




Marzieh Fadaee
@mziizm.bsky.social
seeks to understand language.
Head of Cohere Labs
@Cohere_Labs @Cohere
PhD from @UvA_Amsterdam
https://marziehf.github.io/
Head of Cohere Labs
@Cohere_Labs @Cohere
PhD from @UvA_Amsterdam
https://marziehf.github.io/
Pinned
Marzieh Fadaee
@mziizm.bsky.social
· Apr 30

1/ Science is only as strong as the benchmarks it relies on.
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
Reposted by Marzieh Fadaee

What if the way we verify synthetic code is limiting model performance?
In our latest work we uncover the Verification Ceiling Problem: strict “all tests must pass” rules throw away useful data, while weak tests let errors through.
In our latest work we uncover the Verification Ceiling Problem: strict “all tests must pass” rules throw away useful data, while weak tests let errors through.

September 29, 2025 at 10:00 AM
What if the way we verify synthetic code is limiting model performance?
In our latest work we uncover the Verification Ceiling Problem: strict “all tests must pass” rules throw away useful data, while weak tests let errors through.
In our latest work we uncover the Verification Ceiling Problem: strict “all tests must pass” rules throw away useful data, while weak tests let errors through.
Reposted by Marzieh Fadaee
We’re not your average lab. We’re a hybrid research environment dedicated to revolutionizing the ML space.
And we’re hiring a Senior Research Scientist to co-create with us.
If you believe in research as a shared, global effort — this is your chance.
And we’re hiring a Senior Research Scientist to co-create with us.
If you believe in research as a shared, global effort — this is your chance.

September 30, 2025 at 10:00 AM
We’re not your average lab. We’re a hybrid research environment dedicated to revolutionizing the ML space.
And we’re hiring a Senior Research Scientist to co-create with us.
If you believe in research as a shared, global effort — this is your chance.
And we’re hiring a Senior Research Scientist to co-create with us.
If you believe in research as a shared, global effort — this is your chance.
I'm excited to share that I'll be stepping into the role of Head of @cohereforai.bsky.social. It's an honor and a responsibility to lead such an extraordinary group of researchers pushing the boundaries of AI research.

September 5, 2025 at 5:26 PM
I'm excited to share that I'll be stepping into the role of Head of @cohereforai.bsky.social. It's an honor and a responsibility to lead such an extraordinary group of researchers pushing the boundaries of AI research.
Reposted by Marzieh Fadaee
While effective for chess♟️, Elo ratings struggle with LLM evaluation due to volatility and transitivity issues.
New post in collaboration with AI Singapore explores why Elo falls short for AI leaderboards and how we can do better.
New post in collaboration with AI Singapore explores why Elo falls short for AI leaderboards and how we can do better.

August 15, 2025 at 5:04 AM
While effective for chess♟️, Elo ratings struggle with LLM evaluation due to volatility and transitivity issues.
New post in collaboration with AI Singapore explores why Elo falls short for AI leaderboards and how we can do better.
New post in collaboration with AI Singapore explores why Elo falls short for AI leaderboards and how we can do better.
Breaking into AI research is harder than ever, and early-career researchers face fewer chances to get started.
Entry points matter.
We started the Scholars Program 3 years ago to give new researchers a real shot — excited to open applications for year 4✨
Entry points matter.
We started the Scholars Program 3 years ago to give new researchers a real shot — excited to open applications for year 4✨
Applications are now open for the next cohort of the Cohere Labs Scholars Program! 🌟
This is your chance to collaborate with some of the brightest minds in AI & chart new courses in ML research. Let's change the spaces breakthroughs happen.
Apply by Aug 29.
This is your chance to collaborate with some of the brightest minds in AI & chart new courses in ML research. Let's change the spaces breakthroughs happen.
Apply by Aug 29.

