




Ian Magnusson
@ianmagnusson.bsky.social
Science of language models @uwnlp.bsky.social and @ai2.bsky.social with @PangWeiKoh and @nlpnoah.bsky.social. https://ianmagnusson.github.io
And amazing colleagues @davidheineman.com eineman.com, Jena Hwang, @soldaini.net, @akshitab.bsky.social , @liujch1998.bsky.social, @mechanicaldirk.bsky.social, @oyvind-t.bsky.social, @nlpnoah.bsky.social, Pang Wei Koh, @jessedodge.bsky.social. Wouldn’t have been possible without all of them.
eineman.com
April 15, 2025 at 7:36 PM
And amazing colleagues @davidheineman.com eineman.com, Jena Hwang, @soldaini.net, @akshitab.bsky.social , @liujch1998.bsky.social, @mechanicaldirk.bsky.social, @oyvind-t.bsky.social, @nlpnoah.bsky.social, Pang Wei Koh, @jessedodge.bsky.social. Wouldn’t have been possible without all of them.
I’m so grateful for all the hard work and good cheer of my co-first authors @taidnguyen.bsky.social and @benbogin.bsky.social ... 🧵
April 15, 2025 at 7:36 PM
I’m so grateful for all the hard work and good cheer of my co-first authors @taidnguyen.bsky.social and @benbogin.bsky.social ... 🧵
And also check out our updated paper arxiv.org/abs/2312.10523
December 10, 2024 at 4:00 AM
And also check out our updated paper arxiv.org/abs/2312.10523
Drop by our poster presentation Friday (12/13) at 4:30-7:30pm neurips.cc/virtual/2024...
NeurIPS Poster Paloma: A Benchmark for Evaluating Language Model FitNeurIPS 2024
neurips.cc
December 10, 2024 at 3:58 AM
Drop by our poster presentation Friday (12/13) at 4:30-7:30pm neurips.cc/virtual/2024...
Collaboration with @akshitab.bsky.social, @valentinhofmann.bsky.social, @soldaini.net i.net, @ananyahjha93.bsky.social, Oyvind Tafjord, Dustin Schwenk, Pete Walsh, @yanai.bsky.social, @kylelo.bsky.social , Dirk Groeneveld, Iz Beltagy, Hanna Hajishirzi, Noah Smith, Kyle Richardson, and Jesse Dodge
December 20, 2023 at 8:41 PM
Collaboration with @akshitab.bsky.social, @valentinhofmann.bsky.social, @soldaini.net i.net, @ananyahjha93.bsky.social, Oyvind Tafjord, Dustin Schwenk, Pete Walsh, @yanai.bsky.social, @kylelo.bsky.social , Dirk Groeneveld, Iz Beltagy, Hanna Hajishirzi, Noah Smith, Kyle Richardson, and Jesse Dodge
We invite submissions at github.com/allenai/ai2-.... Submissions can opt in to controls, or mark limitations to comparability. More than being a one-dimensional leaderboard, Paloma orchestrates fine-grained results for a greater density of comparisons across the research community.
December 20, 2023 at 8:33 PM
We invite submissions at github.com/allenai/ai2-.... Submissions can opt in to controls, or mark limitations to comparability. More than being a one-dimensional leaderboard, Paloma orchestrates fine-grained results for a greater density of comparisons across the research community.
Further decomposing perplexity, we find that some vocabulary strings get worse as models scale (see examples) ✍️
Again, not always bad, but Paloma reports average loss of each vocabulary string, surfacing strings that behave differently in some domains.
Again, not always bad, but Paloma reports average loss of each vocabulary string, surfacing strings that behave differently in some domains.
