




Shayne Longpre
@shaynelongpre.bsky.social
PhD @ MIT. Prev: Google Deepmind, Apple, Stanford. 🇨🇦 Interests: AI/ML/NLP, Data-centric AI, transparency & societal impact
Q4: When should you pretrain from scratch vs finetune a multilingual checkpoint?
🌟Answer: We found compute-optimal crossover points for every model size.
Rough rule of thumb: finetune if your compute budget C is < 10^10 x N ^1.54, otherwise pretrain.
8/
🌟Answer: We found compute-optimal crossover points for every model size.
Rough rule of thumb: finetune if your compute budget C is < 10^10 x N ^1.54, otherwise pretrain.
8/


October 28, 2025 at 2:03 PM
Q4: When should you pretrain from scratch vs finetune a multilingual checkpoint?
🌟Answer: We found compute-optimal crossover points for every model size.
Rough rule of thumb: finetune if your compute budget C is < 10^10 x N ^1.54, otherwise pretrain.
8/
🌟Answer: We found compute-optimal crossover points for every model size.
Rough rule of thumb: finetune if your compute budget C is < 10^10 x N ^1.54, otherwise pretrain.
8/
Q3: How much do you need to scale when adding languages? (The "curse of multilinguality")
🌟Answer: We derived closed-form equations! To go from K to 4K languages while maintaining performance: scale data by 2.74×, model size by 1.4×.
6/
🌟Answer: We derived closed-form equations! To go from K to 4K languages while maintaining performance: scale data by 2.74×, model size by 1.4×.
6/

October 28, 2025 at 2:03 PM
Q3: How much do you need to scale when adding languages? (The "curse of multilinguality")
🌟Answer: We derived closed-form equations! To go from K to 4K languages while maintaining performance: scale data by 2.74×, model size by 1.4×.
6/
🌟Answer: We derived closed-form equations! To go from K to 4K languages while maintaining performance: scale data by 2.74×, model size by 1.4×.
6/
🌟Key insight:🌟 shared script beats shared language family for positive transfer!
Languages sharing writing systems (e.g., Latin) show dramatically better transfer (mean: -0.23) vs different scripts (mean: -0.39).
Also important: transfer is often asymmetric—A helping B ≠ B helping A.
5/
Languages sharing writing systems (e.g., Latin) show dramatically better transfer (mean: -0.23) vs different scripts (mean: -0.39).
Also important: transfer is often asymmetric—A helping B ≠ B helping A.
5/

October 28, 2025 at 2:03 PM
🌟Key insight:🌟 shared script beats shared language family for positive transfer!
Languages sharing writing systems (e.g., Latin) show dramatically better transfer (mean: -0.23) vs different scripts (mean: -0.39).
Also important: transfer is often asymmetric—A helping B ≠ B helping A.
5/
Languages sharing writing systems (e.g., Latin) show dramatically better transfer (mean: -0.23) vs different scripts (mean: -0.39).
Also important: transfer is often asymmetric—A helping B ≠ B helping A.
5/
Q2: Which languages actually help each other during training? And how much?
🌟Answer: We measure this empirically. We built a 38×38 transfer matrix, or 1,444 language pairs—the largest such resource to date.
We highlight the top 5 most beneficial source languages for each target language.
4/
🌟Answer: We measure this empirically. We built a 38×38 transfer matrix, or 1,444 language pairs—the largest such resource to date.
We highlight the top 5 most beneficial source languages for each target language.
4/

October 28, 2025 at 2:03 PM
Q2: Which languages actually help each other during training? And how much?
🌟Answer: We measure this empirically. We built a 38×38 transfer matrix, or 1,444 language pairs—the largest such resource to date.
We highlight the top 5 most beneficial source languages for each target language.
4/
🌟Answer: We measure this empirically. We built a 38×38 transfer matrix, or 1,444 language pairs—the largest such resource to date.
We highlight the top 5 most beneficial source languages for each target language.
4/
ATLAS models cross-lingual transfer explicitly: separating (1) target language data, (2) beneficial transfer languages, and (3) other languages.
Without modeling transfer, existing laws fail on multilingual settings.
3/
Without modeling transfer, existing laws fail on multilingual settings.
3/

