts to shape the future of AI governance! www.taig-icml.com

April 1, 2025 at 4:52 PM
Reposted by Shayne Longpre

#AI is evolving fast, and so are its flaws. A fresh approach to finding and reporting AI bugs is long overdue. Great initiative by @shaynelongpre.bsky.social and team, transparency and accountability in AI development are essential! #AISafety #ResponsibleAI #AIEthics #MIT

Researchers Propose a Better Way to Report Dangerous AI Flaws
After identifying major flaws in popular AI models, researchers are pushing for a new system to identify and report bugs.
www.wired.com
March 17, 2025 at 3:41 AM
#AI is evolving fast, and so are its flaws. A fresh approach to finding and reporting AI bugs is long overdue. Great initiative by @shaynelongpre.bsky.social and team, transparency and accountability in AI development are essential! #AISafety #ResponsibleAI #AIEthics #MIT
Reposted by Shayne Longpre

After identifying major flaws in popular AI models, researchers are pushing for a new system to identify and report bugs.

Researchers Propose a Better Way to Report Dangerous AI Flaws
After identifying major flaws in popular AI models, researchers are pushing for a new system to identify and report bugs.
wrd.cm
March 13, 2025 at 3:03 PM
After identifying major flaws in popular AI models, researchers are pushing for a new system to identify and report bugs.
Thank you @willknight.bsky.social for excellent coverage of our new proposal!
www.wired.com/story/ai-res...
www.wired.com/story/ai-res...
March 13, 2025 at 3:59 PM
Thank you @willknight.bsky.social for excellent coverage of our new proposal!
www.wired.com/story/ai-res...
www.wired.com/story/ai-res...
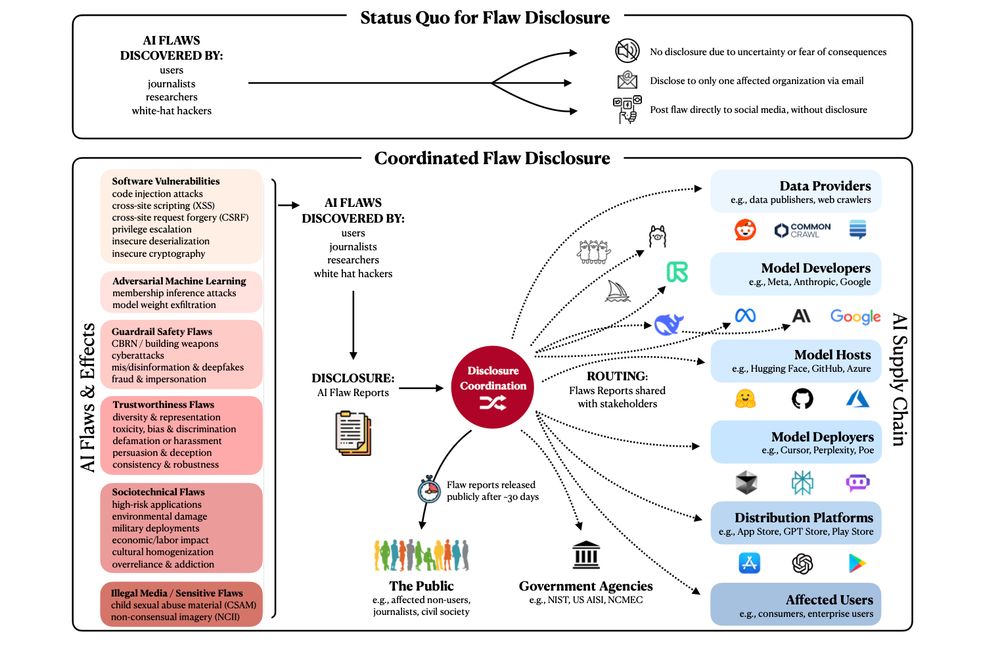
What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
March 13, 2025 at 3:59 PM
What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
Reposted by Shayne Longpre

Very glad to join this paper organized by @shaynelongpre.bsky.social. Here's the paper itself: crfm.stanford.edu/2025/03/13/t...

Researchers Propose a Better Way to Report Dangerous AI Flaws
After identifying major flaws in popular AI models, researchers are pushing for a new system to identify and report bugs.
www.wired.com
March 13, 2025 at 3:25 PM
Very glad to join this paper organized by @shaynelongpre.bsky.social. Here's the paper itself: crfm.stanford.edu/2025/03/13/t...
Reposted by Shayne Longpre

Bringing transparency to the data used to train artificial intelligence
mitsloan.mit.edu/ideas-made-t...
mitsloan.mit.edu/ideas-made-t...

