




Hamish Ivison
@hamishivi.bsky.social
I (try to) do NLP research. Antipodean abroad.
currently doing PhD @uwcse,
prev @usyd @ai2
🇦🇺🇨🇦🇬🇧
ivison.id.au
currently doing PhD @uwcse,
prev @usyd @ai2
🇦🇺🇨🇦🇬🇧
ivison.id.au
Wrote up some results around reproducing length control from the L1 paper in RL.
ivison.id.au/2026/02/02/r...
ivison.id.au/2026/02/02/r...

February 4, 2026 at 6:57 AM
Wrote up some results around reproducing length control from the L1 paper in RL.
ivison.id.au/2026/02/02/r...
ivison.id.au/2026/02/02/r...
Reposted by Hamish Ivison

We’re live on Reddit! Ask us Anything about our OLMo family of models. We have six of our researchers on hand to answer all your questions.

May 8, 2025 at 3:12 PM
We’re live on Reddit! Ask us Anything about our OLMo family of models. We have six of our researchers on hand to answer all your questions.
I’ll be around for this! Come ask us questions about olmo and tulu :)
Have questions? We’re an open book!
We’re excited to host an AMA to answer your Qs about OLMo, our family of open language models.
🗓️ When: May 8, 8-10 am PT
🌐 Where: r/huggingface
🧠 Why: Gain insights from our expert researchers
Chat soon!
We’re excited to host an AMA to answer your Qs about OLMo, our family of open language models.
🗓️ When: May 8, 8-10 am PT
🌐 Where: r/huggingface
🧠 Why: Gain insights from our expert researchers
Chat soon!

May 7, 2025 at 4:00 PM
I’ll be around for this! Come ask us questions about olmo and tulu :)
Excited to be back home in Australia (Syd/Melb) for most of April! Email or DM if you want to grab a coffee :)

March 27, 2025 at 4:11 PM
Excited to be back home in Australia (Syd/Melb) for most of April! Email or DM if you want to grab a coffee :)
Reposted by Hamish Ivison

@vwxyzjn.bsky.social and @hamishivi.bsky.social have uploaded intermediate checkpoints for our recent RL models at Ai2. Folks should do research into how RL finetuning is impacting the weights!
Models with it: OLMo 2 7B, 13B, 32B Instruct; Tulu 3, 3.1 8B; Tulu 3 405b
Models with it: OLMo 2 7B, 13B, 32B Instruct; Tulu 3, 3.1 8B; Tulu 3 405b
March 17, 2025 at 4:05 PM
@vwxyzjn.bsky.social and @hamishivi.bsky.social have uploaded intermediate checkpoints for our recent RL models at Ai2. Folks should do research into how RL finetuning is impacting the weights!
Models with it: OLMo 2 7B, 13B, 32B Instruct; Tulu 3, 3.1 8B; Tulu 3 405b
Models with it: OLMo 2 7B, 13B, 32B Instruct; Tulu 3, 3.1 8B; Tulu 3 405b
How well do data-selection methods work for instruction-tuning at scale?
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)

March 4, 2025 at 5:10 PM
How well do data-selection methods work for instruction-tuning at scale?
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)
Turns out, when you look at large, varied data pools, lots of recent methods lag behind simple baselines, and a simple embedding-based method (RDS) does best!
More below ⬇️ (1/8)
(1/8) Excited to share some new work: TESS 2!
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
February 20, 2025 at 6:08 PM
(1/8) Excited to share some new work: TESS 2!
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
TESS 2 is an instruction-tuned diffusion LM that can perform close to AR counterparts for general QA tasks, trained by adapting from an existing pretrained AR model.
📜 Paper: arxiv.org/abs/2502.13917
🤖 Demo: huggingface.co/spaces/hamis...
More below ⬇️
GRPO makes everything better 😌
🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!