August 13, 2025 at 2:42 PM
Breaking into AI research is harder than ever, and early-career researchers face fewer chances to get started.
Entry points matter.
We started the Scholars Program 3 years ago to give new researchers a real shot — excited to open applications for year 4✨
Entry points matter.
We started the Scholars Program 3 years ago to give new researchers a real shot — excited to open applications for year 4✨
Reposted by Marzieh Fadaee

🌍 Language shapes how we think and connect—but most AI models still struggle beyond English.
@microsoft.com's July seminar discussed how we can bridge the gap and build #AIforEveryone with @mziizm.bsky.social of @cohere.com.
📽️ www.microsoft.com/en-us/resear...
@microsoft.com's July seminar discussed how we can bridge the gap and build #AIforEveryone with @mziizm.bsky.social of @cohere.com.
📽️ www.microsoft.com/en-us/resear...

Building Better Language Models Through Global Understanding - Microsoft Research
Modern language models have achieved remarkable capabilities in English, but human knowledge and experience span thousands of languages, each encoding unique perspectives and problem-solving approache...
www.microsoft.com
August 7, 2025 at 3:56 PM
🌍 Language shapes how we think and connect—but most AI models still struggle beyond English.
@microsoft.com's July seminar discussed how we can bridge the gap and build #AIforEveryone with @mziizm.bsky.social of @cohere.com.
📽️ www.microsoft.com/en-us/resear...
@microsoft.com's July seminar discussed how we can bridge the gap and build #AIforEveryone with @mziizm.bsky.social of @cohere.com.
📽️ www.microsoft.com/en-us/resear...

🖼️ Most text-to-image models only really work in English.
This limits who can use them and whose imagination they reflect.
We asked: can we build a small, efficient model that understands prompts in multiple languages natively?
This limits who can use them and whose imagination they reflect.
We asked: can we build a small, efficient model that understands prompts in multiple languages natively?

July 9, 2025 at 1:27 PM
🖼️ Most text-to-image models only really work in English.
This limits who can use them and whose imagination they reflect.
We asked: can we build a small, efficient model that understands prompts in multiple languages natively?
This limits who can use them and whose imagination they reflect.
We asked: can we build a small, efficient model that understands prompts in multiple languages natively?
Everyone talks about GEB (I agree, it's a gem) but Hofstadter's Analogy book is criminally underrated. If you're working on learning intelligence through language understanding, it’s a must-read.

June 29, 2025 at 10:12 AM
Everyone talks about GEB (I agree, it's a gem) but Hofstadter's Analogy book is criminally underrated. If you're working on learning intelligence through language understanding, it’s a must-read.
Reposted by Marzieh Fadaee

🍋 Squeezing the most of few samples - check out our LLMonade recipe for few-sample test-time scaling in multitask environments.
Turns out that standard methods miss out on gains on non-English languages. We propose more robust alternatives.
Very proud of this work that our scholar Ammar led! 🚀
Turns out that standard methods miss out on gains on non-English languages. We propose more robust alternatives.
Very proud of this work that our scholar Ammar led! 🚀
Can we improve the performance of LLMs during inference without the need for extensive sampling OR special reward models? 🤔
Our latest work introduces a new inference time scaling recipe that is sample-efficient, multilingual, and suitable for multi-task requirements. 🍋
Our latest work introduces a new inference time scaling recipe that is sample-efficient, multilingual, and suitable for multi-task requirements. 🍋

June 26, 2025 at 6:17 PM
🍋 Squeezing the most of few samples - check out our LLMonade recipe for few-sample test-time scaling in multitask environments.
Turns out that standard methods miss out on gains on non-English languages. We propose more robust alternatives.
Very proud of this work that our scholar Ammar led! 🚀
Turns out that standard methods miss out on gains on non-English languages. We propose more robust alternatives.
Very proud of this work that our scholar Ammar led! 🚀
London has me under its spell. every. single. visit.

June 9, 2025 at 5:47 PM
London has me under its spell. every. single. visit.
Reposted by Marzieh Fadaee
🚨LLM safety research needs to be at least as multilingual as our models.
What's the current stage and how to progress from here?
This work led by @yongzx.bsky.social has answers! 👇
What's the current stage and how to progress from here?
This work led by @yongzx.bsky.social has answers! 👇
It’s been two years since cross-lingual jailbreaks were first discovered. How far has the multilingual LLM safety research field advanced? 🤔
📏 Our comprehensive survey reveals that there is still a long way to go.
📏 Our comprehensive survey reveals that there is still a long way to go.

