


Julia Kreutzer
@juliakreutzer.bsky.social
NLP & ML research @cohereforai.bsky.social 🇨🇦
Reposted by Julia Kreutzer

We’re thrilled to announce that some of our research will be presented at @emnlpmeeting.bsky.social next week! 🥳
If you’re attending the conference, don’t miss the chance to explore our work and connect with our team.
If you’re attending the conference, don’t miss the chance to explore our work and connect with our team.

October 29, 2025 at 6:31 PM
We’re thrilled to announce that some of our research will be presented at @emnlpmeeting.bsky.social next week! 🥳
If you’re attending the conference, don’t miss the chance to explore our work and connect with our team.
If you’re attending the conference, don’t miss the chance to explore our work and connect with our team.
Reposted by Julia Kreutzer
How well do LLMs handle multilinguality? 🌍🤖
🔬We brought the rigor from Machine Translation evaluation to multilingual LLM benchmarking and organized the WMT25 Multilingual Instruction Shared Task spanning 30 languages and 5 subtasks.
🔬We brought the rigor from Machine Translation evaluation to multilingual LLM benchmarking and organized the WMT25 Multilingual Instruction Shared Task spanning 30 languages and 5 subtasks.

October 30, 2025 at 5:51 PM
How well do LLMs handle multilinguality? 🌍🤖
🔬We brought the rigor from Machine Translation evaluation to multilingual LLM benchmarking and organized the WMT25 Multilingual Instruction Shared Task spanning 30 languages and 5 subtasks.
🔬We brought the rigor from Machine Translation evaluation to multilingual LLM benchmarking and organized the WMT25 Multilingual Instruction Shared Task spanning 30 languages and 5 subtasks.
Reposted by Julia Kreutzer
🌍Most multilingual instruction data starts as English and translation can’t capture cultural nuance or linguistic richness
What if we optimized prompts instead of completions?
That’s the focus of our most recent work on prompt space optimization for multilingual synthetic data🗣️
What if we optimized prompts instead of completions?
That’s the focus of our most recent work on prompt space optimization for multilingual synthetic data🗣️

October 23, 2025 at 2:39 PM
🌍Most multilingual instruction data starts as English and translation can’t capture cultural nuance or linguistic richness
What if we optimized prompts instead of completions?
That’s the focus of our most recent work on prompt space optimization for multilingual synthetic data🗣️
What if we optimized prompts instead of completions?
That’s the focus of our most recent work on prompt space optimization for multilingual synthetic data🗣️
Reposted by Julia Kreutzer

The next generation of open LLMs should be inclusive, compliant, and multilingual by design. That’s why we @icepfl.bsky.social @ethz.ch @cscsch.bsky.social ) built Apertus.

EPFL, ETH Zurich & CSCS just released Apertus, Switzerland’s first fully open-source large language model.
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...

September 3, 2025 at 9:26 AM
The next generation of open LLMs should be inclusive, compliant, and multilingual by design. That’s why we @icepfl.bsky.social @ethz.ch @cscsch.bsky.social ) built Apertus.

Looking forward to tomorrow's #COLM2025 workshop on multilingual data quality! 🤩

In collaboration with @commoncrawl.bsky.social, MLCommons, and @eleutherai.bsky.social, the first edition of WMDQS at @colmweb.org starts tomorrow in Room 520A! We have an updated schedule on our website, including a list of all accepted papers.

October 9, 2025 at 11:16 PM
Looking forward to tomorrow's #COLM2025 workshop on multilingual data quality! 🤩
Ready for our poster today at #COLM2025!
💭This paper has had an interesting journey, come find out and discuss with us! @swetaagrawal.bsky.social @kocmitom.bsky.social
Side note: being a parent in research does have its perks, poster transportation solved ✅
💭This paper has had an interesting journey, come find out and discuss with us! @swetaagrawal.bsky.social @kocmitom.bsky.social
Side note: being a parent in research does have its perks, poster transportation solved ✅