October 28, 2025 at 2:03 PM
ATLAS models cross-lingual transfer explicitly: separating (1) target language data, (2) beneficial transfer languages, and (3) other languages.
Without modeling transfer, existing laws fail on multilingual settings.
3/
Without modeling transfer, existing laws fail on multilingual settings.
3/
Q1: Can we build a scaling law that generalizes to unseen model sizes (N), data amounts (D), AND language mixtures (M)?
🌟Answer: Yes! ATLAS outperforms prior work with R²(N)=0.88 vs 0.68, and R²(M)=0.82 vs 0.69 for mixture generalization.
2/
🌟Answer: Yes! ATLAS outperforms prior work with R²(N)=0.88 vs 0.68, and R²(M)=0.82 vs 0.69 for mixture generalization.
2/

October 28, 2025 at 2:03 PM
Q1: Can we build a scaling law that generalizes to unseen model sizes (N), data amounts (D), AND language mixtures (M)?
🌟Answer: Yes! ATLAS outperforms prior work with R²(N)=0.88 vs 0.68, and R²(M)=0.82 vs 0.69 for mixture generalization.
2/
🌟Answer: Yes! ATLAS outperforms prior work with R²(N)=0.88 vs 0.68, and R²(M)=0.82 vs 0.69 for mixture generalization.
2/
📢Thrilled to introduce ATLAS 🗺️: the largest multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer:
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵


October 28, 2025 at 2:03 PM
📢Thrilled to introduce ATLAS 🗺️: the largest multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer:
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵
🌍 Is scaling diff by lang?
🧙♂️ Can we model the curse of multilinguality?
⚖️ Pretrain vs finetune from checkpoint?
🔀 X-lingual transfer scores across langs?
1/🧵
Delighted to see BigGen Bench paper receive the 🏆best paper award 🏆at NAACL 2025!
BigGen Bench introduces fine-grained, scalable, & human-aligned evaluations:
📈 77 hard, diverse tasks
🛠️ 765 exs w/ ex-specific rubrics
📋 More human-aligned than previous rubrics
🌍 10 languages, by native speakers
1/
BigGen Bench introduces fine-grained, scalable, & human-aligned evaluations:
📈 77 hard, diverse tasks
🛠️ 765 exs w/ ex-specific rubrics
📋 More human-aligned than previous rubrics
🌍 10 languages, by native speakers
1/

May 6, 2025 at 1:50 PM
Delighted to see BigGen Bench paper receive the 🏆best paper award 🏆at NAACL 2025!
BigGen Bench introduces fine-grained, scalable, & human-aligned evaluations:
📈 77 hard, diverse tasks
🛠️ 765 exs w/ ex-specific rubrics
📋 More human-aligned than previous rubrics
🌍 10 languages, by native speakers
1/
BigGen Bench introduces fine-grained, scalable, & human-aligned evaluations:
📈 77 hard, diverse tasks
🛠️ 765 exs w/ ex-specific rubrics
📋 More human-aligned than previous rubrics
🌍 10 languages, by native speakers
1/
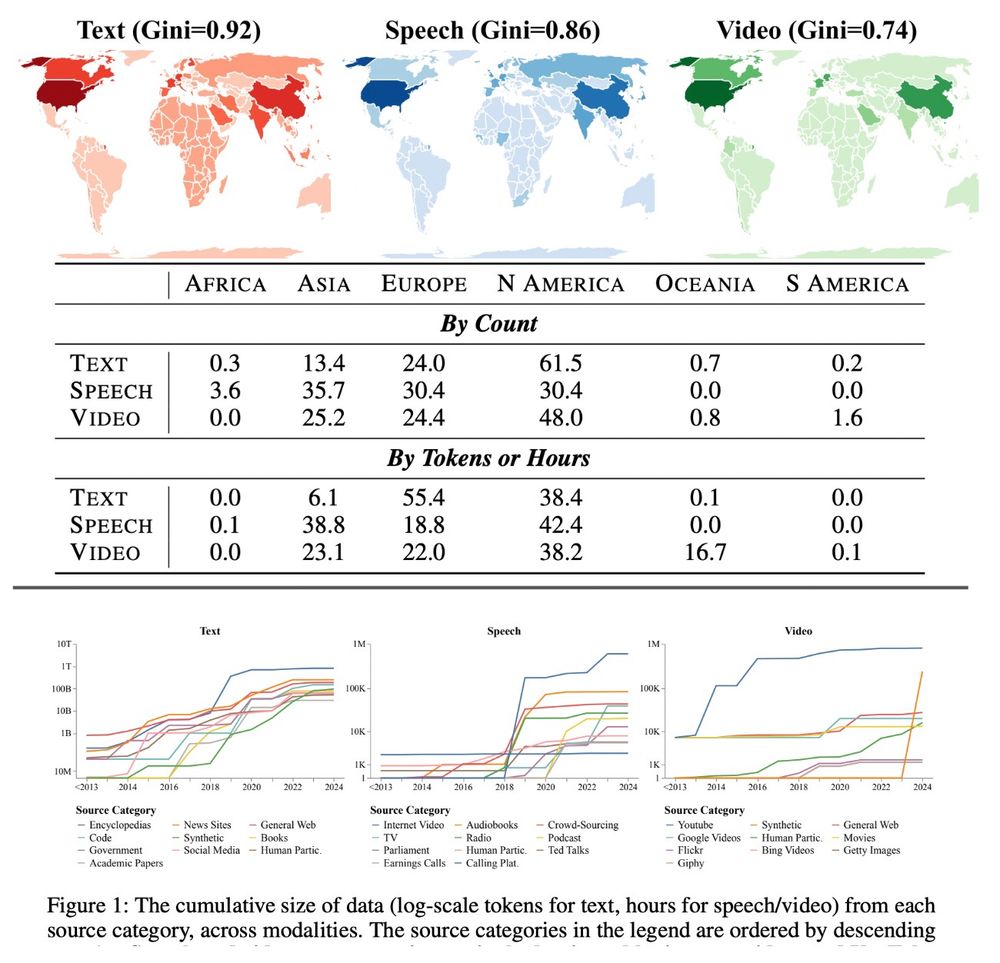
Thrilled our global data ecosystem audit was accepted to #ICLR2025!
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
April 14, 2025 at 3:28 PM
Thrilled our global data ecosystem audit was accepted to #ICLR2025!
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
This week, @stanfordhai.bsky.social released the 2025 AI Index. It’s well worth reading to understand the evolving ecosystem of AI. Some highlights that stood out to me:
1/
1/