June 4, 2025 at 11:44 AM
🚨LLM safety research needs to be at least as multilingual as our models.
What's the current stage and how to progress from here?
This work led by @yongzx.bsky.social has answers! 👇
What's the current stage and how to progress from here?
This work led by @yongzx.bsky.social has answers! 👇
Reposted by Marzieh Fadaee
Over 7000 languages are spoken worldwide 🌐, but AI safety efforts focus on only a fraction of them.
Our latest paper draws on our multi-year efforts with the wider research community to explore why this matters and how we can bridge the AI language gap.
Our latest paper draws on our multi-year efforts with the wider research community to explore why this matters and how we can bridge the AI language gap.
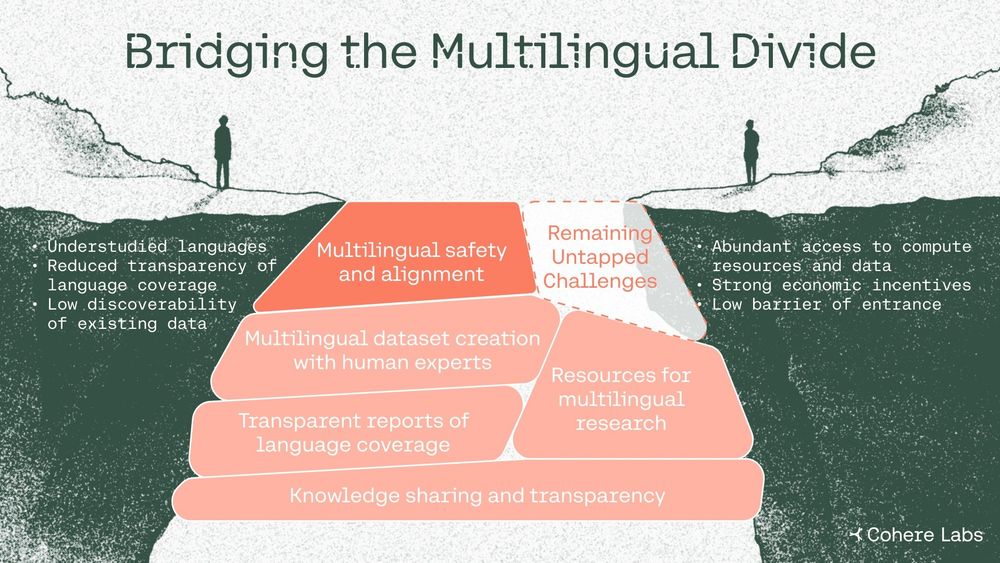
May 28, 2025 at 2:30 PM
Over 7000 languages are spoken worldwide 🌐, but AI safety efforts focus on only a fraction of them.
Our latest paper draws on our multi-year efforts with the wider research community to explore why this matters and how we can bridge the AI language gap.
Our latest paper draws on our multi-year efforts with the wider research community to explore why this matters and how we can bridge the AI language gap.
Reposted by Marzieh Fadaee

📢 The Copenhagen NLP Symposium on June 20th!
- Invited talks by @loubnabnl.hf.co (HF) @mziizm.bsky.social (Cohere) @najoung.bsky.social (BU) @kylelo.bsky.social (AI2) Yohei Oseki (UTokyo)
- Exciting posters by other participants
Register to attend and/or present your poster at cphnlp.github.io /1
- Invited talks by @loubnabnl.hf.co (HF) @mziizm.bsky.social (Cohere) @najoung.bsky.social (BU) @kylelo.bsky.social (AI2) Yohei Oseki (UTokyo)
- Exciting posters by other participants
Register to attend and/or present your poster at cphnlp.github.io /1
Copenhagen NLP Symposium 2025
symposium website
cphnlp.github.io
May 26, 2025 at 1:08 PM
📢 The Copenhagen NLP Symposium on June 20th!
- Invited talks by @loubnabnl.hf.co (HF) @mziizm.bsky.social (Cohere) @najoung.bsky.social (BU) @kylelo.bsky.social (AI2) Yohei Oseki (UTokyo)
- Exciting posters by other participants
Register to attend and/or present your poster at cphnlp.github.io /1
- Invited talks by @loubnabnl.hf.co (HF) @mziizm.bsky.social (Cohere) @najoung.bsky.social (BU) @kylelo.bsky.social (AI2) Yohei Oseki (UTokyo)
- Exciting posters by other participants
Register to attend and/or present your poster at cphnlp.github.io /1
Reposted by Marzieh Fadaee

