



Tom Kocmi
@kocmitom.bsky.social
Researcher at Cohere | Multilingual LLM evaluation
Reposted by Tom Kocmi

How well do LLMs handle multilinguality? 🌍🤖
🔬We brought the rigor from Machine Translation evaluation to multilingual LLM benchmarking and organized the WMT25 Multilingual Instruction Shared Task spanning 30 languages and 5 subtasks.
🔬We brought the rigor from Machine Translation evaluation to multilingual LLM benchmarking and organized the WMT25 Multilingual Instruction Shared Task spanning 30 languages and 5 subtasks.

October 30, 2025 at 5:51 PM
How well do LLMs handle multilinguality? 🌍🤖
🔬We brought the rigor from Machine Translation evaluation to multilingual LLM benchmarking and organized the WMT25 Multilingual Instruction Shared Task spanning 30 languages and 5 subtasks.
🔬We brought the rigor from Machine Translation evaluation to multilingual LLM benchmarking and organized the WMT25 Multilingual Instruction Shared Task spanning 30 languages and 5 subtasks.
Reposted by Tom Kocmi

Ready for our poster today at #COLM2025!
💭This paper has had an interesting journey, come find out and discuss with us! @swetaagrawal.bsky.social @kocmitom.bsky.social
Side note: being a parent in research does have its perks, poster transportation solved ✅
💭This paper has had an interesting journey, come find out and discuss with us! @swetaagrawal.bsky.social @kocmitom.bsky.social
Side note: being a parent in research does have its perks, poster transportation solved ✅

October 8, 2025 at 12:16 PM
Ready for our poster today at #COLM2025!
💭This paper has had an interesting journey, come find out and discuss with us! @swetaagrawal.bsky.social @kocmitom.bsky.social
Side note: being a parent in research does have its perks, poster transportation solved ✅
💭This paper has had an interesting journey, come find out and discuss with us! @swetaagrawal.bsky.social @kocmitom.bsky.social
Side note: being a parent in research does have its perks, poster transportation solved ✅
🚩Machine Translation is far from “solved” - the test sets just got too easy. 🚩
Yes, the systems are much stronger. But the other half of the story is that test sets haven’t kept up. It’s no longer enough to just take a random news article and expect systems to stumble.
Yes, the systems are much stronger. But the other half of the story is that test sets haven’t kept up. It’s no longer enough to just take a random news article and expect systems to stumble.

Our new #EMNLP2025 paper is out: "Estimating Machine Translation Difficulty"! 🚀
Are today's #MachineTranslation systems flawless? When SOTA models all achieve near-perfect scores on standard benchmarks, we hit an evaluation ceiling. How can we tell their true capabilities and drive future progress?
Are today's #MachineTranslation systems flawless? When SOTA models all achieve near-perfect scores on standard benchmarks, we hit an evaluation ceiling. How can we tell their true capabilities and drive future progress?

September 16, 2025 at 9:51 AM
🚩Machine Translation is far from “solved” - the test sets just got too easy. 🚩
Yes, the systems are much stronger. But the other half of the story is that test sets haven’t kept up. It’s no longer enough to just take a random news article and expect systems to stumble.
Yes, the systems are much stronger. But the other half of the story is that test sets haven’t kept up. It’s no longer enough to just take a random news article and expect systems to stumble.
🚀 Thrilled to share what I’ve been working on at Cohere!
What began in January as a scribble in my notebook “how challenging would it be...” turned into a fully-fledged translation model that outperforms both open and closed-source systems, including long-standing MT leaders.
What began in January as a scribble in my notebook “how challenging would it be...” turned into a fully-fledged translation model that outperforms both open and closed-source systems, including long-standing MT leaders.

August 28, 2025 at 7:55 PM
🚀 Thrilled to share what I’ve been working on at Cohere!
What began in January as a scribble in my notebook “how challenging would it be...” turned into a fully-fledged translation model that outperforms both open and closed-source systems, including long-standing MT leaders.
What began in January as a scribble in my notebook “how challenging would it be...” turned into a fully-fledged translation model that outperforms both open and closed-source systems, including long-standing MT leaders.
📊 Preliminary ranking of WMT 2025 General Machine Translation benchmark is here!
But don't draw conclusions just yet - automatic metrics are biased for techniques like metric as a reward model or MBR. The official human ranking will be part of General MT findings at WMT.
arxiv.org/abs/2508.14909
But don't draw conclusions just yet - automatic metrics are biased for techniques like metric as a reward model or MBR. The official human ranking will be part of General MT findings at WMT.
arxiv.org/abs/2508.14909