October 8, 2025 at 12:16 PM
Ready for our poster today at #COLM2025!
💭This paper has had an interesting journey, come find out and discuss with us! @swetaagrawal.bsky.social @kocmitom.bsky.social
Side note: being a parent in research does have its perks, poster transportation solved ✅
💭This paper has had an interesting journey, come find out and discuss with us! @swetaagrawal.bsky.social @kocmitom.bsky.social
Side note: being a parent in research does have its perks, poster transportation solved ✅
Reposted by Julia Kreutzer
We’re not your average lab. We’re a hybrid research environment dedicated to revolutionizing the ML space.
And we’re hiring a Senior Research Scientist to co-create with us.
If you believe in research as a shared, global effort — this is your chance.
And we’re hiring a Senior Research Scientist to co-create with us.
If you believe in research as a shared, global effort — this is your chance.

September 30, 2025 at 10:00 AM
We’re not your average lab. We’re a hybrid research environment dedicated to revolutionizing the ML space.
And we’re hiring a Senior Research Scientist to co-create with us.
If you believe in research as a shared, global effort — this is your chance.
And we’re hiring a Senior Research Scientist to co-create with us.
If you believe in research as a shared, global effort — this is your chance.
💡A collaborative➕diverse team is key. In real life as in the LLM world 💪🦾
Check out our latest work that builds on this insight. 👇
Check out our latest work that builds on this insight. 👇
Is Best-of-N really the best use of your inference compute?
Introducing Fusion-of-N: a simple and powerful way to advance inference and distillation beyond Best-of-N.
Introducing Fusion-of-N: a simple and powerful way to advance inference and distillation beyond Best-of-N.

October 2, 2025 at 2:10 PM
💡A collaborative➕diverse team is key. In real life as in the LLM world 💪🦾
Check out our latest work that builds on this insight. 👇
Check out our latest work that builds on this insight. 👇
Reposted by Julia Kreutzer

Breaking into AI research is harder than ever, and early-career researchers face fewer chances to get started.
Entry points matter.
We started the Scholars Program 3 years ago to give new researchers a real shot — excited to open applications for year 4✨
Entry points matter.
We started the Scholars Program 3 years ago to give new researchers a real shot — excited to open applications for year 4✨
Applications are now open for the next cohort of the Cohere Labs Scholars Program! 🌟
This is your chance to collaborate with some of the brightest minds in AI & chart new courses in ML research. Let's change the spaces breakthroughs happen.
Apply by Aug 29.
This is your chance to collaborate with some of the brightest minds in AI & chart new courses in ML research. Let's change the spaces breakthroughs happen.
Apply by Aug 29.

August 13, 2025 at 2:42 PM
Breaking into AI research is harder than ever, and early-career researchers face fewer chances to get started.
Entry points matter.
We started the Scholars Program 3 years ago to give new researchers a real shot — excited to open applications for year 4✨
Entry points matter.
We started the Scholars Program 3 years ago to give new researchers a real shot — excited to open applications for year 4✨
Reposted by Julia Kreutzer
While effective for chess♟️, Elo ratings struggle with LLM evaluation due to volatility and transitivity issues.
New post in collaboration with AI Singapore explores why Elo falls short for AI leaderboards and how we can do better.
New post in collaboration with AI Singapore explores why Elo falls short for AI leaderboards and how we can do better.

August 15, 2025 at 5:04 AM
While effective for chess♟️, Elo ratings struggle with LLM evaluation due to volatility and transitivity issues.
New post in collaboration with AI Singapore explores why Elo falls short for AI leaderboards and how we can do better.
New post in collaboration with AI Singapore explores why Elo falls short for AI leaderboards and how we can do better.
Reposted by Julia Kreutzer

COLM 2025 is now accepting applications for:
Financial Assistance Application -- docs.google.com/forms/d/e/1F...
Volunteer Application -- docs.google.com/forms/d/e/1F...
Childcare Financial Assistance Application -- docs.google.com/forms/d/e/1F...
All due by July 31
Financial Assistance Application -- docs.google.com/forms/d/e/1F...
Volunteer Application -- docs.google.com/forms/d/e/1F...
Childcare Financial Assistance Application -- docs.google.com/forms/d/e/1F...
All due by July 31