February 12, 2025 at 5:42 PM
GRPO makes everything better 😌
Reposted by Hamish Ivison
We took our most efficient model and made an open-source iOS app📱but why?
As phones get faster, more AI will happen on device. With OLMoE, researchers, developers, and users can get a feel for this future: fully private LLMs, available anytime.
Learn more from @soldaini.net👇 youtu.be/rEK_FZE5rqQ
As phones get faster, more AI will happen on device. With OLMoE, researchers, developers, and users can get a feel for this future: fully private LLMs, available anytime.
Learn more from @soldaini.net👇 youtu.be/rEK_FZE5rqQ

Ai2 OLMoE: Fully open source, running entirely on-device
YouTube video by Ai2
youtu.be
February 11, 2025 at 2:04 PM
We took our most efficient model and made an open-source iOS app📱but why?
As phones get faster, more AI will happen on device. With OLMoE, researchers, developers, and users can get a feel for this future: fully private LLMs, available anytime.
Learn more from @soldaini.net👇 youtu.be/rEK_FZE5rqQ
As phones get faster, more AI will happen on device. With OLMoE, researchers, developers, and users can get a feel for this future: fully private LLMs, available anytime.
Learn more from @soldaini.net👇 youtu.be/rEK_FZE5rqQ
li'l holiday project from the tulu team :)
Scaling up the Tulu recipe to 405B works pretty well! We mainly see this as confirmation that open-instruct scales to large-scale training -- more exciting and ambitious things to come!
Scaling up the Tulu recipe to 405B works pretty well! We mainly see this as confirmation that open-instruct scales to large-scale training -- more exciting and ambitious things to come!

January 30, 2025 at 3:38 PM
li'l holiday project from the tulu team :)
Scaling up the Tulu recipe to 405B works pretty well! We mainly see this as confirmation that open-instruct scales to large-scale training -- more exciting and ambitious things to come!
Scaling up the Tulu recipe to 405B works pretty well! We mainly see this as confirmation that open-instruct scales to large-scale training -- more exciting and ambitious things to come!
Seems like a good time to share this: a poster from a class project diving a little more into Tulu 3's RLVR. Deepseek R1 release today shows that scaling this sort of approach up can be very very effective!

January 20, 2025 at 7:04 PM
Seems like a good time to share this: a poster from a class project diving a little more into Tulu 3's RLVR. Deepseek R1 release today shows that scaling this sort of approach up can be very very effective!
Excited to see Tulu 3 sits in between Llama 3.1 and 3.3 instruct on the chatbot arena leaderboard right now!
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124

January 8, 2025 at 5:47 PM
Excited to see Tulu 3 sits in between Llama 3.1 and 3.3 instruct on the chatbot arena leaderboard right now!
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Particularly happy it is top 20 for Math and Multi-turn prompts :)
All the details and data on how to train a model this good are right here: arxiv.org/abs/2411.15124
Reposted by Hamish Ivison

We released the OLMo 2 report! Ready for some more RL curves? 😏
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
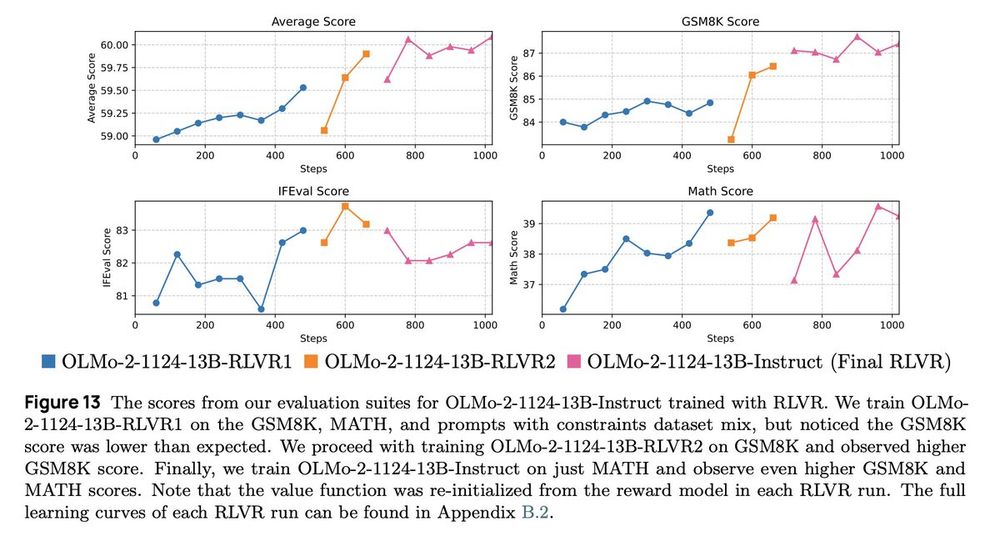
January 6, 2025 at 6:34 PM
We released the OLMo 2 report! Ready for some more RL curves? 😏
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
This time, we applied RLVR iteratively! Our initial RLVR checkpoint on the RLVR dataset mix shows a low GSM8K score, so we did another RLVR on GSM8K only and another on MATH only 😆.
And it works! A thread 🧵 1/N
More OLMo! More performance! More details!
We applied Tulu post-training to OLMo 2 as well, so you can get strong model performance AND see what your model was actually trained on.
We applied Tulu post-training to OLMo 2 as well, so you can get strong model performance AND see what your model was actually trained on.