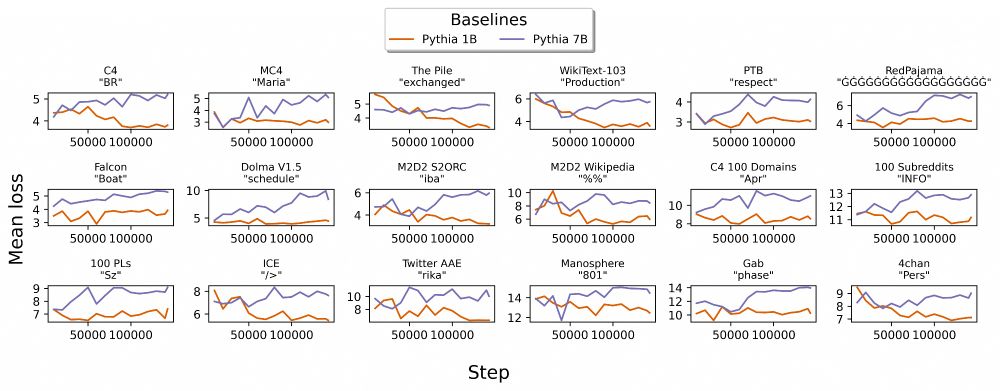
December 20, 2023 at 8:33 PM
Further decomposing perplexity, we find that some vocabulary strings get worse as models scale (see examples) ✍️
Again, not always bad, but Paloma reports average loss of each vocabulary string, surfacing strings that behave differently in some domains.
Again, not always bad, but Paloma reports average loss of each vocabulary string, surfacing strings that behave differently in some domains.
We also show that performance improves in almost all domains as models are scaled, but domains improve unequally 📈📉
Differences in improvement, such as these examples, can indicate divergence, stagnation, or saturation—not all bad, but worth investigating!
Differences in improvement, such as these examples, can indicate divergence, stagnation, or saturation—not all bad, but worth investigating!
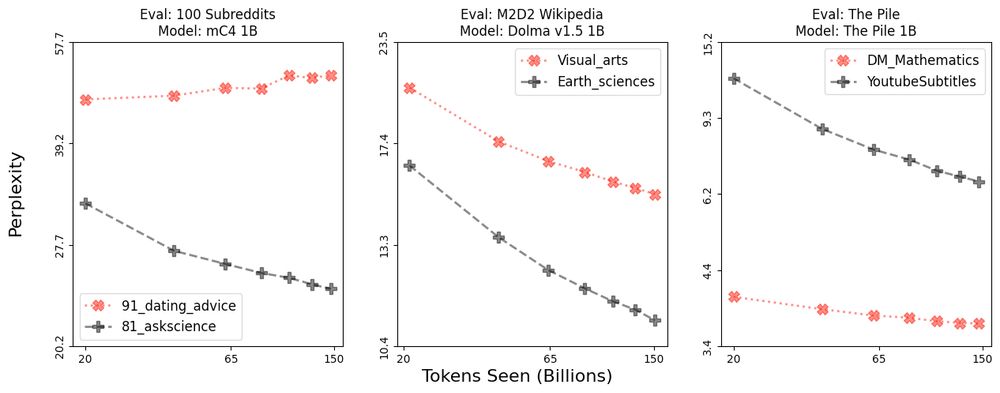
December 20, 2023 at 8:33 PM
We also show that performance improves in almost all domains as models are scaled, but domains improve unequally 📈📉
Differences in improvement, such as these examples, can indicate divergence, stagnation, or saturation—not all bad, but worth investigating!
Differences in improvement, such as these examples, can indicate divergence, stagnation, or saturation—not all bad, but worth investigating!