COLM 2025 Financial Assistance Application
Goal of the Financial Assistance Program. We at COLM believe our community should be diverse and inclusive. We recognize that some might be less likely to attend because of financial burden of travel ...
docs.google.com
July 14, 2025 at 8:51 PM
COLM 2025 is now accepting applications for:
Financial Assistance Application -- docs.google.com/forms/d/e/1F...
Volunteer Application -- docs.google.com/forms/d/e/1F...
Childcare Financial Assistance Application -- docs.google.com/forms/d/e/1F...
All due by July 31
Financial Assistance Application -- docs.google.com/forms/d/e/1F...
Volunteer Application -- docs.google.com/forms/d/e/1F...
Childcare Financial Assistance Application -- docs.google.com/forms/d/e/1F...
All due by July 31
🍋 Squeezing the most of few samples - check out our LLMonade recipe for few-sample test-time scaling in multitask environments.
Turns out that standard methods miss out on gains on non-English languages. We propose more robust alternatives.
Very proud of this work that our scholar Ammar led! 🚀
Turns out that standard methods miss out on gains on non-English languages. We propose more robust alternatives.
Very proud of this work that our scholar Ammar led! 🚀
Can we improve the performance of LLMs during inference without the need for extensive sampling OR special reward models? 🤔
Our latest work introduces a new inference time scaling recipe that is sample-efficient, multilingual, and suitable for multi-task requirements. 🍋
Our latest work introduces a new inference time scaling recipe that is sample-efficient, multilingual, and suitable for multi-task requirements. 🍋

June 26, 2025 at 6:17 PM
🍋 Squeezing the most of few samples - check out our LLMonade recipe for few-sample test-time scaling in multitask environments.
Turns out that standard methods miss out on gains on non-English languages. We propose more robust alternatives.
Very proud of this work that our scholar Ammar led! 🚀
Turns out that standard methods miss out on gains on non-English languages. We propose more robust alternatives.
Very proud of this work that our scholar Ammar led! 🚀
🚨LLM safety research needs to be at least as multilingual as our models.
What's the current stage and how to progress from here?
This work led by @yongzx.bsky.social has answers! 👇
What's the current stage and how to progress from here?
This work led by @yongzx.bsky.social has answers! 👇
It’s been two years since cross-lingual jailbreaks were first discovered. How far has the multilingual LLM safety research field advanced? 🤔
📏 Our comprehensive survey reveals that there is still a long way to go.
📏 Our comprehensive survey reveals that there is still a long way to go.

June 4, 2025 at 11:44 AM
🚨LLM safety research needs to be at least as multilingual as our models.
What's the current stage and how to progress from here?
This work led by @yongzx.bsky.social has answers! 👇
What's the current stage and how to progress from here?
This work led by @yongzx.bsky.social has answers! 👇
🚧No LLM safety without multilingual safety - what is missing to closing the language gap? And where does this gap actually originate from?
Answers 👇
Answers 👇
Over 7000 languages are spoken worldwide 🌐, but AI safety efforts focus on only a fraction of them.
Our latest paper draws on our multi-year efforts with the wider research community to explore why this matters and how we can bridge the AI language gap.
Our latest paper draws on our multi-year efforts with the wider research community to explore why this matters and how we can bridge the AI language gap.
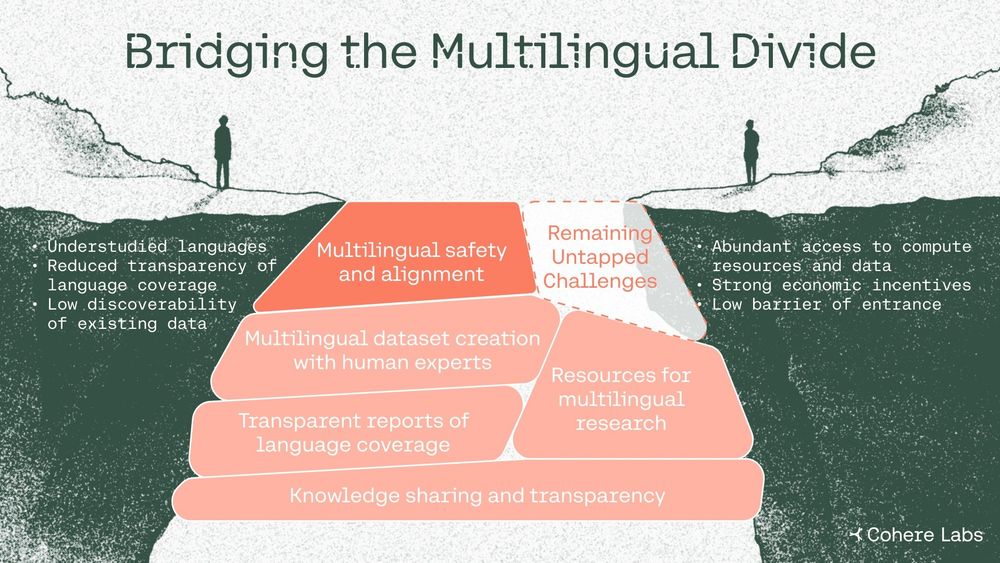
May 28, 2025 at 3:25 PM
🚧No LLM safety without multilingual safety - what is missing to closing the language gap? And where does this gap actually originate from?
Answers 👇
Answers 👇
Multilingual 🤝reasoning 🤝 test-time scaling 🔥🔥🔥
New preprint!
@yongzx.bsky.social has all the details 👇
New preprint!
@yongzx.bsky.social has all the details 👇