Preliminary Ranking of WMT25 General Machine Translation Systems
We present the preliminary ranking of the WMT25 General Machine Translation Shared Task, in which MT systems have been evaluated using automatic metrics. As this ranking is based on automatic evaluati...
arxiv.org
August 23, 2025 at 9:28 AM
📊 Preliminary ranking of WMT 2025 General Machine Translation benchmark is here!
But don't draw conclusions just yet - automatic metrics are biased for techniques like metric as a reward model or MBR. The official human ranking will be part of General MT findings at WMT.
arxiv.org/abs/2508.14909
But don't draw conclusions just yet - automatic metrics are biased for techniques like metric as a reward model or MBR. The official human ranking will be part of General MT findings at WMT.
arxiv.org/abs/2508.14909
Hey, hey! 🎉 We’ve released the blind test set for this year’s WMT General MT and multilingual instruction tasks. Submit your systems to the special 20th anniversary of the conference and see how you compare to others!
The deadline is next week on 3rd July.
www2.statmt.org/wmt25/
The deadline is next week on 3rd July.
www2.statmt.org/wmt25/
WMT 2025
www2.statmt.org
June 26, 2025 at 6:09 PM
Hey, hey! 🎉 We’ve released the blind test set for this year’s WMT General MT and multilingual instruction tasks. Submit your systems to the special 20th anniversary of the conference and see how you compare to others!
The deadline is next week on 3rd July.
www2.statmt.org/wmt25/
The deadline is next week on 3rd July.
www2.statmt.org/wmt25/
Tired of messy non-replicable multilingual LLM evaluation? So were we.
In our new paper, we experimentally illustrate common eval. issues and present how structured evaluation design, transparent reporting, and meta-evaluation can help us to build stronger models.
In our new paper, we experimentally illustrate common eval. issues and present how structured evaluation design, transparent reporting, and meta-evaluation can help us to build stronger models.
📖New preprint with Eleftheria Briakou @swetaagrawal.bsky.social @mziizm.bsky.social @kocmitom.bsky.social!
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…

April 17, 2025 at 1:12 PM
Tired of messy non-replicable multilingual LLM evaluation? So were we.
In our new paper, we experimentally illustrate common eval. issues and present how structured evaluation design, transparent reporting, and meta-evaluation can help us to build stronger models.
In our new paper, we experimentally illustrate common eval. issues and present how structured evaluation design, transparent reporting, and meta-evaluation can help us to build stronger models.
☀️ Summer internship at Cohere!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
March 28, 2025 at 4:44 PM
☀️ Summer internship at Cohere!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
It’s here! Our new model’s technical report is out. I'm especially proud of the work we did on its multilingual capabilities - this was a massive, collective effort!

Today (two weeks after model launch 🔥) we're releasing a technical report of how we made Command A and R7B 🚀! It has detailed breakdowns of our training process, and evaluations per capability (tools, multilingual, code, reasoning, safety, enterprise, long context)🧵 1/3.
March 27, 2025 at 4:42 PM
It’s here! Our new model’s technical report is out. I'm especially proud of the work we did on its multilingual capabilities - this was a massive, collective effort!
Big news from WMT! 🎉 We are expanding beyond MT and launching a new multilingual instruction shared task. Our goal is to foster truly multilingual LLM evaluation and best practices in automatic and human evaluation. Join us and build the winning multilingual system!
www2.statmt.org/wmt25/multil...
www2.statmt.org/wmt25/multil...
Multilingual Instruction Shared Task
www2.statmt.org
March 11, 2025 at 6:26 PM
Big news from WMT! 🎉 We are expanding beyond MT and launching a new multilingual instruction shared task. Our goal is to foster truly multilingual LLM evaluation and best practices in automatic and human evaluation. Join us and build the winning multilingual system!
www2.statmt.org/wmt25/multil...
www2.statmt.org/wmt25/multil...
AI is evolving fast, and Aya Vision is proof of that. This open-weights model is designed to make LLM more powerful across languages and modalities, especially vision! Can’t wait to see the real-world applications, perhaps at WMT this year 😇
We hope Aya enables researchers and developers throughout the world to build upon this technology, ask deeper questions about multilingual AI, and develop tools that can support their communities.
Learn more:
cohere.com/blog/aya-vis...
Learn more:
cohere.com/blog/aya-vis...