April 9, 2025 at 3:25 PM
This week, @stanfordhai.bsky.social released the 2025 AI Index. It’s well worth reading to understand the evolving ecosystem of AI. Some highlights that stood out to me:
1/
1/
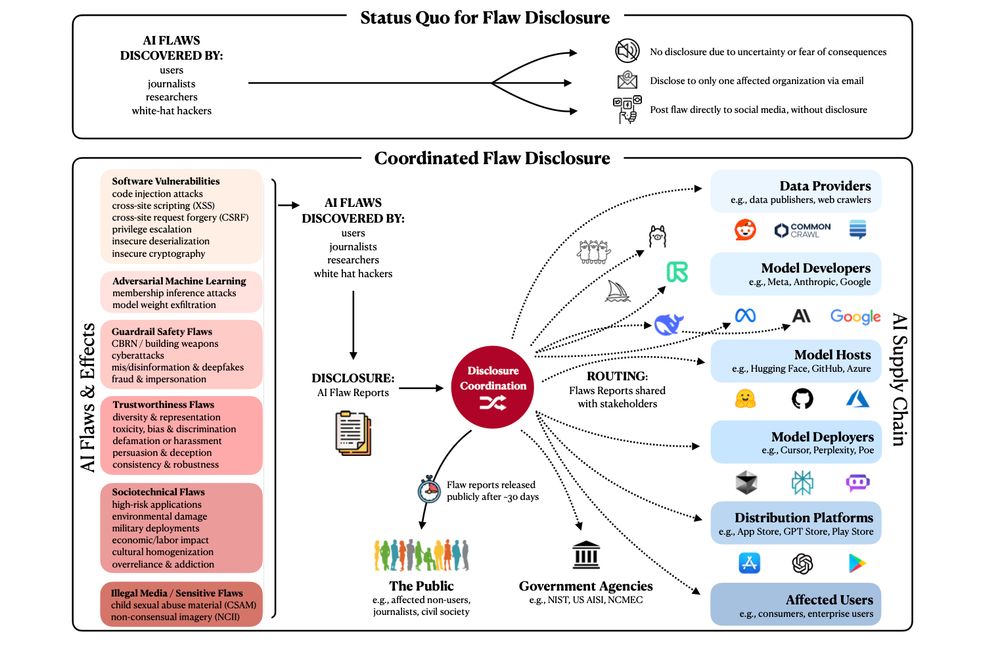
3️⃣ A centralized disclosure coordination center.
For transferable AI flaws (e.g., jailbreaks affecting multiple systems), we need to inform all relevant developers and stakeholders who must act to mitigate these issues.
See the Figure to understand the before and after of flaw disclosure.
6/
For transferable AI flaws (e.g., jailbreaks affecting multiple systems), we need to inform all relevant developers and stakeholders who must act to mitigate these issues.
See the Figure to understand the before and after of flaw disclosure.
6/