📣 New paper!
We observe that reasoning language models finetuned only on English data are capable of zero-shot cross-lingual reasoning through a "quote-and-think" pattern.
However, this does not mean they reason the same way across all languages or in new domains.
[1/N]
We observe that reasoning language models finetuned only on English data are capable of zero-shot cross-lingual reasoning through a "quote-and-think" pattern.
However, this does not mean they reason the same way across all languages or in new domains.
[1/N]

May 9, 2025 at 8:00 PM
Multilingual 🤝reasoning 🤝 test-time scaling 🔥🔥🔥
New preprint!
@yongzx.bsky.social has all the details 👇
New preprint!
@yongzx.bsky.social has all the details 👇
Reposted by Julia Kreutzer
1/ Science is only as strong as the benchmarks it relies on.
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵

April 30, 2025 at 12:53 PM
1/ Science is only as strong as the benchmarks it relies on.
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
🤓MT eyes on multilingual LLM benchmarks 👉 Here's a bunch of simple techniques that we could adopt easily, and in total get a much richer understanding of where we are with multilingual LLMs.
🍬Bonus question: how can we spur research on evaluation of evaluations?
🍬Bonus question: how can we spur research on evaluation of evaluations?
🚀🌍The rapid advancement of multilingual large language models (mLLMs) is exciting, but are we evaluating them effectively?
Our new paper explores how we can improve generative evaluations for mLLMs by learning from machine translation (MT) evaluation practices. 🔎
Our new paper explores how we can improve generative evaluations for mLLMs by learning from machine translation (MT) evaluation practices. 🔎

April 17, 2025 at 6:33 PM
🤓MT eyes on multilingual LLM benchmarks 👉 Here's a bunch of simple techniques that we could adopt easily, and in total get a much richer understanding of where we are with multilingual LLMs.
🍬Bonus question: how can we spur research on evaluation of evaluations?
🍬Bonus question: how can we spur research on evaluation of evaluations?
Reposted by Julia Kreutzer

Tired of messy non-replicable multilingual LLM evaluation? So were we.
In our new paper, we experimentally illustrate common eval. issues and present how structured evaluation design, transparent reporting, and meta-evaluation can help us to build stronger models.
In our new paper, we experimentally illustrate common eval. issues and present how structured evaluation design, transparent reporting, and meta-evaluation can help us to build stronger models.
📖New preprint with Eleftheria Briakou @swetaagrawal.bsky.social @mziizm.bsky.social @kocmitom.bsky.social!
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…

