



Jiacheng Liu
@liujch1998.bsky.social
🎓 PhD student @uwcse @uwnlp. 🛩 Private pilot. Previously: 🧑💻 @oculus, 🎓 @IllinoisCS. 📖 🥾 🚴♂️ 🎵 ♠️
Pinned
Jiacheng Liu
@liujch1998.bsky.social
· Apr 9
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting?
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
Reposted by Jiacheng Liu

How can we better understand how models make predictions and which components of a training dataset are shaping their behaviors? In April we introduced OLMoTrace, a feature that lets you trace the outputs of language models back to their full training data in real time. 🧵
June 30, 2025 at 5:37 PM
How can we better understand how models make predictions and which components of a training dataset are shaping their behaviors? In April we introduced OLMoTrace, a feature that lets you trace the outputs of language models back to their full training data in real time. 🧵
Reposted by Jiacheng Liu
As we’ve been working towards training a new version of OLMo, we wanted to improve our methods for measuring the Critical Batch Size (CBS) of a training run, to unlock greater efficiency. but we found gaps between the methods in the literature and our practical needs for training OLMo. 🧵

June 3, 2025 at 4:43 PM
As we’ve been working towards training a new version of OLMo, we wanted to improve our methods for measuring the Critical Batch Size (CBS) of a training run, to unlock greater efficiency. but we found gaps between the methods in the literature and our practical needs for training OLMo. 🧵
Reposted by Jiacheng Liu

Congratulations to #UWAllen Ph.D. grads Ashish Sharma and @sewonm.bsky.social, 2024 @acm.org Doctoral Dissertation Award honorees! Sharma won for #AI tools for mental health; Min received honorable mention for efficient, flexible language models. #ThisIsUW news.cs.washington.edu/2025/06/04/a...

‘Bold,’ ‘positive’ and ‘unparalleled’: Allen School Ph.D. graduates Ashish Sharma and Sewon Min recognized with ACM Doctoral Dissertation Awards - Allen School News
Each year, the Association for Computing Machinery recognizes the best Ph.D. dissertations in computer science with its Doctoral Dissertation Award. Ashish Sharma (Ph.D., ‘24), now a senior applied sc...
news.cs.washington.edu
June 4, 2025 at 7:27 PM
Congratulations to #UWAllen Ph.D. grads Ashish Sharma and @sewonm.bsky.social, 2024 @acm.org Doctoral Dissertation Award honorees! Sharma won for #AI tools for mental health; Min received honorable mention for efficient, flexible language models. #ThisIsUW news.cs.washington.edu/2025/06/04/a...
Reposted by Jiacheng Liu

I’m thrilled to share RewardBench 2 📊— We created a new multi-domain reward model evaluation that is substantially harder than RewardBench, we trained and released 70 reward models, and we gained insights about reward modeling benchmarks and downstream performance!

June 2, 2025 at 11:41 PM
I’m thrilled to share RewardBench 2 📊— We created a new multi-domain reward model evaluation that is substantially harder than RewardBench, we trained and released 70 reward models, and we gained insights about reward modeling benchmarks and downstream performance!
Reposted by Jiacheng Liu
📢We’re taking your questions now on Reddit for tomorrow’s AMA!
Ask us anything about OLMo, our family of fully-open language models. Our researchers will be on hand to answer them Thursday, May 8 at 8am PST.
Ask us anything about OLMo, our family of fully-open language models. Our researchers will be on hand to answer them Thursday, May 8 at 8am PST.

May 7, 2025 at 4:46 PM
📢We’re taking your questions now on Reddit for tomorrow’s AMA!
Ask us anything about OLMo, our family of fully-open language models. Our researchers will be on hand to answer them Thursday, May 8 at 8am PST.
Ask us anything about OLMo, our family of fully-open language models. Our researchers will be on hand to answer them Thursday, May 8 at 8am PST.
Reposted by Jiacheng Liu
The story of OLMo, our Open Language Model, goes back to February 2023 when a group of researchers gathered at Ai2 and started planning. What if we made a language model with state-of-the-art performance, but we did it completely in the open? 🧵
May 6, 2025 at 8:55 PM
The story of OLMo, our Open Language Model, goes back to February 2023 when a group of researchers gathered at Ai2 and started planning. What if we made a language model with state-of-the-art performance, but we did it completely in the open? 🧵
Reposted by Jiacheng Liu
We're excited to round out the OLMo 2 family with its smallest member, OLMo 2 1B, surpassing peer models like Gemma 3 1B or Llama 3.2 1B. The 1B model should enable rapid iteration for researchers, more local development, and a more complete picture of how our recipe scales.