March 13, 2025 at 3:59 PM
3️⃣ A centralized disclosure coordination center.
For transferable AI flaws (e.g., jailbreaks affecting multiple systems), we need to inform all relevant developers and stakeholders who must act to mitigate these issues.
See the Figure to understand the before and after of flaw disclosure.
6/
For transferable AI flaws (e.g., jailbreaks affecting multiple systems), we need to inform all relevant developers and stakeholders who must act to mitigate these issues.
See the Figure to understand the before and after of flaw disclosure.
6/
2️⃣ AI developers institute broadly-scoped AI flaw disclosure programs + safe harbors.
Security-only or invite-only bug bounties from OpenAI and Anthropic are a great start.
But eventually we need disclosure programs to cover the full range of AI issues, and protect independent researchers.
5/
Security-only or invite-only bug bounties from OpenAI and Anthropic are a great start.
But eventually we need disclosure programs to cover the full range of AI issues, and protect independent researchers.
5/

March 13, 2025 at 3:59 PM
2️⃣ AI developers institute broadly-scoped AI flaw disclosure programs + safe harbors.
Security-only or invite-only bug bounties from OpenAI and Anthropic are a great start.
But eventually we need disclosure programs to cover the full range of AI issues, and protect independent researchers.
5/
Security-only or invite-only bug bounties from OpenAI and Anthropic are a great start.
But eventually we need disclosure programs to cover the full range of AI issues, and protect independent researchers.
5/
To empower universal AI safety and security, we propose:
1️⃣ adoption of standardized AI flaw reports, to improve flaw reproducibility, triaging, coordination across stakeholders, and ultimately AI safety.
4/
1️⃣ adoption of standardized AI flaw reports, to improve flaw reproducibility, triaging, coordination across stakeholders, and ultimately AI safety.
4/


March 13, 2025 at 3:59 PM
To empower universal AI safety and security, we propose:
1️⃣ adoption of standardized AI flaw reports, to improve flaw reproducibility, triaging, coordination across stakeholders, and ultimately AI safety.
4/
1️⃣ adoption of standardized AI flaw reports, to improve flaw reproducibility, triaging, coordination across stakeholders, and ultimately AI safety.
4/
Motivation
Today, GPAI serves 300M+ users globally, w/ diverse & unforeseen uses across modalities and languages.
➡️ We need third-party evaluation for its broad expertise, participation and independence, including from real users, academic researchers, white-hat hackers, and journalists
2/
Today, GPAI serves 300M+ users globally, w/ diverse & unforeseen uses across modalities and languages.
➡️ We need third-party evaluation for its broad expertise, participation and independence, including from real users, academic researchers, white-hat hackers, and journalists
2/

March 13, 2025 at 3:59 PM
Motivation
Today, GPAI serves 300M+ users globally, w/ diverse & unforeseen uses across modalities and languages.
➡️ We need third-party evaluation for its broad expertise, participation and independence, including from real users, academic researchers, white-hat hackers, and journalists
2/
Today, GPAI serves 300M+ users globally, w/ diverse & unforeseen uses across modalities and languages.
➡️ We need third-party evaluation for its broad expertise, participation and independence, including from real users, academic researchers, white-hat hackers, and journalists
2/
What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
March 13, 2025 at 3:59 PM
What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-actions to empower evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws.
1/🧵
Thrilled to be at #AAAI2025 for our tutorial, “AI Data Transparency: The Past, Present, and Beyond.”
We’re presenting the state of transparency, tooling, and policy, from the Foundation Model Transparency Index, Factsheets, the the EU AI Act to new frameworks like @MLCommons’ Croissant.
1/
We’re presenting the state of transparency, tooling, and policy, from the Foundation Model Transparency Index, Factsheets, the the EU AI Act to new frameworks like @MLCommons’ Croissant.
1/