April 17, 2025 at 1:12 PM
Tired of messy non-replicable multilingual LLM evaluation? So were we.
In our new paper, we experimentally illustrate common eval. issues and present how structured evaluation design, transparent reporting, and meta-evaluation can help us to build stronger models.
In our new paper, we experimentally illustrate common eval. issues and present how structured evaluation design, transparent reporting, and meta-evaluation can help us to build stronger models.
📖New preprint with Eleftheria Briakou @swetaagrawal.bsky.social @mziizm.bsky.social @kocmitom.bsky.social!
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…
April 17, 2025 at 10:56 AM
📖New preprint with Eleftheria Briakou @swetaagrawal.bsky.social @mziizm.bsky.social @kocmitom.bsky.social!
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…
arxiv.org/abs/2504.11829
🌍It reflects experiences from my personal research journey: coming from MT into multilingual LLM research I missed reliable evaluations and evaluation research…
Reposted by Julia Kreutzer
🚀 We are excited to introduce Kaleidoscope, the largest culturally-authentic exam benchmark.
📌 Most VLM benchmarks are English-centric or rely on translations—missing linguistic & cultural nuance. Kaleidoscope expands in-language multilingual 🌎 & multimodal 👀 VLMs evaluation
📌 Most VLM benchmarks are English-centric or rely on translations—missing linguistic & cultural nuance. Kaleidoscope expands in-language multilingual 🌎 & multimodal 👀 VLMs evaluation

April 10, 2025 at 8:24 PM
🚀 We are excited to introduce Kaleidoscope, the largest culturally-authentic exam benchmark.
📌 Most VLM benchmarks are English-centric or rely on translations—missing linguistic & cultural nuance. Kaleidoscope expands in-language multilingual 🌎 & multimodal 👀 VLMs evaluation
📌 Most VLM benchmarks are English-centric or rely on translations—missing linguistic & cultural nuance. Kaleidoscope expands in-language multilingual 🌎 & multimodal 👀 VLMs evaluation
Reposted by Julia Kreutzer
☀️ Summer internship at Cohere!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
March 28, 2025 at 4:44 PM
☀️ Summer internship at Cohere!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
Are you excited about multilingual evaluation, human judgment, or meta-eval? Come help us explore how a rigorous eval really looks like while questioning the status quo in LLM evaluation.
I’m looking for an intern (EU timezone preferred), are you interested? Ping me!
Reposted by Julia Kreutzer
Command🅰️ technical report is out. Information-dense. Detailed. Pretty. Simply A+!
💎: cohere.com/research/pap...
💎: cohere.com/research/pap...
March 27, 2025 at 4:54 PM
Command🅰️ technical report is out. Information-dense. Detailed. Pretty. Simply A+!
💎: cohere.com/research/pap...
💎: cohere.com/research/pap...
Reposted by Julia Kreutzer
A bit of a mess around the conflict of COLM with the ARR (and to lesser degree ICML) reviews release. We feel this is creating a lot of pressure and uncertainty. So, we are pushing our deadlines:
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏

March 20, 2025 at 6:20 PM
A bit of a mess around the conflict of COLM with the ARR (and to lesser degree ICML) reviews release. We feel this is creating a lot of pressure and uncertainty. So, we are pushing our deadlines:
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
💬The first Q&A starts in a few hours.
🔔Also, a reminder to create your Open review profile if you haven't already. Non-institutional accounts require a verification process that can take time. One week till the abstract deadline!
🔔Also, a reminder to create your Open review profile if you haven't already. Non-institutional accounts require a verification process that can take time. One week till the abstract deadline!
COLM's @juliakreutzer.bsky.social and @abosselut.bsky.social will hold two paper submission Q&A sessions. We run a simple process, but figured this can help authors, especially first-time authors.
March 12: dateful.com/eventlink/14...
March 13: dateful.com/eventlink/83...
Plz RT 🙏
March 12: dateful.com/eventlink/14...
March 13: dateful.com/eventlink/83...
Plz RT 🙏

March 12, 2025 at 2:42 PM
💬The first Q&A starts in a few hours.
🔔Also, a reminder to create your Open review profile if you haven't already. Non-institutional accounts require a verification process that can take time. One week till the abstract deadline!
🔔Also, a reminder to create your Open review profile if you haven't already. Non-institutional accounts require a verification process that can take time. One week till the abstract deadline!