May 1, 2025 at 1:01 PM
We're excited to round out the OLMo 2 family with its smallest member, OLMo 2 1B, surpassing peer models like Gemma 3 1B or Llama 3.2 1B. The 1B model should enable rapid iteration for researchers, more local development, and a more complete picture of how our recipe scales.
Reposted by Jiacheng Liu
Have questions? We’re an open book!
We’re excited to host an AMA to answer your Qs about OLMo, our family of open language models.
🗓️ When: May 8, 8-10 am PT
🌐 Where: r/huggingface
🧠 Why: Gain insights from our expert researchers
Chat soon!
We’re excited to host an AMA to answer your Qs about OLMo, our family of open language models.
🗓️ When: May 8, 8-10 am PT
🌐 Where: r/huggingface
🧠 Why: Gain insights from our expert researchers
Chat soon!

May 1, 2025 at 5:58 PM
Have questions? We’re an open book!
We’re excited to host an AMA to answer your Qs about OLMo, our family of open language models.
🗓️ When: May 8, 8-10 am PT
🌐 Where: r/huggingface
🧠 Why: Gain insights from our expert researchers
Chat soon!
We’re excited to host an AMA to answer your Qs about OLMo, our family of open language models.
🗓️ When: May 8, 8-10 am PT
🌐 Where: r/huggingface
🧠 Why: Gain insights from our expert researchers
Chat soon!
Reposted by Jiacheng Liu
Last week we released OLMoTrace as part of #GoogleCloudNext

April 14, 2025 at 7:31 PM
Last week we released OLMoTrace as part of #GoogleCloudNext
Reposted by Jiacheng Liu

Ai2 launched a new tool where your responses from OLMo get mapped back to related training data. We're using this actively to improve our post-training data and hope many others will use it for understanding and transparency around leading language models!
Some musings:
Some musings:
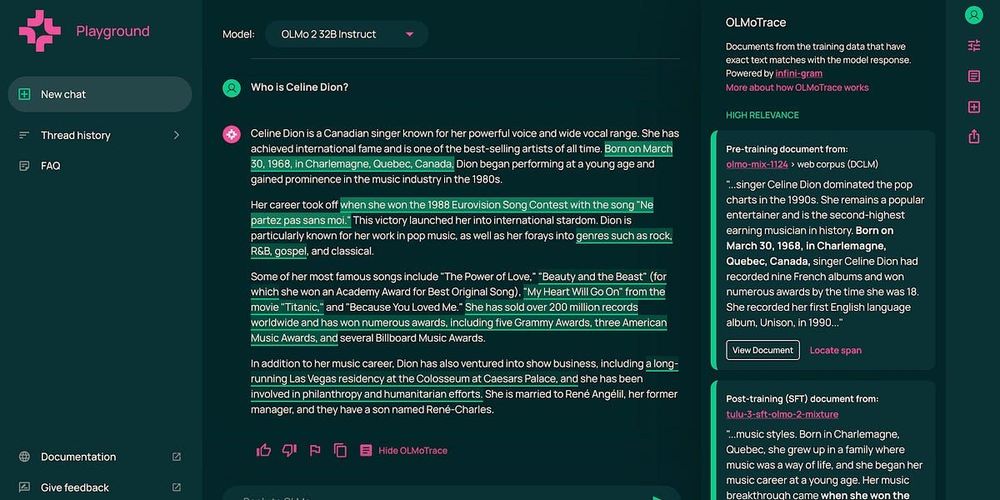
Looking at the training data
On building tools where truly open-source models can shrine (OLMo 2 32B Instruct, for today). OLMoTrace lets you poke around.
buff.ly
April 9, 2025 at 8:12 PM
Ai2 launched a new tool where your responses from OLMo get mapped back to related training data. We're using this actively to improve our post-training data and hope many others will use it for understanding and transparency around leading language models!
Some musings:
Some musings:
Reposted by Jiacheng Liu
Coming to you live from #GoogleCloudNext Day 2!
📍 Find us at the Vertex AI Model Garden inside the Google Cloud Showcase - try out OLMoTrace, and take a step inside our fully open AI ecosystem.
📍 Find us at the Vertex AI Model Garden inside the Google Cloud Showcase - try out OLMoTrace, and take a step inside our fully open AI ecosystem.