February 26, 2025 at 6:15 PM
Thrilled to be at #AAAI2025 for our tutorial, “AI Data Transparency: The Past, Present, and Beyond.”
We’re presenting the state of transparency, tooling, and policy, from the Foundation Model Transparency Index, Factsheets, the the EU AI Act to new frameworks like @MLCommons’ Croissant.
1/
We’re presenting the state of transparency, tooling, and policy, from the Foundation Model Transparency Index, Factsheets, the the EU AI Act to new frameworks like @MLCommons’ Croissant.
1/
I compiled a list of resources for understanding AI copyright challenges (US-centric). 📚
➡️ why is copyright an issue for AI?
➡️ what is fair use?
➡️ why are memorization and generation important?
➡️ how does it impact the AI data supply / web crawling?
🧵
➡️ why is copyright an issue for AI?
➡️ what is fair use?
➡️ why are memorization and generation important?
➡️ how does it impact the AI data supply / web crawling?
🧵

February 19, 2025 at 4:32 PM
I compiled a list of resources for understanding AI copyright challenges (US-centric). 📚
➡️ why is copyright an issue for AI?
➡️ what is fair use?
➡️ why are memorization and generation important?
➡️ how does it impact the AI data supply / web crawling?
🧵
➡️ why is copyright an issue for AI?
➡️ what is fair use?
➡️ why are memorization and generation important?
➡️ how does it impact the AI data supply / web crawling?
🧵
Publishers are understandably worried: news sites fear losing readers to AI chatbots; artists and designers fear AI image generators; coding forums fear AI-driven replacements.
Increasingly, they block or charge all non-human traffic, not just AI crawlers.
3/
Increasingly, they block or charge all non-human traffic, not just AI crawlers.
3/

February 12, 2025 at 4:47 PM
Publishers are understandably worried: news sites fear losing readers to AI chatbots; artists and designers fear AI image generators; coding forums fear AI-driven replacements.
Increasingly, they block or charge all non-human traffic, not just AI crawlers.
3/
Increasingly, they block or charge all non-human traffic, not just AI crawlers.
3/
3/ In the copyright section, this diagram shows how copyright concerns can intertwine consequences for artists, developer transparency, and even the structure of the web.

February 10, 2025 at 3:13 PM
3/ In the copyright section, this diagram shows how copyright concerns can intertwine consequences for artists, developer transparency, and even the structure of the web.
Our updated Responsible Foundation Model Development Cheatsheet (250+ tools & resources) is now officially accepted to @tmlrorg.bsky.social (TMLR) 2025!
It covers:
- data sourcing,
- documentation,
- environmental impact,
- risk eval
- model release & licensing
- ++
It covers:
- data sourcing,
- documentation,
- environmental impact,
- risk eval
- model release & licensing
- ++

February 3, 2025 at 3:59 PM
Our updated Responsible Foundation Model Development Cheatsheet (250+ tools & resources) is now officially accepted to @tmlrorg.bsky.social (TMLR) 2025!
It covers:
- data sourcing,
- documentation,
- environmental impact,
- risk eval
- model release & licensing
- ++
It covers:
- data sourcing,
- documentation,
- environmental impact,
- risk eval
- model release & licensing
- ++
🪶 Some thoughts on DeepSeek, OpenAI, and the copyright battles:
This isn’t the first time OpenAI has accused a Chinese company of breaking its Terms and training on ChatGPT outputs.
Dec 2023: They suspended ByteDance’s accounts.
1/
This isn’t the first time OpenAI has accused a Chinese company of breaking its Terms and training on ChatGPT outputs.
Dec 2023: They suspended ByteDance’s accounts.
1/