Aya Vision: Expanding the Worlds AI Can See
Our state-of-the-art open-weights vision model offers a foundation for AI-enabled multilingual and multimodal communication globally.
Today, Cohere For AI, Cohere’s open research arm, is proud to an...
cohere.com
March 4, 2025 at 2:40 PM
AI is evolving fast, and Aya Vision is proof of that. This open-weights model is designed to make LLM more powerful across languages and modalities, especially vision! Can’t wait to see the real-world applications, perhaps at WMT this year 😇
Huge shoutout to colleagues at Google & Unbabel for extending our WMT24 testset to 55 languages in four domains, this is game changer! 🚀
I really hope it puts the final nail in the coffin of FLORES or WMT14. The field is evolving, legacy testsets can't show your progress
arxiv.org/abs/2502.124...
I really hope it puts the final nail in the coffin of FLORES or WMT14. The field is evolving, legacy testsets can't show your progress
arxiv.org/abs/2502.124...
WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, includin...
arxiv.org
March 1, 2025 at 8:30 PM
Huge shoutout to colleagues at Google & Unbabel for extending our WMT24 testset to 55 languages in four domains, this is game changer! 🚀
I really hope it puts the final nail in the coffin of FLORES or WMT14. The field is evolving, legacy testsets can't show your progress
arxiv.org/abs/2502.124...
I really hope it puts the final nail in the coffin of FLORES or WMT14. The field is evolving, legacy testsets can't show your progress
arxiv.org/abs/2502.124...
Guess what? The jubilee 🎉 20th iteration of WMT General MT 🎉 is here, and we want you to participate - as the entry barrier to make an impact is so low!
This isn’t just any repeat. We’ve kept what worked, removed what was outdated, and introduced many exciting new twists! Among the key changes are:
This isn’t just any repeat. We’ve kept what worked, removed what was outdated, and introduced many exciting new twists! Among the key changes are:
February 20, 2025 at 9:31 PM
Guess what? The jubilee 🎉 20th iteration of WMT General MT 🎉 is here, and we want you to participate - as the entry barrier to make an impact is so low!
This isn’t just any repeat. We’ve kept what worked, removed what was outdated, and introduced many exciting new twists! Among the key changes are:
This isn’t just any repeat. We’ve kept what worked, removed what was outdated, and introduced many exciting new twists! Among the key changes are:
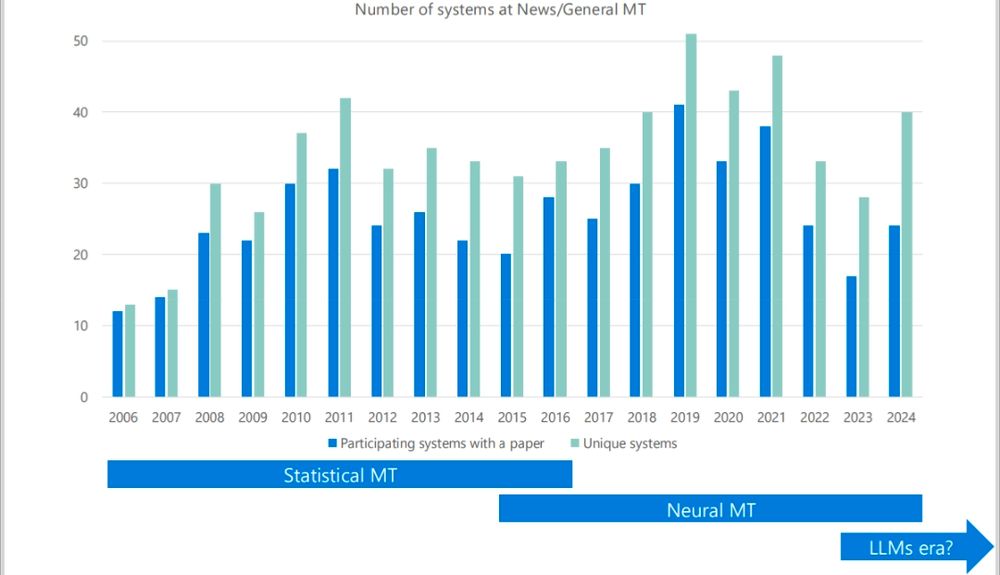
Exciting time at this year's WMT24 General MT Shared Task:
🚀 Participant numbers increased by over 50%!
🏗️ Decoder-only architectures are leading the way.
🔊 We've introduced a new speech audio modality domain.
🌐 Online systems are losing ground to LLMs.
🚀 Participant numbers increased by over 50%!
🏗️ Decoder-only architectures are leading the way.
🔊 We've introduced a new speech audio modality domain.
🌐 Online systems are losing ground to LLMs.
November 20, 2024 at 10:16 AM
Exciting time at this year's WMT24 General MT Shared Task:
🚀 Participant numbers increased by over 50%!
🏗️ Decoder-only architectures are leading the way.
🔊 We've introduced a new speech audio modality domain.
🌐 Online systems are losing ground to LLMs.
🚀 Participant numbers increased by over 50%!
🏗️ Decoder-only architectures are leading the way.
🔊 We've introduced a new speech audio modality domain.
🌐 Online systems are losing ground to LLMs.