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵

January 4, 2025 at 1:36 AM
More OLMo! More performance! More details!
We applied Tulu post-training to OLMo 2 as well, so you can get strong model performance AND see what your model was actually trained on.
We applied Tulu post-training to OLMo 2 as well, so you can get strong model performance AND see what your model was actually trained on.
Reposted by Hamish Ivison

UW News put out a Q&A about our recent work on Variational Preference Learning, a technique for personalizing Reinforcement Learning from Human Feedback (RLHF) washington.edu/news/2024/12...

Q&A: New AI training method lets systems better adjust to users’ values
University of Washington researchers created a method for training AI systems — both for large language models like ChatGPT and for robots — that can better reflect users’ diverse values. It...
washington.edu
December 18, 2024 at 9:51 PM
UW News put out a Q&A about our recent work on Variational Preference Learning, a technique for personalizing Reinforcement Learning from Human Feedback (RLHF) washington.edu/news/2024/12...
Reposted by Hamish Ivison

Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
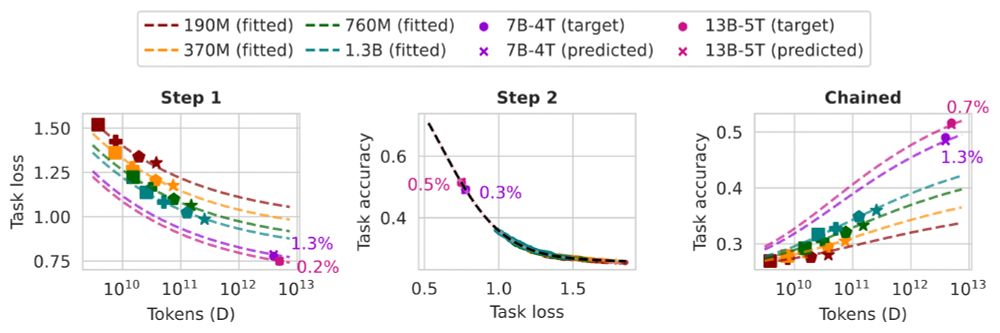
December 9, 2024 at 5:07 PM
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
New OpenAI RL finetuning API reminds me a lot of RLVR, which we used for Tülu 3 (arxiv.org/abs/2411.15124).
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
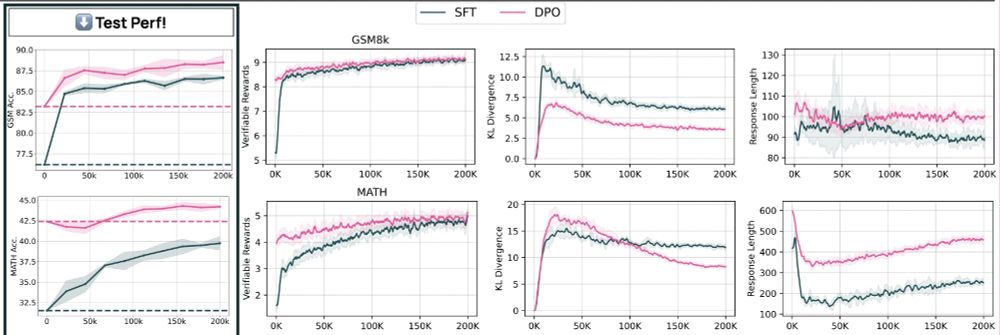
December 6, 2024 at 8:24 PM
New OpenAI RL finetuning API reminds me a lot of RLVR, which we used for Tülu 3 (arxiv.org/abs/2411.15124).
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
Using RL to train against labels is a simple idea, but very effective (>10pt gains just using GSM8k train set).
It's implemented for you to use in Open-Instruct 😉: github.com/allenai/open...
Reposted by Hamish Ivison
OpenAI announced a new RL finetuning API. You can do this on open models w the repo we used to train Tulu 3.
Expanding reinforcement learning with verifiable rewards to more domains and with better answer extraction and to more domains in our near roadmap.
https://buff.ly/3V4JEIJ
Expanding reinforcement learning with verifiable rewards to more domains and with better answer extraction and to more domains in our near roadmap.
https://buff.ly/3V4JEIJ