It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.

April 30, 2025 at 2:55 PM
It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
Reposted by Marzieh Fadaee

Goodhart's law rules everything around me.

You know how Meta was allegedly manipulating results on Chatbot Arena for LLama 4? Well, Cohere and its cohorts wrote a paper about it.
Paper: The Leaderboard Illusion - arxiv.org/abs/2504.20879
Paper: The Leaderboard Illusion - arxiv.org/abs/2504.20879
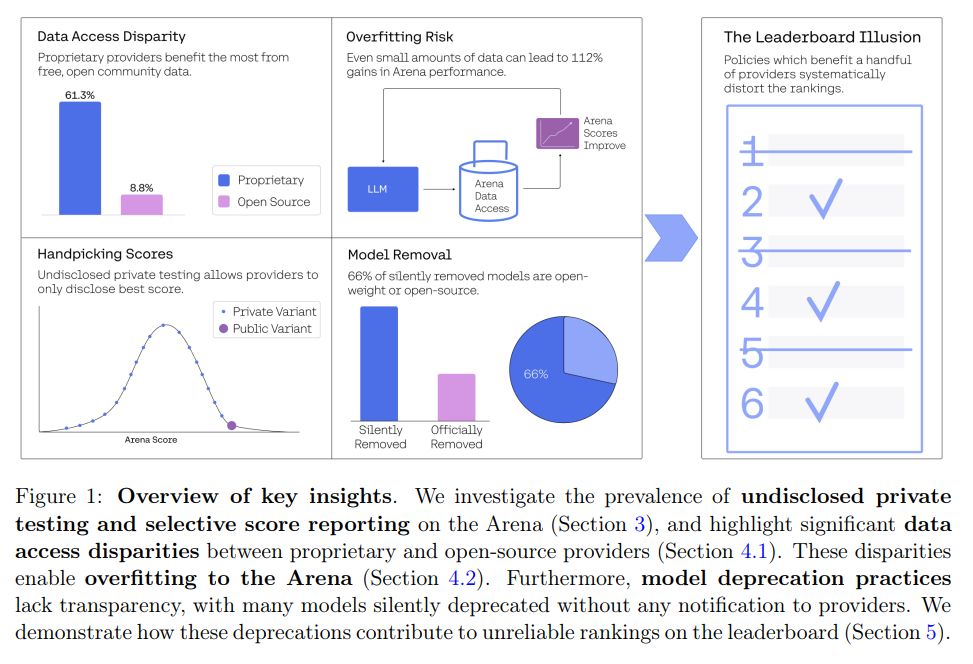
April 30, 2025 at 8:54 AM
Goodhart's law rules everything around me.
1/ Science is only as strong as the benchmarks it relies on.
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
April 30, 2025 at 12:53 PM
1/ Science is only as strong as the benchmarks it relies on.
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
Not in Singapore for #ICLR2025 but our lab’s work is! In particular, I am very proud of these collaborations:
✨INCLUDE (spotlight) — models fail to grasp regional nuances across languages
💎To Code or Not to Code (poster) — code is key for generalizing beyond coding tasks
✨INCLUDE (spotlight) — models fail to grasp regional nuances across languages
💎To Code or Not to Code (poster) — code is key for generalizing beyond coding tasks