February 1, 2025 at 5:27 PM
🪶 Some thoughts on DeepSeek, OpenAI, and the copyright battles:
This isn’t the first time OpenAI has accused a Chinese company of breaking its Terms and training on ChatGPT outputs.
Dec 2023: They suspended ByteDance’s accounts.
1/
This isn’t the first time OpenAI has accused a Chinese company of breaking its Terms and training on ChatGPT outputs.
Dec 2023: They suspended ByteDance’s accounts.
1/
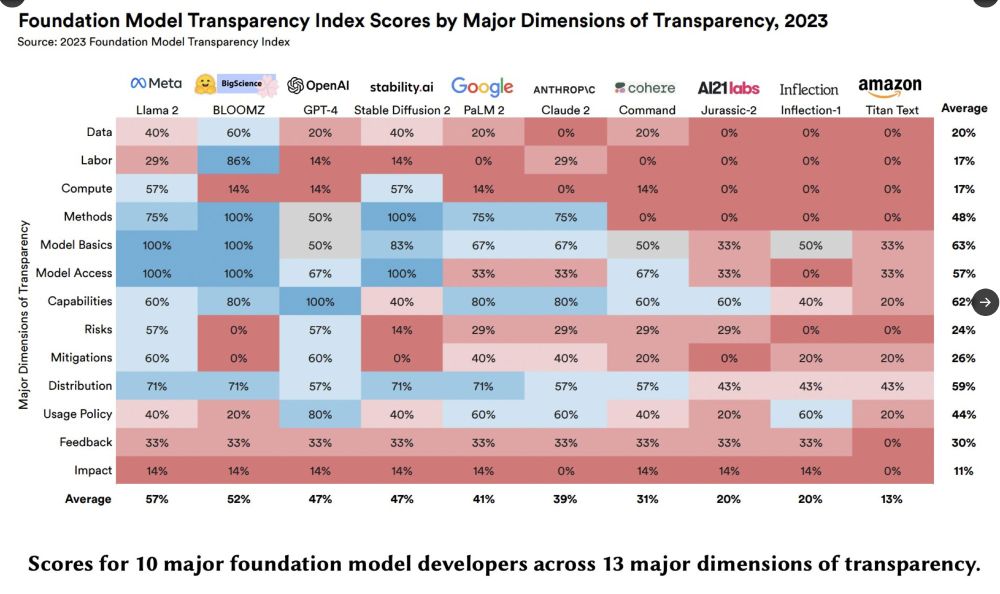
We also find:
➡️ Open releases (BLOOMZ, Llama 2, SD2) are more transparent than closed releases
➡️ Significant room for improvement in Downstream Usage Policy, Feedback, and Impact
2/
➡️ Open releases (BLOOMZ, Llama 2, SD2) are more transparent than closed releases
➡️ Significant room for improvement in Downstream Usage Policy, Feedback, and Impact
2/
October 18, 2023 at 5:37 PM
We also find:
➡️ Open releases (BLOOMZ, Llama 2, SD2) are more transparent than closed releases
➡️ Significant room for improvement in Downstream Usage Policy, Feedback, and Impact
2/
➡️ Open releases (BLOOMZ, Llama 2, SD2) are more transparent than closed releases
➡️ Significant room for improvement in Downstream Usage Policy, Feedback, and Impact
2/
📣The 🌟Foundation Model Transparency Index🌟 scores 10 developers on 💯 indicators.
1️⃣ All 10 score poorly, particularly Data, Labor, Compute
2️⃣ Transparency is possible! 82/100 are scored by >1
3️⃣ Transparency is a precondition for informed & responsible AI policy.
1/
1️⃣ All 10 score poorly, particularly Data, Labor, Compute
2️⃣ Transparency is possible! 82/100 are scored by >1
3️⃣ Transparency is a precondition for informed & responsible AI policy.
1/

October 18, 2023 at 5:36 PM
📣The 🌟Foundation Model Transparency Index🌟 scores 10 developers on 💯 indicators.
1️⃣ All 10 score poorly, particularly Data, Labor, Compute
2️⃣ Transparency is possible! 82/100 are scored by >1
3️⃣ Transparency is a precondition for informed & responsible AI policy.
1/
1️⃣ All 10 score poorly, particularly Data, Labor, Compute
2️⃣ Transparency is possible! 82/100 are scored by >1
3️⃣ Transparency is a precondition for informed & responsible AI policy.
1/
Excited to announce the **Workshop on Instruction Tuning & Instruction Following** (ITIF) at NeurIPS 2023!
-> Join us on Dec 15 in New Orleans
-> Submit by Oct 1
-> See speaker lineup https://an-instructive-workshop.github.io
Stay tuned for updates!
-> Join us on Dec 15 in New Orleans
-> Submit by Oct 1
-> See speaker lineup https://an-instructive-workshop.github.io
Stay tuned for updates!


August 14, 2023 at 4:46 PM
Excited to announce the **Workshop on Instruction Tuning & Instruction Following** (ITIF) at NeurIPS 2023!
-> Join us on Dec 15 in New Orleans
-> Submit by Oct 1
-> See speaker lineup https://an-instructive-workshop.github.io
Stay tuned for updates!
-> Join us on Dec 15 in New Orleans
-> Submit by Oct 1
-> See speaker lineup https://an-instructive-workshop.github.io
Stay tuned for updates!