December 6, 2024 at 6:27 PM
OpenAI announced a new RL finetuning API. You can do this on open models w the repo we used to train Tulu 3.
Expanding reinforcement learning with verifiable rewards to more domains and with better answer extraction and to more domains in our near roadmap.
https://buff.ly/3V4JEIJ
Expanding reinforcement learning with verifiable rewards to more domains and with better answer extraction and to more domains in our near roadmap.
https://buff.ly/3V4JEIJ
Reposted by Hamish Ivison

Curious about all this inference-time scaling hype? Attend our NeurIPS tutorial: Beyond Decoding: Meta-Generation Algorithms for LLMs (Tue. 1:30)! We have a top-notch panelist lineup.
Our website: cmu-l3.github.io/neurips2024-...
Our website: cmu-l3.github.io/neurips2024-...

December 6, 2024 at 5:18 PM
Curious about all this inference-time scaling hype? Attend our NeurIPS tutorial: Beyond Decoding: Meta-Generation Algorithms for LLMs (Tue. 1:30)! We have a top-notch panelist lineup.
Our website: cmu-l3.github.io/neurips2024-...
Our website: cmu-l3.github.io/neurips2024-...
Reposted by Hamish Ivison

I’m on the academic job market this year! I’m completing my @uwcse.bsky.social @uwnlp.bsky.social Ph.D. (2025), focusing on overcoming LLM limitations like hallucinations, by building new LMs.
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵

December 4, 2024 at 1:26 PM
I’m on the academic job market this year! I’m completing my @uwcse.bsky.social @uwnlp.bsky.social Ph.D. (2025), focusing on overcoming LLM limitations like hallucinations, by building new LMs.
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
Reposted by Hamish Ivison
We're hiring another predoctoral researcher for my team at Ai2/OLMo next year. The goal of this position is to mentor and grow future academic stars of NLP/AI over 1-2 years before grad school.
This ends up being people done with BS or MS who want to continue to a PhD soon.
https://buff.ly/49nuggo
This ends up being people done with BS or MS who want to continue to a PhD soon.
https://buff.ly/49nuggo

December 3, 2024 at 11:52 PM
We're hiring another predoctoral researcher for my team at Ai2/OLMo next year. The goal of this position is to mentor and grow future academic stars of NLP/AI over 1-2 years before grad school.
This ends up being people done with BS or MS who want to continue to a PhD soon.
https://buff.ly/49nuggo
This ends up being people done with BS or MS who want to continue to a PhD soon.
https://buff.ly/49nuggo
Excited to be at #NeurIPS next week in 🇨🇦! Please reach out if you want to chat about LM post-training (Tülu!), data curation, or anything else :)
I'll be around all week, with two papers you should go check out (see image or next tweet):
I'll be around all week, with two papers you should go check out (see image or next tweet):

December 2, 2024 at 6:53 PM
Excited to be at #NeurIPS next week in 🇨🇦! Please reach out if you want to chat about LM post-training (Tülu!), data curation, or anything else :)
I'll be around all week, with two papers you should go check out (see image or next tweet):
I'll be around all week, with two papers you should go check out (see image or next tweet):
I know it doesn't know much if anything about me but this was pretty surprisingly good!

November 30, 2024 at 5:50 AM
I know it doesn't know much if anything about me but this was pretty surprisingly good!
Watching RL training curves is too addictive... begging my models to yap more and get more reward 🙏

November 29, 2024 at 7:35 AM
Watching RL training curves is too addictive... begging my models to yap more and get more reward 🙏