We pretrain six 1B baselines on popular corpora 🤖
With these we find Common-Crawl-only pretraining has inconsistent fit to many domains:
1. C4 and mC4 baselines erratically worse fit than median model
2. C4, mC4, and Falcon baselines sometimes non-monotonic perplexity in Fig 1
With these we find Common-Crawl-only pretraining has inconsistent fit to many domains:
1. C4 and mC4 baselines erratically worse fit than median model
2. C4, mC4, and Falcon baselines sometimes non-monotonic perplexity in Fig 1
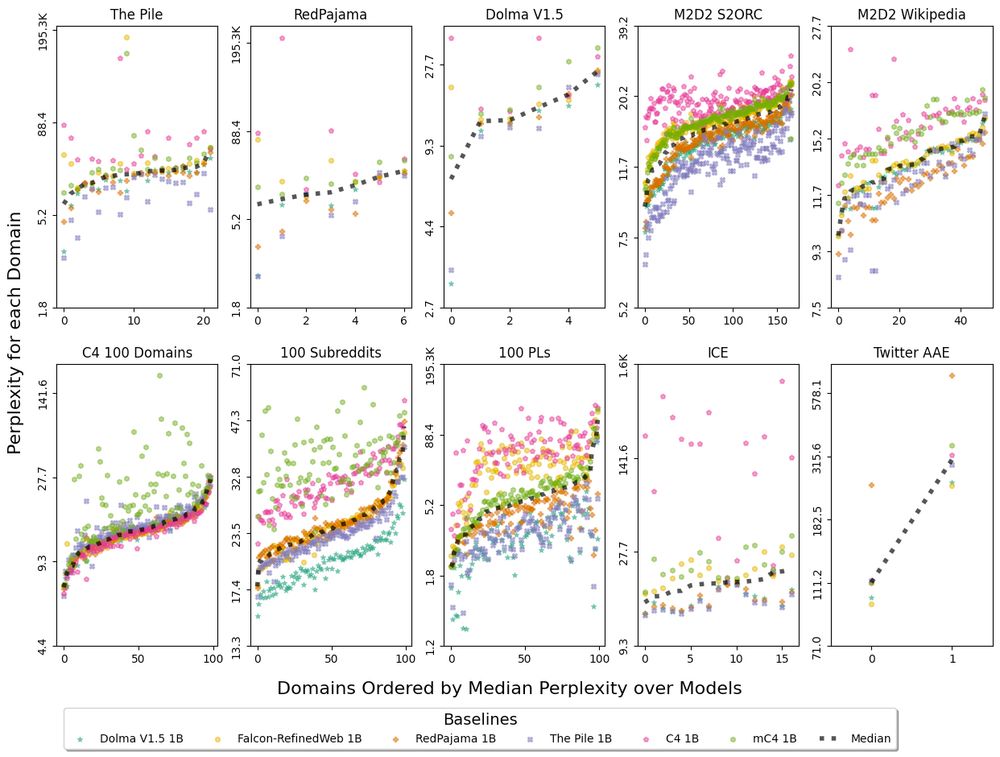
December 20, 2023 at 8:32 PM
We pretrain six 1B baselines on popular corpora 🤖
With these we find Common-Crawl-only pretraining has inconsistent fit to many domains:
1. C4 and mC4 baselines erratically worse fit than median model
2. C4, mC4, and Falcon baselines sometimes non-monotonic perplexity in Fig 1
With these we find Common-Crawl-only pretraining has inconsistent fit to many domains:
1. C4 and mC4 baselines erratically worse fit than median model
2. C4, mC4, and Falcon baselines sometimes non-monotonic perplexity in Fig 1
Along with the datasets we curate, we build eval corpora from held out Dolma data that sample:
💬 top 100 subreddits
🧑💻 top 100 programming languages
Different research may require other domains, but Paloma enables research on 100s of domains from existing metadata.
💬 top 100 subreddits
🧑💻 top 100 programming languages
Different research may require other domains, but Paloma enables research on 100s of domains from existing metadata.
December 20, 2023 at 8:30 PM
Along with the datasets we curate, we build eval corpora from held out Dolma data that sample:
💬 top 100 subreddits
🧑💻 top 100 programming languages
Different research may require other domains, but Paloma enables research on 100s of domains from existing metadata.
💬 top 100 subreddits
🧑💻 top 100 programming languages
Different research may require other domains, but Paloma enables research on 100s of domains from existing metadata.
We introduce guidelines and implement controls for LM experiments 📋:
1. Remove contaminated pretraining
2. Fix train order
3. Subsample eval data based on metric variance
4. Fix the vocabulary unless you study changing it
5. Standardize eval format
1. Remove contaminated pretraining
2. Fix train order
3. Subsample eval data based on metric variance
4. Fix the vocabulary unless you study changing it
5. Standardize eval format

December 20, 2023 at 8:30 PM
We introduce guidelines and implement controls for LM experiments 📋:
1. Remove contaminated pretraining
2. Fix train order
3. Subsample eval data based on metric variance
4. Fix the vocabulary unless you study changing it
5. Standardize eval format
1. Remove contaminated pretraining
2. Fix train order
3. Subsample eval data based on metric variance
4. Fix the vocabulary unless you study changing it
5. Standardize eval format