Bringing transparency to the data used to train artificial intelligence | MIT Sloan
Using the wrong datasets to train AI models can result in legal risks, bias, or lower-quality models. The Data Provenance Initiative’s tool can help.
mitsloan.mit.edu
March 4, 2025 at 2:16 AM
Bringing transparency to the data used to train artificial intelligence
mitsloan.mit.edu/ideas-made-t...
mitsloan.mit.edu/ideas-made-t...
Thrilled to be at #AAAI2025 for our tutorial, “AI Data Transparency: The Past, Present, and Beyond.”
We’re presenting the state of transparency, tooling, and policy, from the Foundation Model Transparency Index, Factsheets, the the EU AI Act to new frameworks like @MLCommons’ Croissant.
1/
We’re presenting the state of transparency, tooling, and policy, from the Foundation Model Transparency Index, Factsheets, the the EU AI Act to new frameworks like @MLCommons’ Croissant.
1/

February 26, 2025 at 6:15 PM
Thrilled to be at #AAAI2025 for our tutorial, “AI Data Transparency: The Past, Present, and Beyond.”
We’re presenting the state of transparency, tooling, and policy, from the Foundation Model Transparency Index, Factsheets, the the EU AI Act to new frameworks like @MLCommons’ Croissant.
1/
We’re presenting the state of transparency, tooling, and policy, from the Foundation Model Transparency Index, Factsheets, the the EU AI Act to new frameworks like @MLCommons’ Croissant.
1/
Reposted by Shayne Longpre

Really excellent explainer by @shaynelongpre.bsky.social that clearly lays out what's at stake in the "AI crawler wars"

February 21, 2025 at 4:56 PM
Really excellent explainer by @shaynelongpre.bsky.social that clearly lays out what's at stake in the "AI crawler wars"
Reposted by Shayne Longpre

Re: the FTC and the platforms
We *should* be concerned about platform power over speech, but it isn’t censorship.
As the Supreme Court said last year, the companies’ editorial decisions to moderate content are protected by the First Amendment.
1/
We *should* be concerned about platform power over speech, but it isn’t censorship.
As the Supreme Court said last year, the companies’ editorial decisions to moderate content are protected by the First Amendment.
1/
February 20, 2025 at 10:50 PM
Re: the FTC and the platforms
We *should* be concerned about platform power over speech, but it isn’t censorship.
As the Supreme Court said last year, the companies’ editorial decisions to moderate content are protected by the First Amendment.
1/
We *should* be concerned about platform power over speech, but it isn’t censorship.
As the Supreme Court said last year, the companies’ editorial decisions to moderate content are protected by the First Amendment.
1/
Reposted by Shayne Longpre

Let’s see if the algorithm and data remains transparent.

February 20, 2025 at 9:10 PM
Let’s see if the algorithm and data remains transparent.
I compiled a list of resources for understanding AI copyright challenges (US-centric). 📚
➡️ why is copyright an issue for AI?
➡️ what is fair use?
➡️ why are memorization and generation important?
➡️ how does it impact the AI data supply / web crawling?
🧵
➡️ why is copyright an issue for AI?
➡️ what is fair use?
➡️ why are memorization and generation important?
➡️ how does it impact the AI data supply / web crawling?
🧵

February 19, 2025 at 4:32 PM
I compiled a list of resources for understanding AI copyright challenges (US-centric). 📚
➡️ why is copyright an issue for AI?
➡️ what is fair use?
➡️ why are memorization and generation important?
➡️ how does it impact the AI data supply / web crawling?
🧵
➡️ why is copyright an issue for AI?
➡️ what is fair use?
➡️ why are memorization and generation important?
➡️ how does it impact the AI data supply / web crawling?
🧵
Reposted by Shayne Longpre

Great point by @shaynelongpre.bsky.social on the AI crawler wars: "Unless we can nurture an ecosystem with different rules for different data uses, we may end up with strict borders across the web, exacting a price on openness and transparency." www.technologyreview.com/2025/02/11/1...

AI crawler wars threaten to make the web more closed for everyone
There’s an accelerating cat-and-mouse game between web publishers and AI crawlers, and we all stand to lose.
www.technologyreview.com
February 13, 2025 at 7:44 PM
Great point by @shaynelongpre.bsky.social on the AI crawler wars: "Unless we can nurture an ecosystem with different rules for different data uses, we may end up with strict borders across the web, exacting a price on openness and transparency." www.technologyreview.com/2025/02/11/1...