April 10, 2025 at 4:25 PM
Coming to you live from #GoogleCloudNext Day 2!
📍 Find us at the Vertex AI Model Garden inside the Google Cloud Showcase - try out OLMoTrace, and take a step inside our fully open AI ecosystem.
📍 Find us at the Vertex AI Model Garden inside the Google Cloud Showcase - try out OLMoTrace, and take a step inside our fully open AI ecosystem.
Reposted by Jiacheng Liu
"OLMoTrace is a breakthrough in AI development, setting a new standard for transparency and trust. We hope it will empower researchers, developers, and users to build with confidence—on models they can understand and trust." - CEO Ali Farhadi at tonight's chat with Karen Dahut #GoogleCloudNext

April 10, 2025 at 1:23 AM
"OLMoTrace is a breakthrough in AI development, setting a new standard for transparency and trust. We hope it will empower researchers, developers, and users to build with confidence—on models they can understand and trust." - CEO Ali Farhadi at tonight's chat with Karen Dahut #GoogleCloudNext
Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting?
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
April 9, 2025 at 1:37 PM
Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
Reposted by Jiacheng Liu
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting?
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
April 9, 2025 at 1:16 PM
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting?
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
Reposted by Jiacheng Liu
📰Google Cloud moves deeper into open source AI with Ai2 partnership:
“Many were wary of using AI models unless they had full transparency into models’ training data and could customize the models completely. Ai2’s models allow that.”
“Many were wary of using AI models unless they had full transparency into models’ training data and could customize the models completely. Ai2’s models allow that.”
April 8, 2025 at 5:50 PM
📰Google Cloud moves deeper into open source AI with Ai2 partnership:
“Many were wary of using AI models unless they had full transparency into models’ training data and could customize the models completely. Ai2’s models allow that.”
“Many were wary of using AI models unless they had full transparency into models’ training data and could customize the models completely. Ai2’s models allow that.”
As infini-gram surpasses 500 million API calls, today we're announcing two exciting updates:
1. Infini-gram is now open-source under Apache 2.0!
2. We indexed the training data of OLMo 2 models. Now you can search in the training data of these strong, fully-open LLMs.
🧵 (1/4)
1. Infini-gram is now open-source under Apache 2.0!
2. We indexed the training data of OLMo 2 models. Now you can search in the training data of these strong, fully-open LLMs.
🧵 (1/4)
April 8, 2025 at 2:50 PM
As infini-gram surpasses 500 million API calls, today we're announcing two exciting updates:
1. Infini-gram is now open-source under Apache 2.0!
2. We indexed the training data of OLMo 2 models. Now you can search in the training data of these strong, fully-open LLMs.
🧵 (1/4)
1. Infini-gram is now open-source under Apache 2.0!
2. We indexed the training data of OLMo 2 models. Now you can search in the training data of these strong, fully-open LLMs.
🧵 (1/4)
Reposted by Jiacheng Liu
Stay tuned... Wednesday, at #GoogleCloudNext and online 👀
April 7, 2025 at 6:59 PM
Stay tuned... Wednesday, at #GoogleCloudNext and online 👀
Reposted by Jiacheng Liu
Buckle your seatbelt — we've released the OLMo 2 paper to kick off 2025 🔥. Including 50+ pages on 4 crucial components of the LLM development pipeline.

January 6, 2025 at 8:28 PM
Buckle your seatbelt — we've released the OLMo 2 paper to kick off 2025 🔥. Including 50+ pages on 4 crucial components of the LLM development pipeline.
Reposted by Jiacheng Liu

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵

January 3, 2025 at 4:02 PM
kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
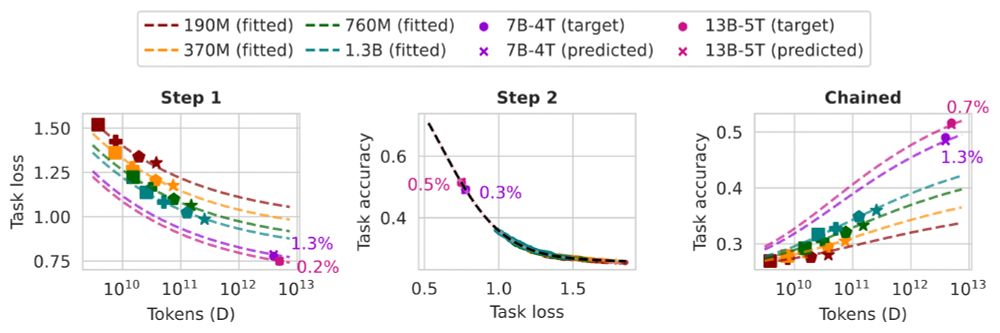
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
December 9, 2024 at 5:07 PM
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.