April 22, 2025 at 8:15 AM
Not in Singapore for #ICLR2025 but our lab’s work is! In particular, I am very proud of these collaborations:
✨INCLUDE (spotlight) — models fail to grasp regional nuances across languages
💎To Code or Not to Code (poster) — code is key for generalizing beyond coding tasks
✨INCLUDE (spotlight) — models fail to grasp regional nuances across languages
💎To Code or Not to Code (poster) — code is key for generalizing beyond coding tasks
🚨 Excited to share our latest paper!
Multilingual LLMs are getting really good.
But the way we evaluate them? Not the best sometimes.
🌟 We show how decades of lessons from Machine Translation can help us fix it
Multilingual LLMs are getting really good.
But the way we evaluate them? Not the best sometimes.
🌟 We show how decades of lessons from Machine Translation can help us fix it
📖New preprint with Eleftheria Briakou @swetaagrawal.bsky.social @mziizm.bsky.social @kocmitom.bsky.social!
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…

April 17, 2025 at 8:25 PM
🚨 Excited to share our latest paper!
Multilingual LLMs are getting really good.
But the way we evaluate them? Not the best sometimes.
🌟 We show how decades of lessons from Machine Translation can help us fix it
Multilingual LLMs are getting really good.
But the way we evaluate them? Not the best sometimes.
🌟 We show how decades of lessons from Machine Translation can help us fix it
Very excited to release Kaleidoscope—a multilingual, multimodal evaluation set for VLMs, built as part of our open-science initiative!
🌍 18 languages (high-, mid-, low-)
📚 21k questions (55% require image understanding)
🧪 STEM, social science, reasoning, and practical skills
🌍 18 languages (high-, mid-, low-)
📚 21k questions (55% require image understanding)
🧪 STEM, social science, reasoning, and practical skills

April 10, 2025 at 7:52 PM
Very excited to release Kaleidoscope—a multilingual, multimodal evaluation set for VLMs, built as part of our open-science initiative!
🌍 18 languages (high-, mid-, low-)
📚 21k questions (55% require image understanding)
🧪 STEM, social science, reasoning, and practical skills
🌍 18 languages (high-, mid-, low-)
📚 21k questions (55% require image understanding)
🧪 STEM, social science, reasoning, and practical skills
Reposted by Marzieh Fadaee

Big news from WMT! 🎉 We are expanding beyond MT and launching a new multilingual instruction shared task. Our goal is to foster truly multilingual LLM evaluation and best practices in automatic and human evaluation. Join us and build the winning multilingual system!
www2.statmt.org/wmt25/multil...
www2.statmt.org/wmt25/multil...
Multilingual Instruction Shared Task
www2.statmt.org
March 11, 2025 at 6:26 PM
Big news from WMT! 🎉 We are expanding beyond MT and launching a new multilingual instruction shared task. Our goal is to foster truly multilingual LLM evaluation and best practices in automatic and human evaluation. Join us and build the winning multilingual system!
www2.statmt.org/wmt25/multil...
www2.statmt.org/wmt25/multil...
Reposted by Marzieh Fadaee
☀️ Summer internship at Cohere!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
March 28, 2025 at 4:44 PM
☀️ Summer internship at Cohere!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
Command🅰️ technical report is out. Information-dense. Detailed. Pretty. Simply A+!
💎: cohere.com/research/pap...
💎: cohere.com/research/pap...
March 27, 2025 at 4:54 PM
Command🅰️ technical report is out. Information-dense. Detailed. Pretty. Simply A+!
💎: cohere.com/research/pap...
💎: cohere.com/research/pap...

✨👓 Aya Vision is here 👓✨
A multilingual, multimodal model designed to understand across languages and modalities (text, images, etc) to bridge the language gap and empower global users!
A multilingual, multimodal model designed to understand across languages and modalities (text, images, etc) to bridge the language gap and empower global users!


March 4, 2025 at 5:11 PM
✨👓 Aya Vision is here 👓✨
A multilingual, multimodal model designed to understand across languages and modalities (text, images, etc) to bridge the language gap and empower global users!
A multilingual, multimodal model designed to understand across languages and modalities (text, images, etc) to bridge the language gap and empower global users!